 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Federated Learning with a Global Biased Optimiser
Aug 20, 2021
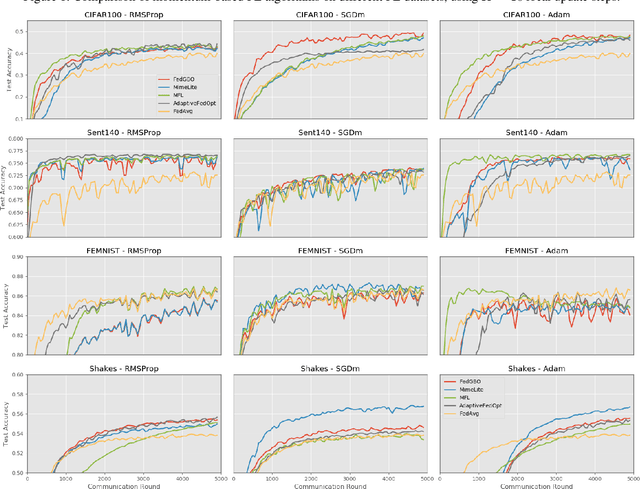


Federated Learning (FL) is a recent development in the field of machine learning that collaboratively trains models without the training data leaving client devices, in order to preserve data-privacy. In realistic settings, the total training set is distributed over clients in a highly non-Independent and Identically Distributed (non-IID) fashion, which has been shown extensively to harm FL convergence speed and final model performance. We propose a novel, generalised approach for applying adaptive optimisation techniques to FL with the Federated Global Biased Optimiser (FedGBO) algorithm. FedGBO accelerates FL by applying a set of global biased optimiser values during the local training phase of FL, which helps to reduce `client-drift' from non-IID data, whilst also benefiting from adaptive momentum/learning-rate methods. We show that the FedGBO update with a generic optimiser can be viewed as a centralised update with biased gradients and optimiser update, and use this theoretical framework to prove the convergence of FedGBO using momentum-Stochastic Gradient Descent. We also perform extensive experiments using 4 realistic benchmark FL datasets and 3 popular adaptive optimisers to compare the performance of different adaptive-FL approaches, demonstrating that FedGBO has highly competitive performance considering its low communication and computation costs, and providing highly practical insights for the use of adaptive optimisation in FL.