 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian neural network unit priors and generalized Weibull-tail property
Paper and Code
Oct 06, 2021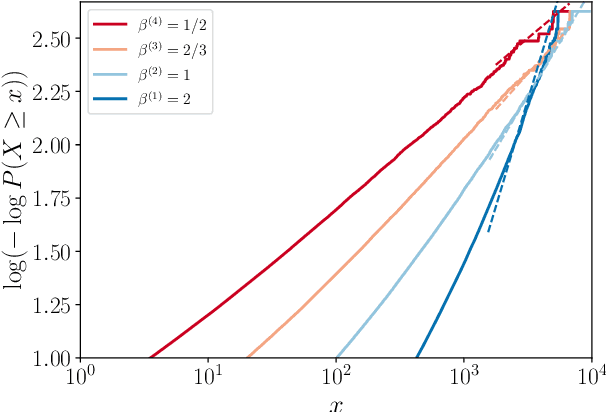
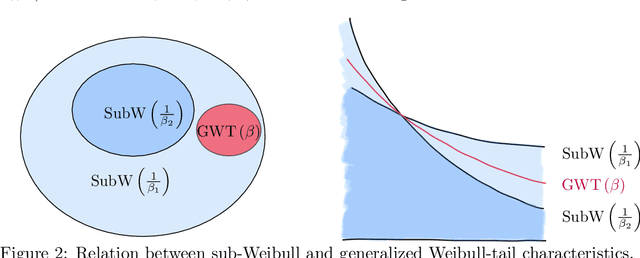
The connection between Bayesian neural networks and Gaussian processes gained a lot of attention in the last few years. Hidden units are proven to follow a Gaussian process limit when the layer width tends to infinity. Recent work has suggested that finite Bayesian neural networks may outperform their infinite counterparts because they adapt their internal representations flexibly. To establish solid ground for future research on finite-width neural networks, our goal is to study the prior induced on hidden units. Our main result is an accurate description of hidden units tails which shows that unit priors become heavier-tailed going deeper, thanks to the introduced notion of generalized Weibull-tail. This finding sheds light on the behavior of hidden units of finite Bayesian neural networks.