 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Training of Energy-Based Models Using Jarzynski Equality
May 30, 2023Energy-based models (EBMs) are generative models inspired by statistical physics with a wide range of applications in unsupervised learning. Their performance is best measured by the cross-entropy (CE) of the model distribution relative to the data distribution. Using the CE as the objective for training is however challenging because the computation of its gradient with respect to the model parameters requires sampling the model distribution. Here we show how results for nonequilibrium thermodynamics based on Jarzynski equality together with tools from sequential Monte-Carlo sampling can be used to perform this computation efficiently and avoid the uncontrolled approximations made using the standard contrastive divergence algorithm. Specifically, we introduce a modification of the unadjusted Langevin algorithm (ULA) in which each walker acquires a weight that enables the estimation of the gradient of the cross-entropy at any step during GD, thereby bypassing sampling biases induced by slow mixing of ULA. We illustrate these results with numerical experiments on Gaussian mixture distributions as well as the MNIST dataset. We show that the proposed approach outperforms methods based on the contrastive divergence algorithm in all the considered situations.
Wavelet Score-Based Generative Modeling
Aug 09, 2022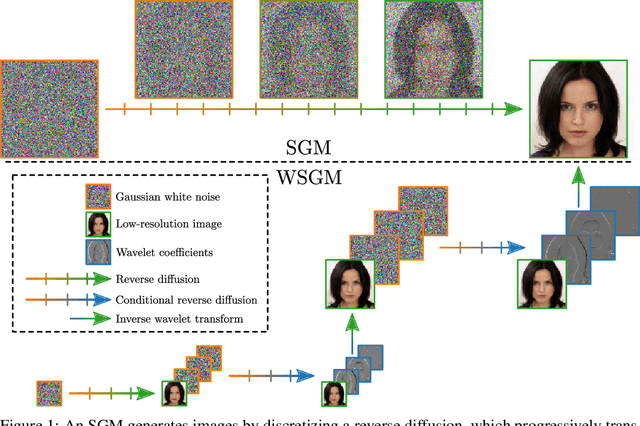
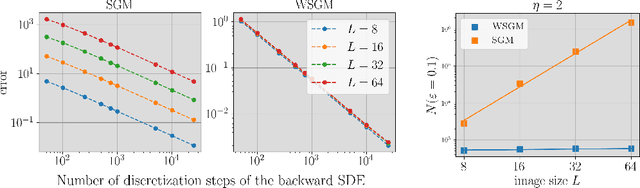
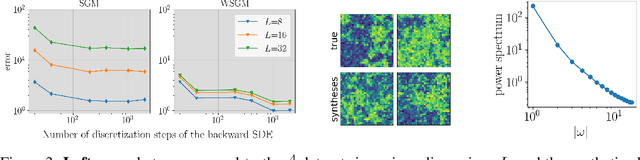
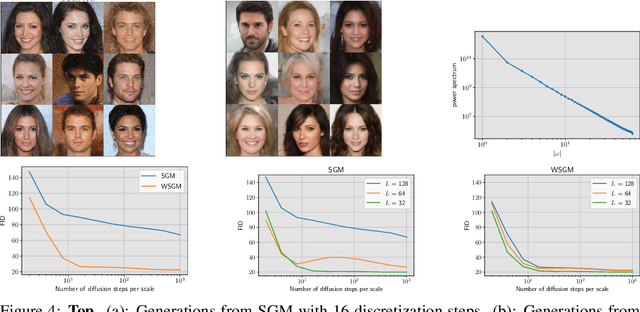
Score-based generative models (SGMs) synthesize new data samples from Gaussian white noise by running a time-reversed Stochastic Differential Equation (SDE) whose drift coefficient depends on some probabilistic score. The discretization of such SDEs typically requires a large number of time steps and hence a high computational cost. This is because of ill-conditioning properties of the score that we analyze mathematically. We show that SGMs can be considerably accelerated, by factorizing the data distribution into a product of conditional probabilities of wavelet coefficients across scales. The resulting Wavelet Score-based Generative Model (WSGM) synthesizes wavelet coefficients with the same number of time steps at all scales, and its time complexity therefore grows linearly with the image size. This is proved mathematically over Gaussian distributions, and shown numerically over physical processes at phase transition and natural image datasets.
A simpler spectral approach for clustering in directed networks
Feb 05, 2021
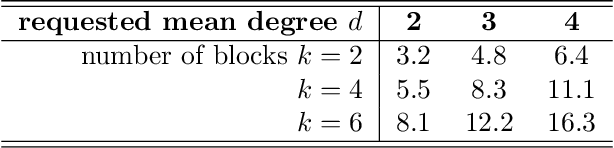


We study the task of clustering in directed networks. We show that using the eigenvalue/eigenvector decomposition of the adjacency matrix is simpler than all common methods which are based on a combination of data regularization and SVD truncation, and works well down to the very sparse regime where the edge density has constant order. Our analysis is based on a Master Theorem describing sharp asymptotics for isolated eigenvalues/eigenvectors of sparse, non-symmetric matrices with independent entries. We also describe the limiting distribution of the entries of these eigenvectors; in the task of digraph clustering with spectral embeddings, we provide numerical evidence for the superiority of Gaussian Mixture clustering over the widely used k-means algorithm.