 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Federated Learning with Decaying Number of Local SGD Steps
May 16, 2023In Federated Learning (FL) client devices connected over the internet collaboratively train a machine learning model without sharing their private data with a central server or with other clients. The seminal Federated Averaging (FedAvg) algorithm trains a single global model by performing rounds of local training on clients followed by model averaging. FedAvg can improve the communication-efficiency of training by performing more steps of Stochastic Gradient Descent (SGD) on clients in each round. However, client data in real-world FL is highly heterogeneous, which has been extensively shown to slow model convergence and harm final performance when $K > 1$ steps of SGD are performed on clients per round. In this work we propose decaying $K$ as training progresses, which can jointly improve the final performance of the FL model whilst reducing the wall-clock time and the total computational cost of training compared to using a fixed $K$. We analyse the convergence of FedAvg with decaying $K$ for strongly-convex objectives, providing novel insights into the convergence properties, and derive three theoretically-motivated decay schedules for $K$. We then perform thorough experiments on four benchmark FL datasets (FEMNIST, CIFAR100, Sentiment140, Shakespeare) to show the real-world benefit of our approaches in terms of real-world convergence time, computational cost, and generalisation performance.
Federated Ensemble Model-based Reinforcement Learning
Sep 12, 2021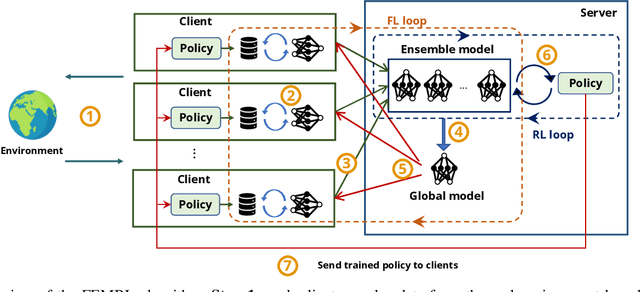
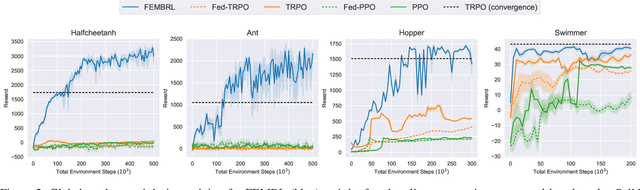
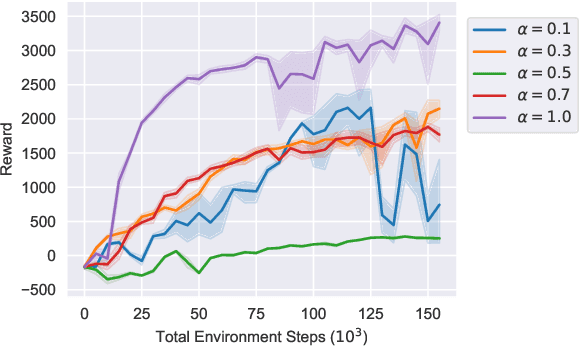
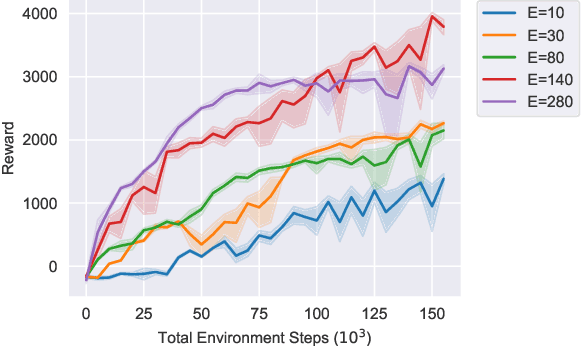
Federated learning (FL) is a privacy-preserving machine learning paradigm that enables collaborative training among geographically distributed and heterogeneous users without gathering their data. Extending FL beyond the conventional supervised learning paradigm, federated Reinforcement Learning (RL) was proposed to handle sequential decision-making problems for various privacy-sensitive applications such as autonomous driving. However, the existing federated RL algorithms directly combine model-free RL with FL, and thus generally have high sample complexity and lack theoretical guarantees. To address the above challenges, we propose a new federated RL algorithm that incorporates model-based RL and ensemble knowledge distillation into FL. Specifically, we utilise FL and knowledge distillation to create an ensemble of dynamics models from clients, and then train the policy by solely using the ensemble model without interacting with the real environment. Furthermore, we theoretically prove that the monotonic improvement of the proposed algorithm is guaranteed. Extensive experimental results demonstrate that our algorithm obtains significantly higher sample efficiency compared to federated model-free RL algorithms in the challenging continuous control benchmark environments. The results also show the impact of non-IID client data and local update steps on the performance of federated RL, validating the insights obtained from our theoretical analysis.
Accelerating Federated Learning with a Global Biased Optimiser
Aug 20, 2021
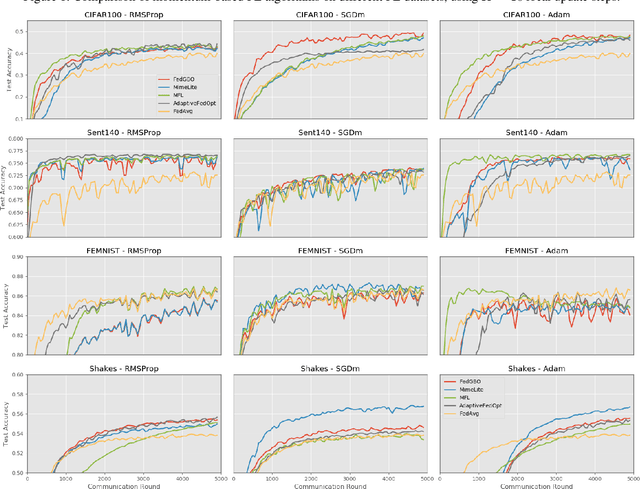


Federated Learning (FL) is a recent development in the field of machine learning that collaboratively trains models without the training data leaving client devices, in order to preserve data-privacy. In realistic settings, the total training set is distributed over clients in a highly non-Independent and Identically Distributed (non-IID) fashion, which has been shown extensively to harm FL convergence speed and final model performance. We propose a novel, generalised approach for applying adaptive optimisation techniques to FL with the Federated Global Biased Optimiser (FedGBO) algorithm. FedGBO accelerates FL by applying a set of global biased optimiser values during the local training phase of FL, which helps to reduce `client-drift' from non-IID data, whilst also benefiting from adaptive momentum/learning-rate methods. We show that the FedGBO update with a generic optimiser can be viewed as a centralised update with biased gradients and optimiser update, and use this theoretical framework to prove the convergence of FedGBO using momentum-Stochastic Gradient Descent. We also perform extensive experiments using 4 realistic benchmark FL datasets and 3 popular adaptive optimisers to compare the performance of different adaptive-FL approaches, demonstrating that FedGBO has highly competitive performance considering its low communication and computation costs, and providing highly practical insights for the use of adaptive optimisation in FL.
User-Oriented Multi-Task Federated Deep Learning for Mobile Edge Computing
Jul 17, 2020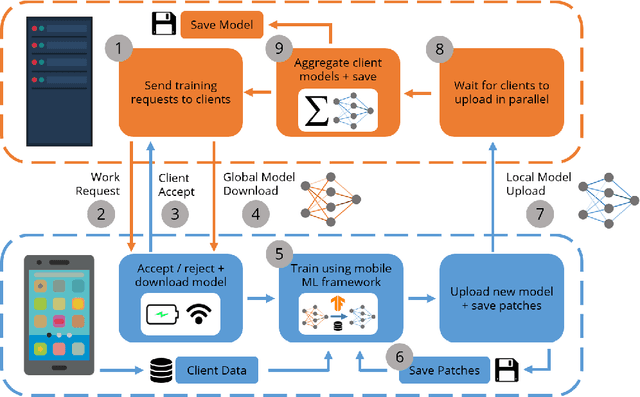
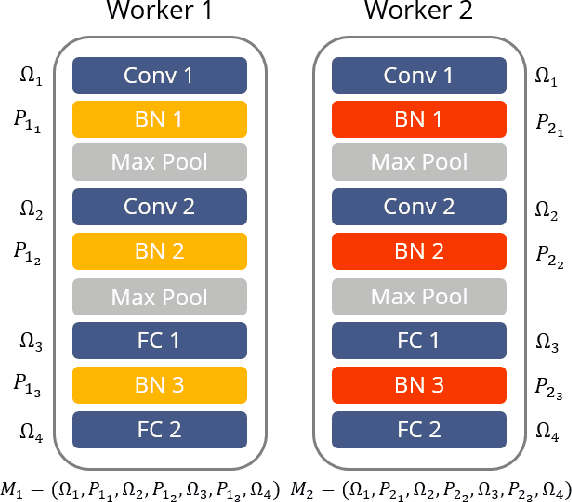
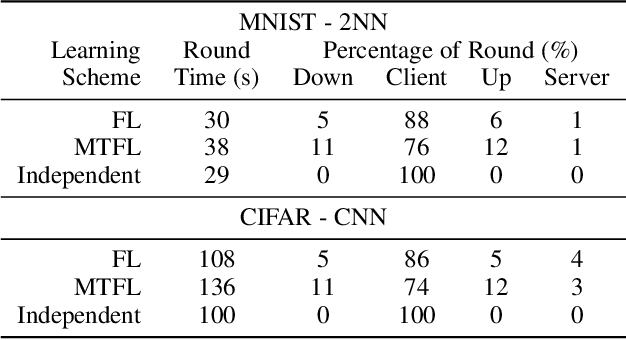
Federated Learning (FL) is a recent approach for collaboratively training Machine Learning models on mobile edge devices, without private user data leaving the devices. The popular FL algorithm, Federated Averaging (FedAvg), suffers from poor convergence speed given non-iid user data. Furthermore, most existing work on FedAvg measures central-model accuracy, but in many cases, such as user content-recommendation, improving individual User model Accuracy (UA) is the real objective. To address these issues, we propose a Multi-Task Federated Learning (MTFL) system, which converges faster than FedAvg by using distributed Adam optimization (FedAdam), and benefits UA by introducing personal, non-federated 'patch' Batch-Normalization (BN) layers into the model. Testing FedAdam on the MNIST and CIFAR10 datasets show that it converges faster (up to 5x) than FedAvg in non-iid scenarios, and experiments using MTFL on the CIFAR10 dataset show that MTFL significantly improves average UA over FedAvg, by up to 54%. We also analyse the affect that private BN patches have on the MTFL model during inference, and give evidence that MTFL strikes a better balance between regularization and convergence in FL. Finally, we test the MTFL system on a mobile edge computing testbed, showing that MTFL's convergence and UA benefits outweigh its overhead.