 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCelebV-HQ: A Large-Scale Video Facial Attributes Dataset
Jul 25, 2022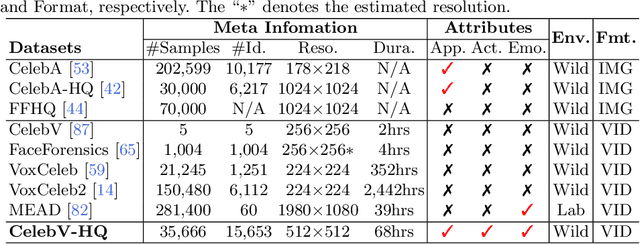
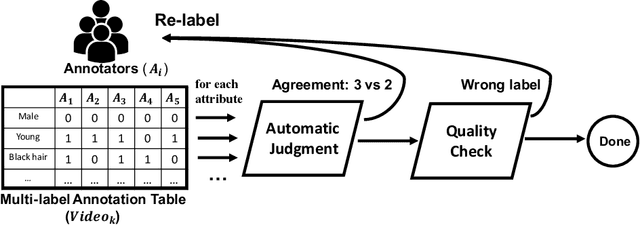

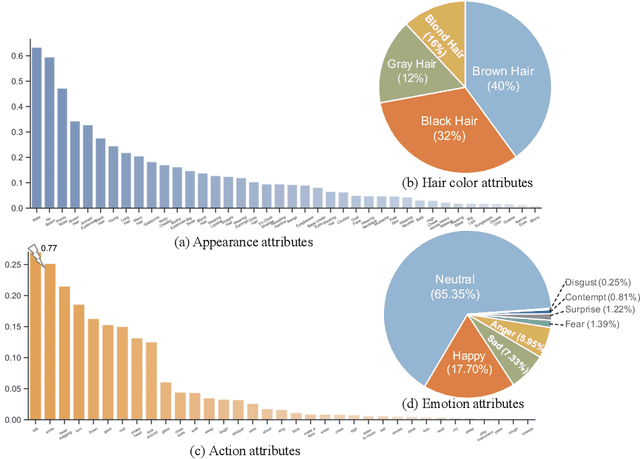
Large-scale datasets have played indispensable roles in the recent success of face generation/editing and significantly facilitated the advances of emerging research fields. However, the academic community still lacks a video dataset with diverse facial attribute annotations, which is crucial for the research on face-related videos. In this work, we propose a large-scale, high-quality, and diverse video dataset with rich facial attribute annotations, named the High-Quality Celebrity Video Dataset (CelebV-HQ). CelebV-HQ contains 35,666 video clips with the resolution of 512x512 at least, involving 15,653 identities. All clips are labeled manually with 83 facial attributes, covering appearance, action, and emotion. We conduct a comprehensive analysis in terms of age, ethnicity, brightness stability, motion smoothness, head pose diversity, and data quality to demonstrate the diversity and temporal coherence of CelebV-HQ. Besides, its versatility and potential are validated on two representative tasks, i.e., unconditional video generation and video facial attribute editing. Furthermore, we envision the future potential of CelebV-HQ, as well as the new opportunities and challenges it would bring to related research directions. Data, code, and models are publicly available. Project page: https://celebv-hq.github.io.
Constructing Locally Dense Point Clouds Using OpenSfM and ORB-SLAM2
Apr 23, 2018

This paper aims at finding a method to register two different point clouds constructed by ORB-SLAM2 and OpenSfM. To do this, we post some tags with unique textures in the scene and take videos and photos of that area. Then we take short videos of only the tags to extract their features. By matching the ORB feature of the tags with their corresponding features in the scene, it is then possible to localize the position of these tags both in point clouds constructed by ORB-SLAM2 and OpenSfM. Thus, the best transformation matrix between two point clouds can be calculated, and the two point clouds can be aligned.