 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved EEG Event Classification Using Differential Energy
Jan 03, 2018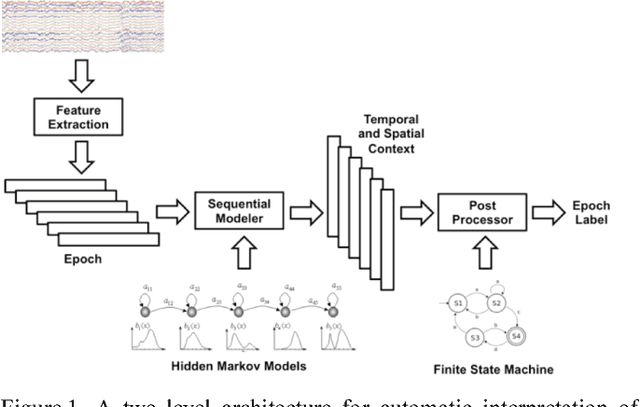
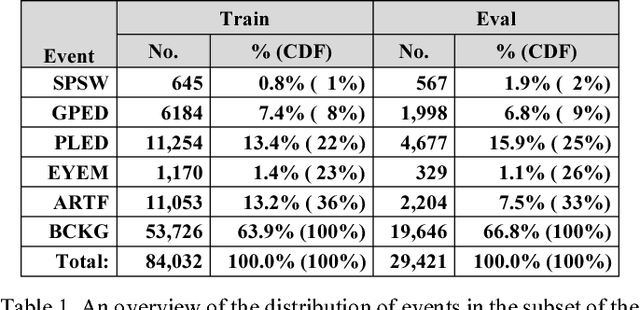
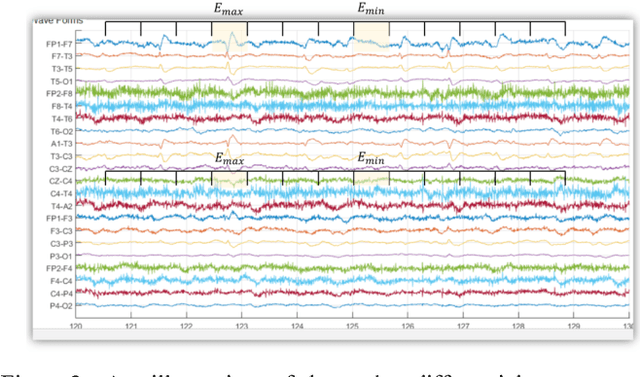
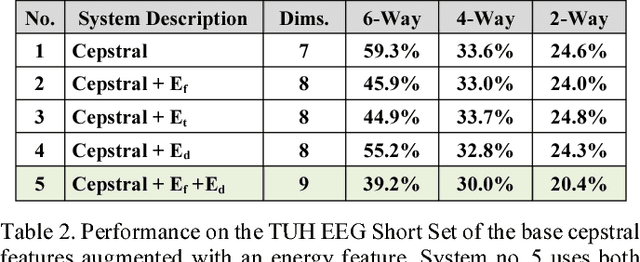
Feature extraction for automatic classification of EEG signals typically relies on time frequency representations of the signal. Techniques such as cepstral-based filter banks or wavelets are popular analysis techniques in many signal processing applications including EEG classification. In this paper, we present a comparison of a variety of approaches to estimating and postprocessing features. To further aid in discrimination of periodic signals from aperiodic signals, we add a differential energy term. We evaluate our approaches on the TUH EEG Corpus, which is the largest publicly available EEG corpus and an exceedingly challenging task due to the clinical nature of the data. We demonstrate that a variant of a standard filter bank-based approach, coupled with first and second derivatives, provides a substantial reduction in the overall error rate. The combination of differential energy and derivatives produces a 24% absolute reduction in the error rate and improves our ability to discriminate between signal events and background noise. This relatively simple approach proves to be comparable to other popular feature extraction approaches such as wavelets, but is much more computationally efficient.
* Published in IEEE Signal Processing in Medicine and Biology Symposium. Philadelphia, Pennsylvania, USA
Semi-automated Annotation of Signal Events in Clinical EEG Data
Jan 03, 2018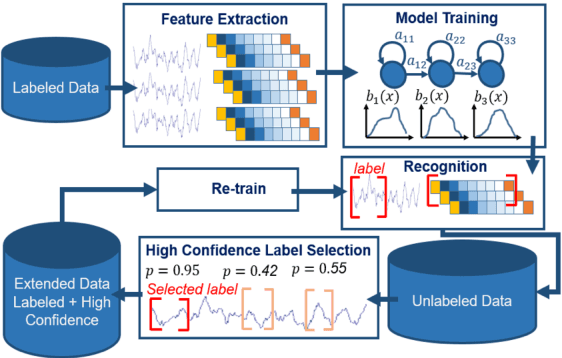
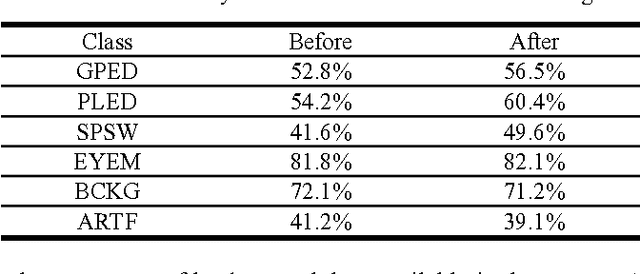
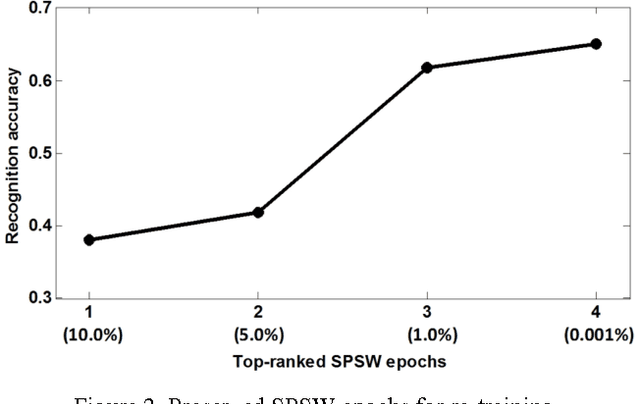
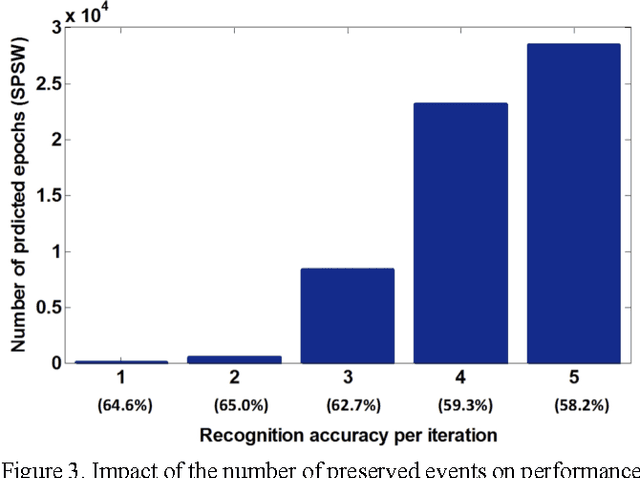
To be effective, state of the art machine learning technology needs large amounts of annotated data. There are numerous compelling applications in healthcare that can benefit from high performance automated decision support systems provided by deep learning technology, but they lack the comprehensive data resources required to apply sophisticated machine learning models. Further, for economic reasons, it is very difficult to justify the creation of large annotated corpora for these applications. Hence, automated annotation techniques become increasingly important. In this study, we investigated the effectiveness of using an active learning algorithm to automatically annotate a large EEG corpus. The algorithm is designed to annotate six types of EEG events. Two model training schemes, namely threshold-based and volume-based, are evaluated. In the threshold-based scheme the threshold of confidence scores is optimized in the initial training iteration, whereas for the volume-based scheme only a certain amount of data is preserved after each iteration. Recognition performance is improved 2% absolute and the system is capable of automatically annotating previously unlabeled data. Given that the interpretation of clinical EEG data is an exceedingly difficult task, this study provides some evidence that the proposed method is a viable alternative to expensive manual annotation.
* Published in IEEE Signal Processing in Medicine and Biology Symposium. Philadelphia, Pennsylvania, USA
An Analysis of Two Common Reference Points for EEGs
Jan 03, 2018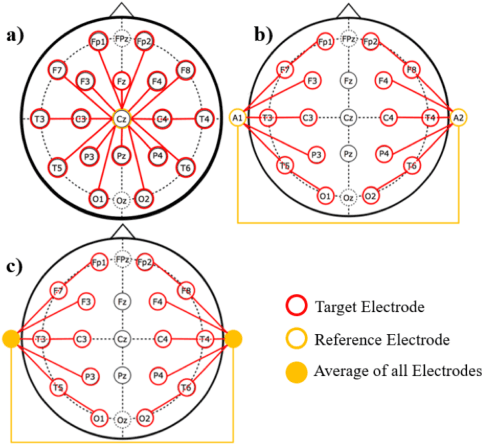
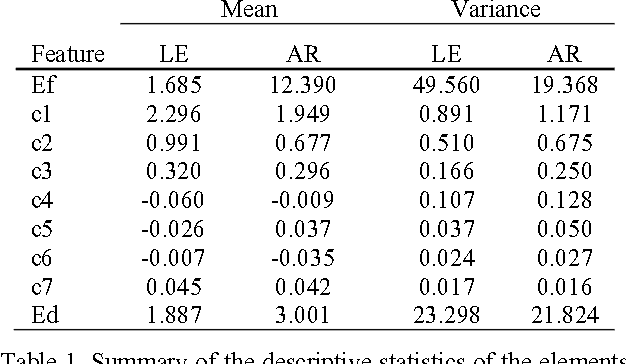
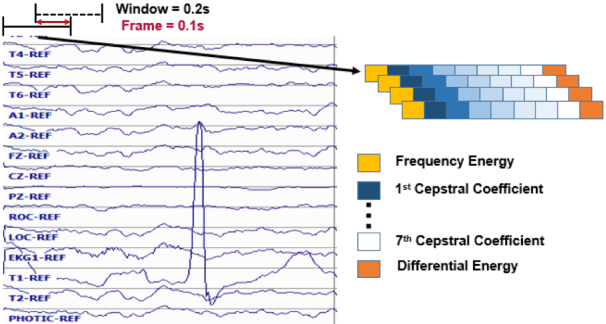
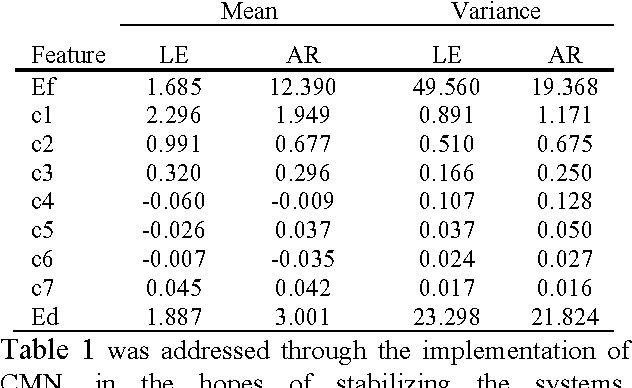
Clinical electroencephalographic (EEG) data varies significantly depending on a number of operational conditions (e.g., the type and placement of electrodes, the type of electrical grounding used). This investigation explores the statistical differences present in two different referential montages: Linked Ear (LE) and Averaged Reference (AR). Each of these accounts for approximately 45% of the data in the TUH EEG Corpus. In this study, we explore the impact this variability has on machine learning performance. We compare the statistical properties of features generated using these two montages, and explore the impact of performance on our standard Hidden Markov Model (HMM) based classification system. We show that a system trained on LE data significantly outperforms one trained only on AR data (77.2% vs. 61.4%). We also demonstrate that performance of a system trained on both data sets is somewhat compromised (71.4% vs. 77.2%). A statistical analysis of the data suggests that mean, variance and channel normalization should be considered. However, cepstral mean subtraction failed to produce an improvement in performance, suggesting that the impact of these statistical differences is subtler.
* Published In IEEE Signal Processing in Medicine and Biology Symposium. Philadelphia, Pennsylvania, USA
The Temple University Hospital Seizure Detection Corpus
Jan 03, 2018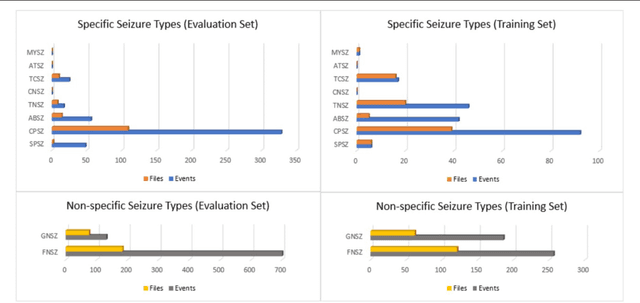
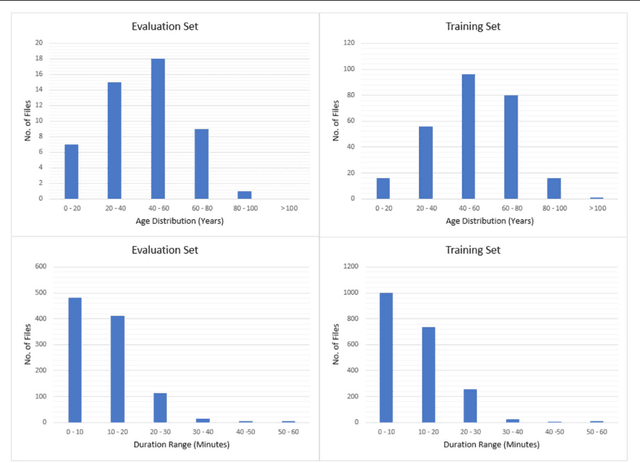
We introduce the TUH EEG Seizure Corpus (TUSZ), which is the largest open source corpus of its type, and represents an accurate characterization of clinical conditions. In this paper, we describe the techniques used to develop TUSZ, evaluate their effectiveness, and present some descriptive statistics on the resulting corpus.