 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Augmentation for Recommendation
Mar 25, 2024Graph augmentation with contrastive learning has gained significant attention in the field of recommendation systems due to its ability to learn expressive user representations, even when labeled data is limited. However, directly applying existing GCL models to real-world recommendation environments poses challenges. There are two primary issues to address. Firstly, the lack of consideration for data noise in contrastive learning can result in noisy self-supervised signals, leading to degraded performance. Secondly, many existing GCL approaches rely on graph neural network (GNN) architectures, which can suffer from over-smoothing problems due to non-adaptive message passing. To address these challenges, we propose a principled framework called GraphAug. This framework introduces a robust data augmentor that generates denoised self-supervised signals, enhancing recommender systems. The GraphAug framework incorporates a graph information bottleneck (GIB)-regularized augmentation paradigm, which automatically distills informative self-supervision information and adaptively adjusts contrastive view generation. Through rigorous experimentation on real-world datasets, we thoroughly assessed the performance of our novel GraphAug model. The outcomes consistently unveil its superiority over existing baseline methods. The source code for our model is publicly available at: https://github.com/HKUDS/GraphAug.
* 13 pages and accepted by ICDE 2024
Spatial-Temporal Graph Learning with Adversarial Contrastive Adaptation
Jun 19, 2023



Spatial-temporal graph learning has emerged as a promising solution for modeling structured spatial-temporal data and learning region representations for various urban sensing tasks such as crime forecasting and traffic flow prediction. However, most existing models are vulnerable to the quality of the generated region graph due to the inaccurate graph-structured information aggregation schema. The ubiquitous spatial-temporal data noise and incompleteness in real-life scenarios pose challenges in generating high-quality region representations. To address this challenge, we propose a new spatial-temporal graph learning model (GraphST) for enabling effective self-supervised learning. Our proposed model is an adversarial contrastive learning paradigm that automates the distillation of crucial multi-view self-supervised information for robust spatial-temporal graph augmentation. We empower GraphST to adaptively identify hard samples for better self-supervision, enhancing the representation discrimination ability and robustness. In addition, we introduce a cross-view contrastive learning paradigm to model the inter-dependencies across view-specific region representations and preserve underlying relation heterogeneity. We demonstrate the superiority of our proposed GraphST method in various spatial-temporal prediction tasks on real-life datasets. We release our model implementation via the link: \url{https://github.com/HKUDS/GraphST}.
Automated Spatio-Temporal Graph Contrastive Learning
May 06, 2023

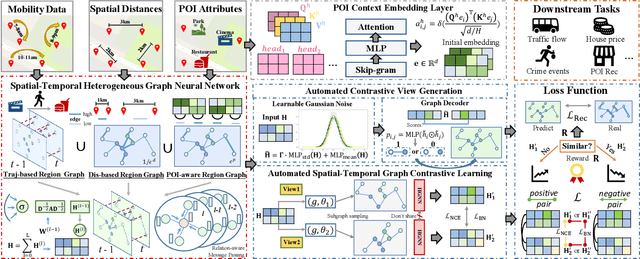

Among various region embedding methods, graph-based region relation learning models stand out, owing to their strong structure representation ability for encoding spatial correlations with graph neural networks. Despite their effectiveness, several key challenges have not been well addressed in existing methods: i) Data noise and missing are ubiquitous in many spatio-temporal scenarios due to a variety of factors. ii) Input spatio-temporal data (e.g., mobility traces) usually exhibits distribution heterogeneity across space and time. In such cases, current methods are vulnerable to the quality of the generated region graphs, which may lead to suboptimal performance. In this paper, we tackle the above challenges by exploring the Automated Spatio-Temporal graph contrastive learning paradigm (AutoST) over the heterogeneous region graph generated from multi-view data sources. Our \model\ framework is built upon a heterogeneous graph neural architecture to capture the multi-view region dependencies with respect to POI semantics, mobility flow patterns and geographical positions. To improve the robustness of our GNN encoder against data noise and distribution issues, we design an automated spatio-temporal augmentation scheme with a parameterized contrastive view generator. AutoST can adapt to the spatio-temporal heterogeneous graph with multi-view semantics well preserved. Extensive experiments for three downstream spatio-temporal mining tasks on several real-world datasets demonstrate the significant performance gain achieved by our \model\ over a variety of baselines. The code is publicly available at https://github.com/HKUDS/AutoST.