 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Two Common Reference Points for EEGs
Paper and Code
Jan 03, 2018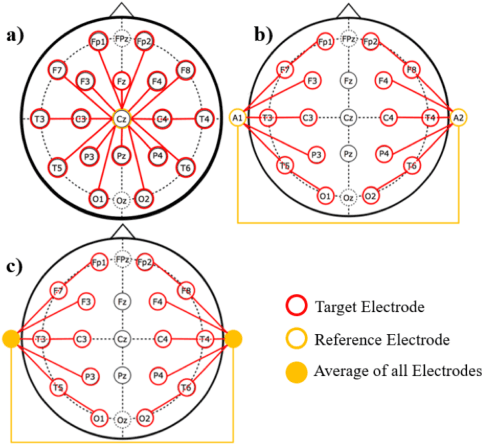
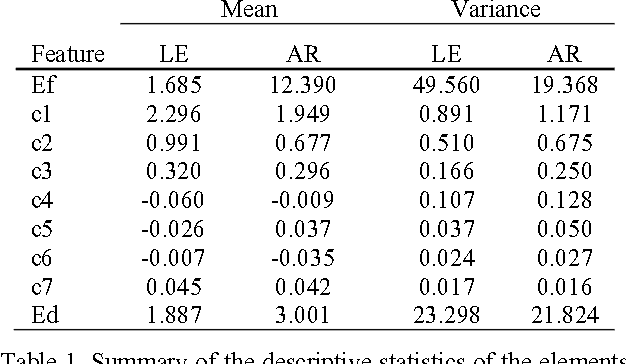
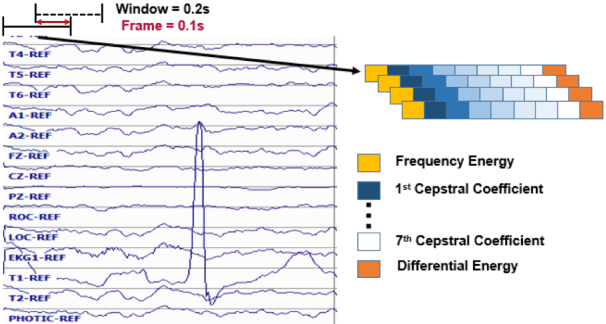
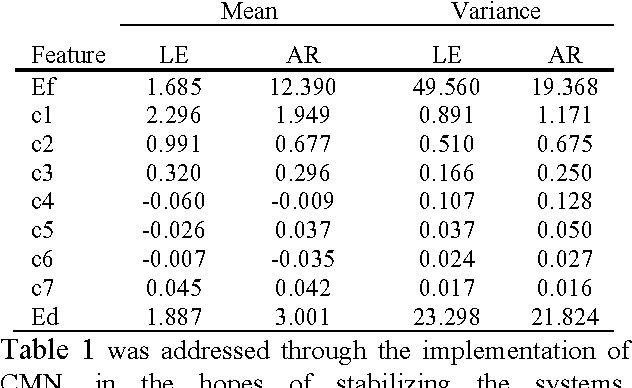
Clinical electroencephalographic (EEG) data varies significantly depending on a number of operational conditions (e.g., the type and placement of electrodes, the type of electrical grounding used). This investigation explores the statistical differences present in two different referential montages: Linked Ear (LE) and Averaged Reference (AR). Each of these accounts for approximately 45% of the data in the TUH EEG Corpus. In this study, we explore the impact this variability has on machine learning performance. We compare the statistical properties of features generated using these two montages, and explore the impact of performance on our standard Hidden Markov Model (HMM) based classification system. We show that a system trained on LE data significantly outperforms one trained only on AR data (77.2% vs. 61.4%). We also demonstrate that performance of a system trained on both data sets is somewhat compromised (71.4% vs. 77.2%). A statistical analysis of the data suggests that mean, variance and channel normalization should be considered. However, cepstral mean subtraction failed to produce an improvement in performance, suggesting that the impact of these statistical differences is subtler.