 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounting in the 2020s: Binned Representations and Inclusive Performance Measures for Deep Crowd Counting Approaches
Apr 10, 2022



The data distribution in popular crowd counting datasets is typically heavy tailed and discontinuous. This skew affects all stages within the pipelines of deep crowd counting approaches. Specifically, the approaches exhibit unacceptably large standard deviation wrt statistical measures (MSE, MAE). To address such concerns in a holistic manner, we make two fundamental contributions. Firstly, we modify the training pipeline to accommodate the knowledge of dataset skew. To enable principled and balanced minibatch sampling, we propose a novel smoothed Bayesian binning approach. More specifically, we propose a novel cost function which can be readily incorporated into existing crowd counting deep networks to encourage bin-aware optimization. As the second contribution, we introduce additional performance measures which are more inclusive and throw light on various comparative performance aspects of the deep networks. We also show that our binning-based modifications retain their superiority wrt the newly proposed performance measures. Overall, our contributions enable a practically useful and detail-oriented characterization of performance for crowd counting approaches.
Wisdom of (Binned) Crowds: A Bayesian Stratification Paradigm for Crowd Counting
Aug 19, 2021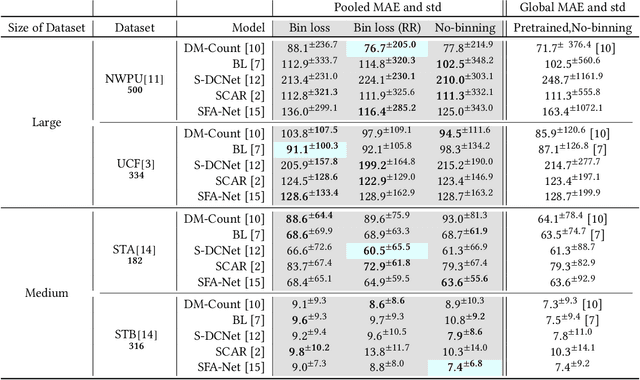
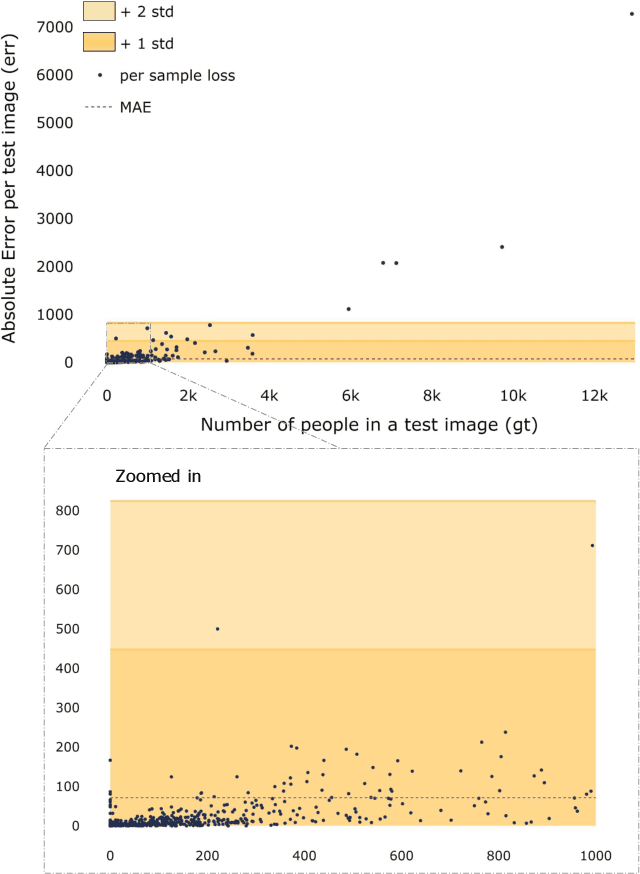

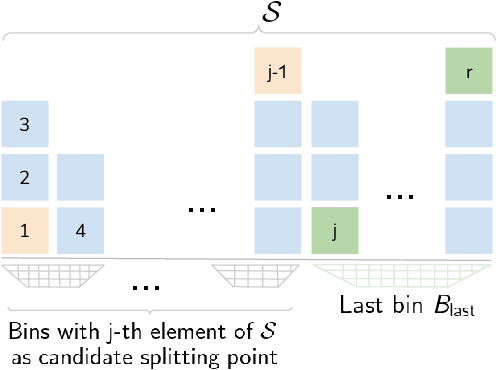
Datasets for training crowd counting deep networks are typically heavy-tailed in count distribution and exhibit discontinuities across the count range. As a result, the de facto statistical measures (MSE, MAE) exhibit large variance and tend to be unreliable indicators of performance across the count range. To address these concerns in a holistic manner, we revise processes at various stages of the standard crowd counting pipeline. To enable principled and balanced minibatch sampling, we propose a novel smoothed Bayesian sample stratification approach. We propose a novel cost function which can be readily incorporated into existing crowd counting deep networks to encourage strata-aware optimization. We analyze the performance of representative crowd counting approaches across standard datasets at per strata level and in aggregate. We analyze the performance of crowd counting approaches across standard datasets and demonstrate that our proposed modifications noticeably reduce error standard deviation. Our contributions represent a nuanced, statistically balanced and fine-grained characterization of performance for crowd counting approaches. Code, pretrained models and interactive visualizations can be viewed at our project page https://deepcount.iiit.ac.in/