 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Perturbations with Cross-paradigm Transferability on Localized Crowd Counting
Mar 25, 2026State-of-the-art crowd counting and localization are primarily modeled using two paradigms: density maps and point regression. Given the field's security ramifications, there is active interest in model robustness against adversarial attacks. Recent studies have demonstrated transferability across density-map-based approaches via adversarial patches, but cross-paradigm attacks (i.e., across both density map-based models and point regression-based models) remain unexplored. We introduce a novel adversarial framework that compromises both density map and point regression architectural paradigms through a comprehensive multi-task loss optimization. For point-regression models, we employ scene-density-specific high-confidence logit suppression; for density-map approaches, we use peak-targeted density map suppression. Both are combined with model-agnostic perceptual constraints to ensure that perturbations are effective and imperceptible to the human eye. Extensive experiments demonstrate the effectiveness of our attack, achieving on average a 7X increase in Mean Absolute Error compared to clean images while maintaining competitive visual quality, and successfully transferring across seven state-of-the-art crowd models with transfer ratios ranging from 0.55 to 1.69. Our approach strikes a balance between attack effectiveness and imperceptibility compared to state-of-the-art transferable attack strategies. The source code is available at https://github.com/simurgh7/CrowdGen
Revealing the Self: Brainwave-Based Human Trait Identification
Dec 26, 2024


People exhibit unique emotional responses. In the same scenario, the emotional reactions of two individuals can be either similar or vastly different. For instance, consider one person's reaction to an invitation to smoke versus another person's response to a query about their sleep quality. The identification of these individual traits through the observation of common physical parameters opens the door to a wide range of applications, including psychological analysis, criminology, disease prediction, addiction control, and more. While there has been previous research in the fields of psychometrics, inertial sensors, computer vision, and audio analysis, this paper introduces a novel technique for identifying human traits in real time using brainwave data. To achieve this, we begin with an extensive study of brainwave data collected from 80 participants using a portable EEG headset. We also conduct a statistical analysis of the collected data utilizing box plots. Our analysis uncovers several new insights, leading us to a groundbreaking unified approach for identifying diverse human traits by leveraging machine learning techniques on EEG data. Our analysis demonstrates that this proposed solution achieves high accuracy. Moreover, we explore two deep-learning models to compare the performance of our solution. Consequently, we have developed an integrated, real-time trait identification solution using EEG data, based on the insights from our analysis. To validate our approach, we conducted a rigorous user evaluation with an additional 20 participants. The outcomes of this evaluation illustrate both high accuracy and favorable user ratings, emphasizing the robust potential of our proposed method to serve as a versatile solution for human trait identification.
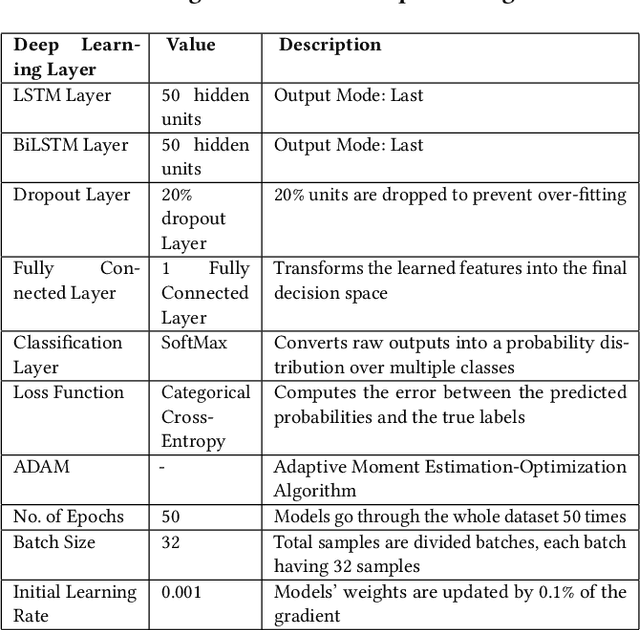
Evaluating Multiway Multilingual NMT in the Turkic Languages
Sep 13, 2021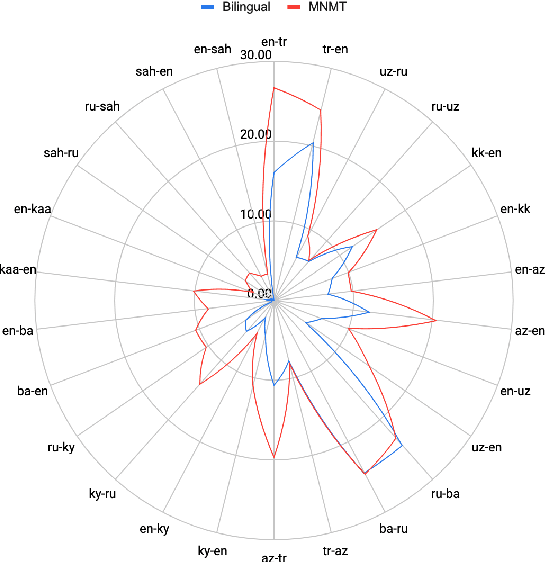

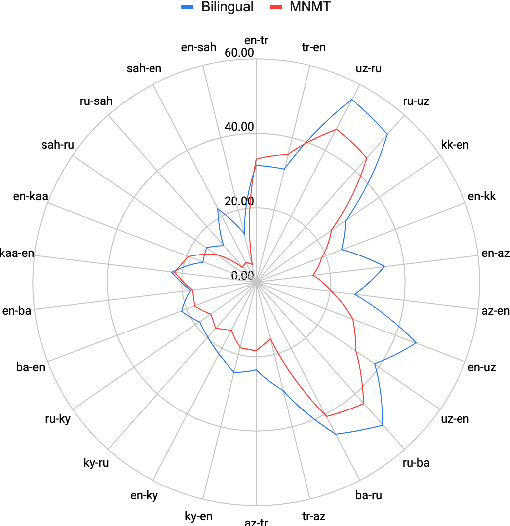
Despite the increasing number of large and comprehensive machine translation (MT) systems, evaluation of these methods in various languages has been restrained by the lack of high-quality parallel corpora as well as engagement with the people that speak these languages. In this study, we present an evaluation of state-of-the-art approaches to training and evaluating MT systems in 22 languages from the Turkic language family, most of which being extremely under-explored. First, we adopt the TIL Corpus with a few key improvements to the training and the evaluation sets. Then, we train 26 bilingual baselines as well as a multi-way neural MT (MNMT) model using the corpus and perform an extensive analysis using automatic metrics as well as human evaluations. We find that the MNMT model outperforms almost all bilingual baselines in the out-of-domain test sets and finetuning the model on a downstream task of a single pair also results in a huge performance boost in both low- and high-resource scenarios. Our attentive analysis of evaluation criteria for MT models in Turkic languages also points to the necessity for further research in this direction. We release the corpus splits, test sets as well as models to the public.
A Large-Scale Study of Machine Translation in the Turkic Languages
Sep 09, 2021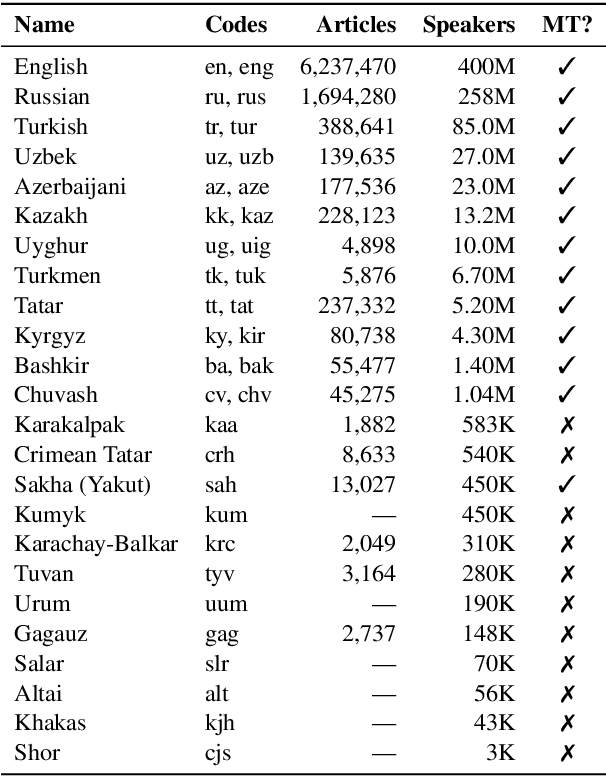
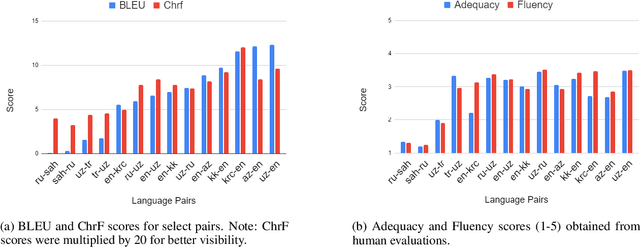
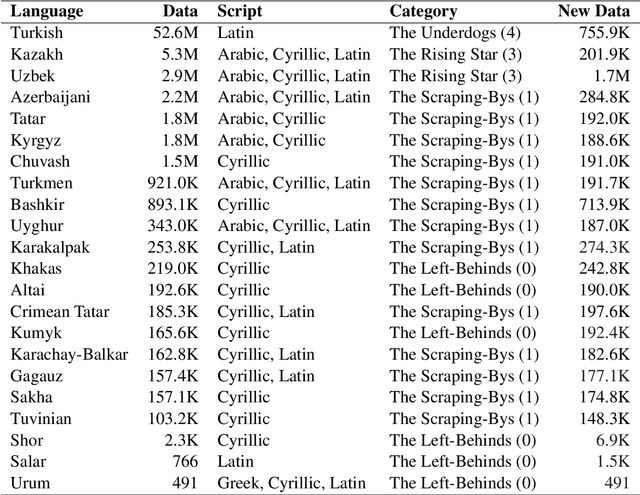

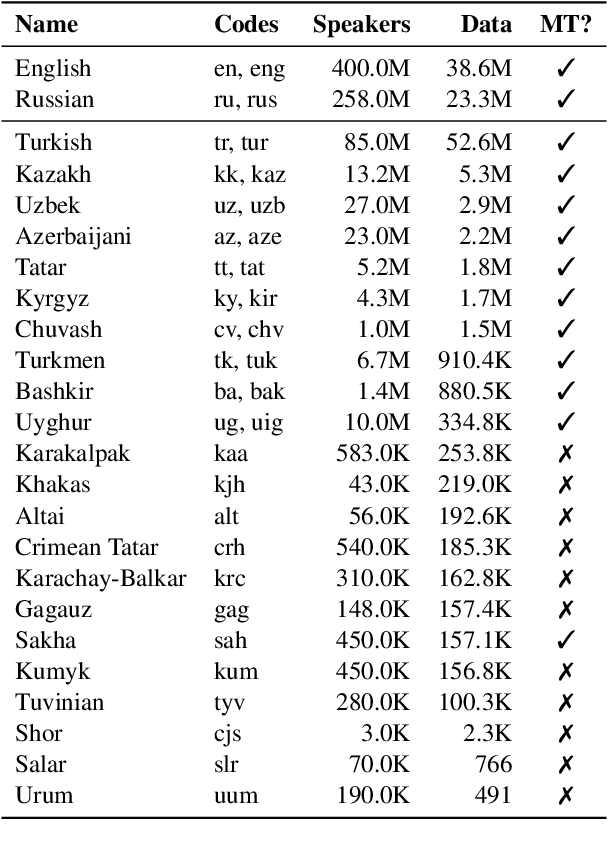
Recent advances in neural machine translation (NMT) have pushed the quality of machine translation systems to the point where they are becoming widely adopted to build competitive systems. However, there is still a large number of languages that are yet to reap the benefits of NMT. In this paper, we provide the first large-scale case study of the practical application of MT in the Turkic language family in order to realize the gains of NMT for Turkic languages under high-resource to extremely low-resource scenarios. In addition to presenting an extensive analysis that identifies the bottlenecks towards building competitive systems to ameliorate data scarcity, our study has several key contributions, including, i) a large parallel corpus covering 22 Turkic languages consisting of common public datasets in combination with new datasets of approximately 2 million parallel sentences, ii) bilingual baselines for 26 language pairs, iii) novel high-quality test sets in three different translation domains and iv) human evaluation scores. All models, scripts, and data will be released to the public.
Assessing COVID-19 Impacts on College Students via Automated Processing of Free-form Text
Dec 17, 2020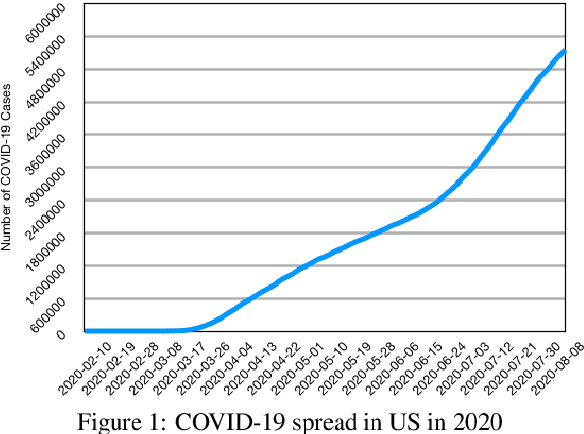


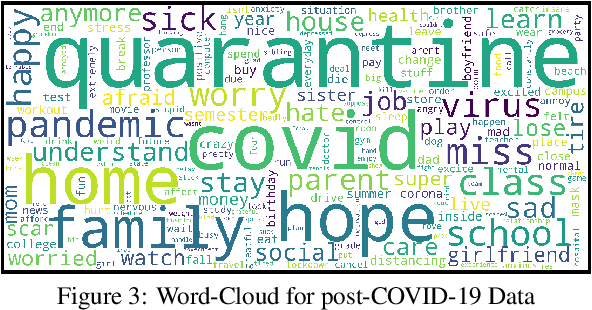
In this paper, we report experimental results on assessing the impact of COVID-19 on college students by processing free-form texts generated by them. By free-form texts, we mean textual entries posted by college students (enrolled in a four year US college) via an app specifically designed to assess and improve their mental health. Using a dataset comprising of more than 9000 textual entries from 1451 students collected over four months (split between pre and post COVID-19), and established NLP techniques, a) we assess how topics of most interest to student change between pre and post COVID-19, and b) we assess the sentiments that students exhibit in each topic between pre and post COVID-19. Our analysis reveals that topics like Education became noticeably less important to students post COVID-19, while Health became much more trending. We also found that across all topics, negative sentiment among students post COVID-19 was much higher compared to pre-COVID-19. We expect our study to have an impact on policy-makers in higher education across several spectra, including college administrators, teachers, parents, and mental health counselors.
A Framework based on Deep Neural Networks to Extract Anatomy of Mosquitoes from Images
Jul 29, 2020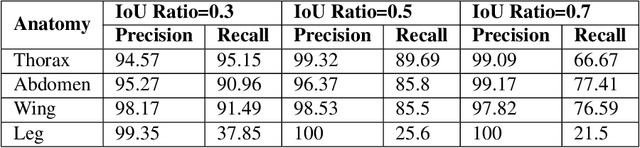
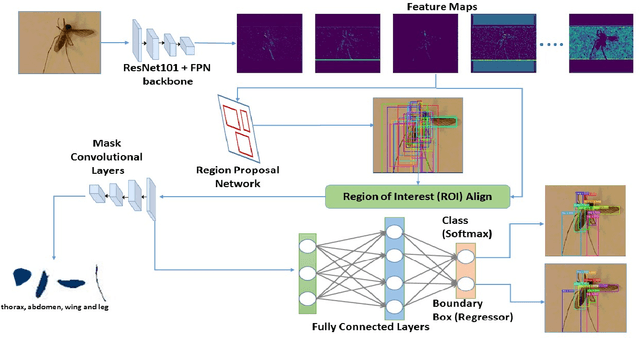
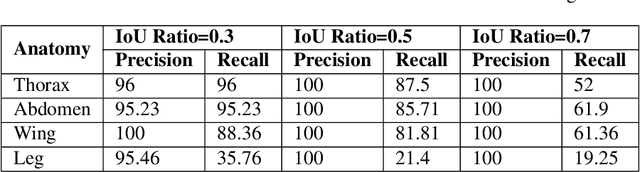

We design a framework based on Mask Region-based Convolutional Neural Network (Mask R-CNN) to automatically detect and separately extract anatomical components of mosquitoes - thorax, wings, abdomen and legs from images. Our training dataset consisted of 1500 smartphone images of nine mosquito species trapped in Florida. In the proposed technique, the first step is to detect anatomical components within a mosquito image. Then, we localize and classify the extracted anatomical components, while simultaneously adding a branch in the neural network architecture to segment pixels containing only the anatomical components. Evaluation results are favorable. To evaluate generality, we test our architecture trained only with mosquito images on bumblebee images. We again reveal favorable results, particularly in extracting wings. Our techniques in this paper have practical applications in public health, taxonomy and citizen-science efforts.
Automating the Surveillance of Mosquito Vectors from Trapped Specimens Using Computer Vision Techniques
May 25, 2020
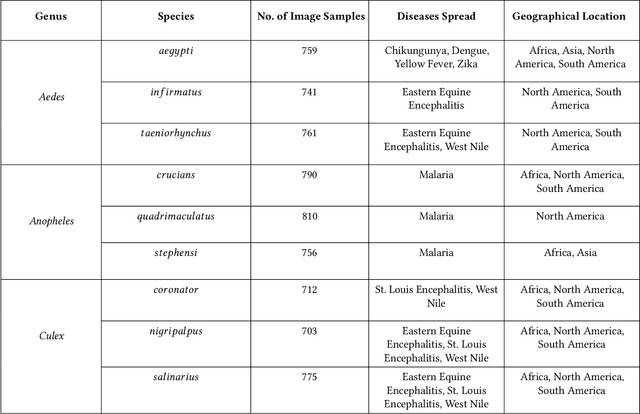

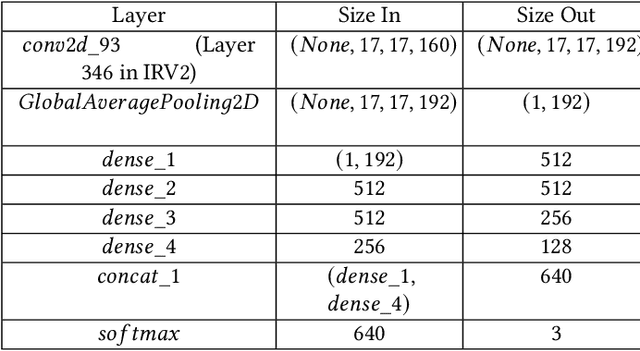
Among all animals, mosquitoes are responsible for the most deaths worldwide. Interestingly, not all types of mosquitoes spread diseases, but rather, a select few alone are competent enough to do so. In the case of any disease outbreak, an important first step is surveillance of vectors (i.e., those mosquitoes capable of spreading diseases). To do this today, public health workers lay several mosquito traps in the area of interest. Hundreds of mosquitoes will get trapped. Naturally, among these hundreds, taxonomists have to identify only the vectors to gauge their density. This process today is manual, requires complex expertise/ training, and is based on visual inspection of each trapped specimen under a microscope. It is long, stressful and self-limiting. This paper presents an innovative solution to this problem. Our technique assumes the presence of an embedded camera (similar to those in smart-phones) that can take pictures of trapped mosquitoes. Our techniques proposed here will then process these images to automatically classify the genus and species type. Our CNN model based on Inception-ResNet V2 and Transfer Learning yielded an overall accuracy of 80% in classifying mosquitoes when trained on 25,867 images of 250 trapped mosquito vector specimens captured via many smart-phone cameras. In particular, the accuracy of our model in classifying Aedes aegypti and Anopheles stephensi mosquitoes (both of which are deadly vectors) is amongst the highest. We present important lessons learned and practical impact of our techniques towards the end of the paper.