 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting interictal mapping with neurovascular coupling biomarkers by structured factorization of epileptic EEG and fMRI data
Apr 29, 2020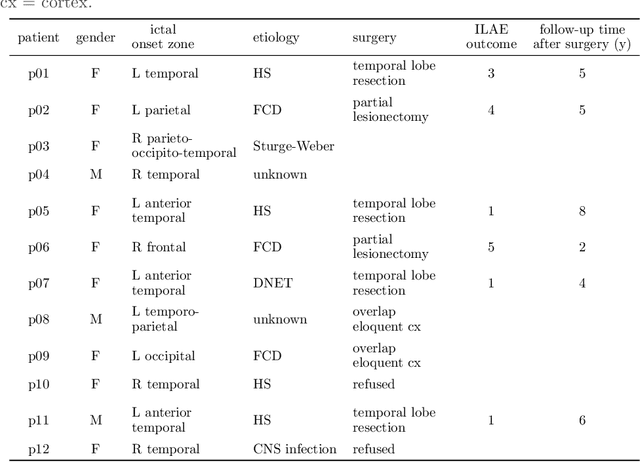



EEG-correlated fMRI analysis is widely used to detect regional blood oxygen level dependent fluctuations that are significantly synchronized to interictal epileptic discharges, which can provide evidence for localizing the ictal onset zone. However, such an asymmetrical, mass-univariate approach cannot capture the inherent, higher order structure in the EEG data, nor multivariate relations in the fMRI data, and it is nontrivial to accurately handle varying neurovascular coupling over patients and brain regions. We aim to overcome these drawbacks in a data-driven manner by means of a novel structured matrix-tensor factorization: the single-subject EEG data (represented as a third-order spectrogram tensor) and fMRI data (represented as a spatiotemporal BOLD signal matrix) are jointly decomposed into a superposition of several sources, characterized by space-time-frequency profiles. In the shared temporal mode, Toeplitz-structured factors account for a spatially specific, neurovascular `bridge' between the EEG and fMRI temporal fluctuations, capturing the hemodynamic response's variability over brain regions. We show that the extracted source signatures provide a sensitive localization of the ictal onset zone, and, moreover, that complementary localizing information can be derived from the spatial variation of the hemodynamic response. Hence, this multivariate, multimodal factorization provides two useful sets of EEG-fMRI biomarkers, which can inform the presurgical evaluation of epilepsy. We make all code required to perform the computations available.
EEG-informed attended speaker extraction from recorded speech mixtures with application in neuro-steered hearing prostheses
Jul 14, 2016

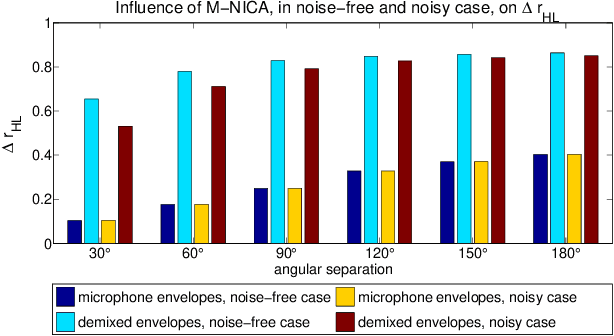
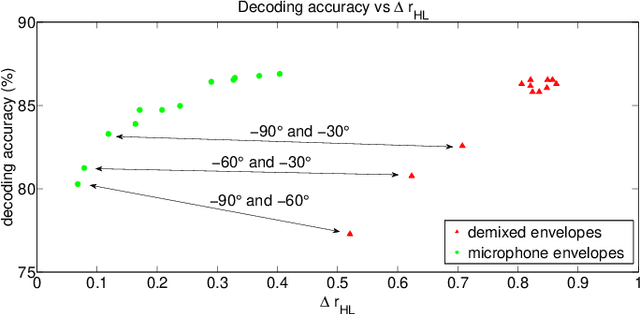
OBJECTIVE: We aim to extract and denoise the attended speaker in a noisy, two-speaker acoustic scenario, relying on microphone array recordings from a binaural hearing aid, which are complemented with electroencephalography (EEG) recordings to infer the speaker of interest. METHODS: In this study, we propose a modular processing flow that first extracts the two speech envelopes from the microphone recordings, then selects the attended speech envelope based on the EEG, and finally uses this envelope to inform a multi-channel speech separation and denoising algorithm. RESULTS: Strong suppression of interfering (unattended) speech and background noise is achieved, while the attended speech is preserved. Furthermore, EEG-based auditory attention detection (AAD) is shown to be robust to the use of noisy speech signals. CONCLUSIONS: Our results show that AAD-based speaker extraction from microphone array recordings is feasible and robust, even in noisy acoustic environments, and without access to the clean speech signals to perform EEG-based AAD. SIGNIFICANCE: Current research on AAD always assumes the availability of the clean speech signals, which limits the applicability in real settings. We have extended this research to detect the attended speaker even when only microphone recordings with noisy speech mixtures are available. This is an enabling ingredient for new brain-computer interfaces and effective filtering schemes in neuro-steered hearing prostheses. Here, we provide a first proof of concept for EEG-informed attended speaker extraction and denoising.
* This paper is published in IEEE Transactions on Biomedical Engineering (2016) and is under copyright. Please cite this paper as: S. Van Eyndhoven, T. Francart, and A. Bertrand, "EEG-informed attended speaker extraction from recorded speech mixtures with application in neuro-steered hearing prostheses", IEEE Trans. Biomedical Engineering, vol. x(x), pp. x-x, 2016