 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDependence between Bayesian neural network units
Nov 29, 2021
The connection between Bayesian neural networks and Gaussian processes gained a lot of attention in the last few years, with the flagship result that hidden units converge to a Gaussian process limit when the layers width tends to infinity. Underpinning this result is the fact that hidden units become independent in the infinite-width limit. Our aim is to shed some light on hidden units dependence properties in practical finite-width Bayesian neural networks. In addition to theoretical results, we assess empirically the depth and width impacts on hidden units dependence properties.
Bayesian neural network unit priors and generalized Weibull-tail property
Oct 06, 2021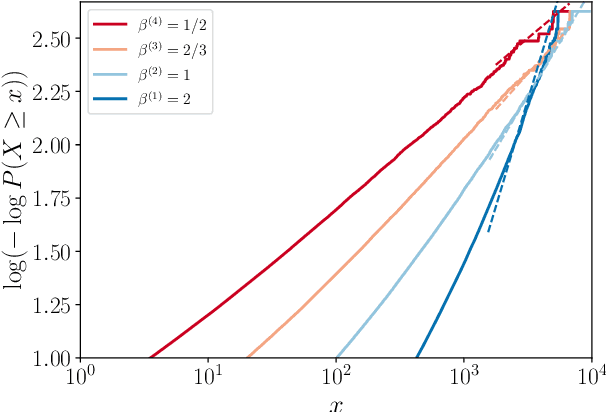
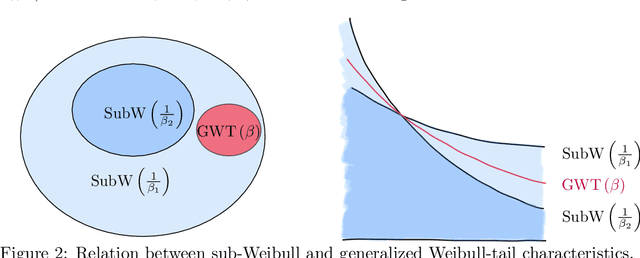
The connection between Bayesian neural networks and Gaussian processes gained a lot of attention in the last few years. Hidden units are proven to follow a Gaussian process limit when the layer width tends to infinity. Recent work has suggested that finite Bayesian neural networks may outperform their infinite counterparts because they adapt their internal representations flexibly. To establish solid ground for future research on finite-width neural networks, our goal is to study the prior induced on hidden units. Our main result is an accurate description of hidden units tails which shows that unit priors become heavier-tailed going deeper, thanks to the introduced notion of generalized Weibull-tail. This finding sheds light on the behavior of hidden units of finite Bayesian neural networks.
Auto-associative models, nonlinear Principal component analysis, manifolds and projection pursuit
Mar 31, 2011



In this paper, auto-associative models are proposed as candidates to the generalization of Principal Component Analysis. We show that these models are dedicated to the approximation of the dataset by a manifold. Here, the word "manifold" refers to the topology properties of the structure. The approximating manifold is built by a projection pursuit algorithm. At each step of the algorithm, the dimension of the manifold is incremented. Some theoretical properties are provided. In particular, we can show that, at each step of the algorithm, the mean residuals norm is not increased. Moreover, it is also established that the algorithm converges in a finite number of steps. Some particular auto-associative models are exhibited and compared to the classical PCA and some neural networks models. Implementation aspects are discussed. We show that, in numerous cases, no optimization procedure is required. Some illustrations on simulated and real data are presented.