 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStream attention-based multi-array end-to-end speech recognition
Nov 12, 2018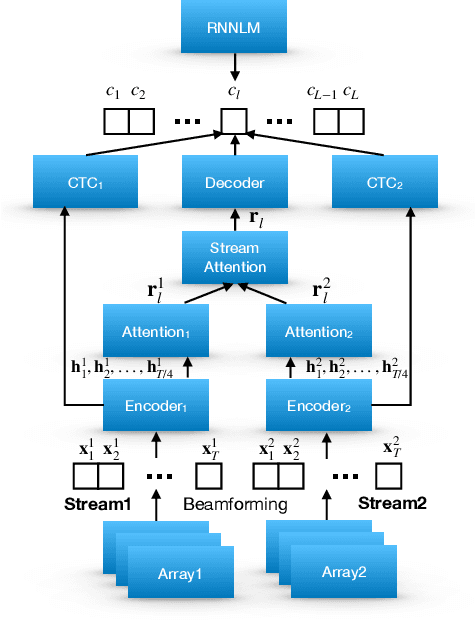
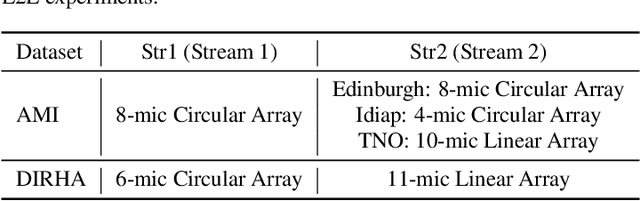

Automatic Speech Recognition (ASR) using multiple microphone arrays has achieved great success in the far-field robustness. Taking advantage of all the information that each array shares and contributes is crucial in this task. Motivated by the advances of joint Connectionist Temporal Classification (CTC)/attention mechanism in the End-to-End (E2E) ASR, a stream attention-based multi-array framework is proposed in this work. Microphone arrays, acting as information streams, are activated by separate encoders and decoded under the instruction of both CTC and attention networks. In terms of attention, a hierarchical structure is adopted. On top of the regular attention networks, stream attention is introduced to steer the decoder toward the most informative encoders. Experiments have been conducted on AMI and DIRHA multi-array corpora using the encoder-decoder architecture. Compared with the best single-array results, the proposed framework has achieved relative Word Error Rates (WERs) reduction of 3.7% and 9.7% in the two datasets, respectively, which is better than conventional strategies as well.