 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Gender Bias of LLMs in Making Morality Judgements
Oct 13, 2024



Large Language Models (LLMs) have shown remarkable capabilities in a multitude of Natural Language Processing (NLP) tasks. However, these models are still not immune to limitations such as social biases, especially gender bias. This work investigates whether current closed and open-source LLMs possess gender bias, especially when asked to give moral opinions. To evaluate these models, we curate and introduce a new dataset GenMO (Gender-bias in Morality Opinions) comprising parallel short stories featuring male and female characters respectively. Specifically, we test models from the GPT family (GPT-3.5-turbo, GPT-3.5-turbo-instruct, GPT-4-turbo), Llama 3 and 3.1 families (8B/70B), Mistral-7B and Claude 3 families (Sonnet and Opus). Surprisingly, despite employing safety checks, all production-standard models we tested display significant gender bias with GPT-3.5-turbo giving biased opinions in 24% of the samples. Additionally, all models consistently favour female characters, with GPT showing bias in 68-85% of cases and Llama 3 in around 81-85% instances. Additionally, our study investigates the impact of model parameters on gender bias and explores real-world situations where LLMs reveal biases in moral decision-making.
Wisdom of (Binned) Crowds: A Bayesian Stratification Paradigm for Crowd Counting
Aug 19, 2021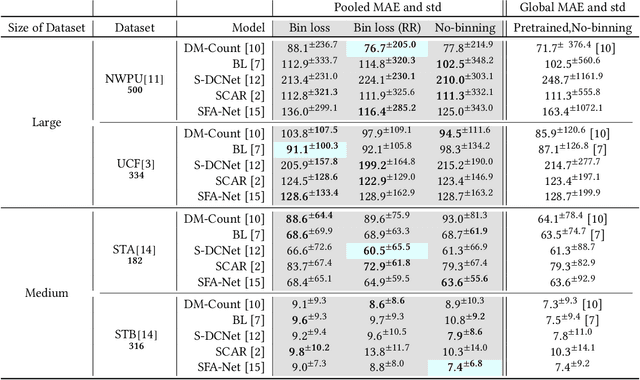
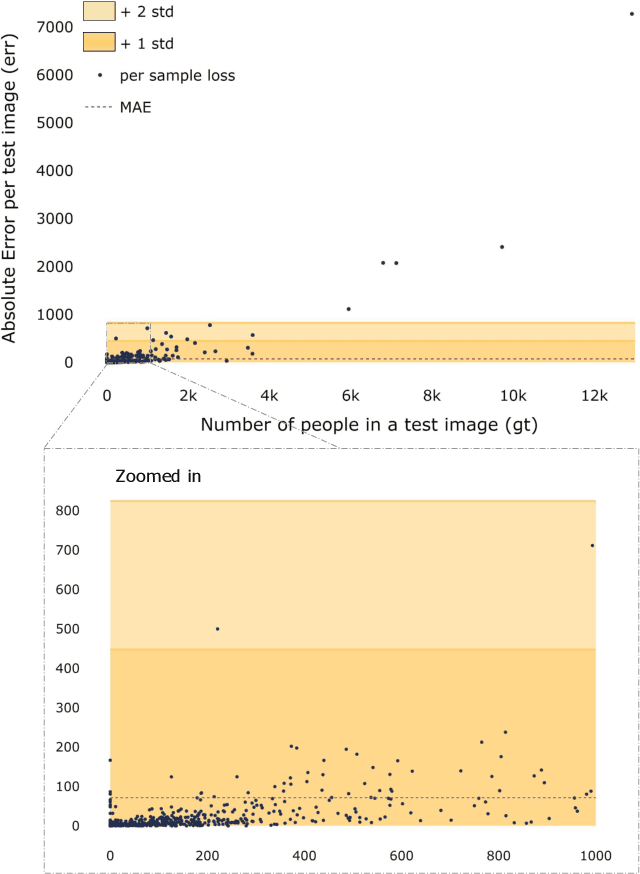

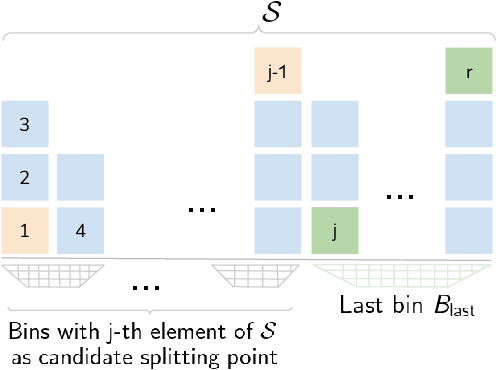
Datasets for training crowd counting deep networks are typically heavy-tailed in count distribution and exhibit discontinuities across the count range. As a result, the de facto statistical measures (MSE, MAE) exhibit large variance and tend to be unreliable indicators of performance across the count range. To address these concerns in a holistic manner, we revise processes at various stages of the standard crowd counting pipeline. To enable principled and balanced minibatch sampling, we propose a novel smoothed Bayesian sample stratification approach. We propose a novel cost function which can be readily incorporated into existing crowd counting deep networks to encourage strata-aware optimization. We analyze the performance of representative crowd counting approaches across standard datasets at per strata level and in aggregate. We analyze the performance of crowd counting approaches across standard datasets and demonstrate that our proposed modifications noticeably reduce error standard deviation. Our contributions represent a nuanced, statistically balanced and fine-grained characterization of performance for crowd counting approaches. Code, pretrained models and interactive visualizations can be viewed at our project page https://deepcount.iiit.ac.in/