 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Corpus Size Requirements for Training and Evaluating Depression Risk Models Using Spoken Language
Dec 31, 2024


Mental health risk prediction is a growing field in the speech community, but many studies are based on small corpora. This study illustrates how variations in test and train set sizes impact performance in a controlled study. Using a corpus of over 65K labeled data points, results from a fully crossed design of different train/test size combinations are provided. Two model types are included: one based on language and the other on speech acoustics. Both use methods current in this domain. An age-mismatched test set was also included. Results show that (1) test sizes below 1K samples gave noisy results, even for larger training set sizes; (2) training set sizes of at least 2K were needed for stable results; (3) NLP and acoustic models behaved similarly with train/test size variations, and (4) the mismatched test set showed the same patterns as the matched test set. Additional factors are discussed, including label priors, model strength and pre-training, unique speakers, and data lengths. While no single study can specify exact size requirements, results demonstrate the need for appropriately sized train and test sets for future studies of mental health risk prediction from speech and language.
Optimizing Speech-Input Length for Speaker-Independent Depression Classification
Dec 31, 2024



Machine learning models for speech-based depression classification offer promise for health care applications. Despite growing work on depression classification, little is understood about how the length of speech-input impacts model performance. We analyze results for speaker-independent depression classification using a corpus of over 1400 hours of speech from a human-machine health screening application. We examine performance as a function of response input length for two NLP systems that differ in overall performance. Results for both systems show that performance depends on natural length, elapsed length, and ordering of the response within a session. Systems share a minimum length threshold, but differ in a response saturation threshold, with the latter higher for the better system. At saturation it is better to pose a new question to the speaker, than to continue the current response. These and additional reported results suggest how applications can be better designed to both elicit and process optimal input lengths for depression classification.
Depression and Anxiety Prediction Using Deep Language Models and Transfer Learning
Dec 30, 2024Digital screening and monitoring applications can aid providers in the management of behavioral health conditions. We explore deep language models for detecting depression, anxiety, and their co-occurrence from conversational speech collected during 16k user interactions with an application. Labels come from PHQ-8 and GAD-7 results also collected by the application. We find that results for binary classification range from 0.86 to 0.79 AUC, depending on condition and co-occurrence. Best performance is achieved when a user has either both or neither condition, and we show that this result is not attributable to data skew. Finally, we find evidence suggesting that underlying word sequence cues may be more salient for depression than for anxiety.
Cross-Demographic Portability of Deep NLP-Based Depression Models
Dec 26, 2024



Deep learning models are rapidly gaining interest for real-world applications in behavioral health. An important gap in current literature is how well such models generalize over different populations. We study Natural Language Processing (NLP) based models to explore portability over two different corpora highly mismatched in age. The first and larger corpus contains younger speakers. It is used to train an NLP model to predict depression. When testing on unseen speakers from the same age distribution, this model performs at AUC=0.82. We then test this model on the second corpus, which comprises seniors from a retirement community. Despite the large demographic differences in the two corpora, we saw only modest degradation in performance for the senior-corpus data, achieving AUC=0.76. Interestingly, in the senior population, we find AUC=0.81 for the subset of patients whose health state is consistent over time. Implications for demographic portability of speech-based applications are discussed.
Speech-Based Depression Prediction Using Encoder-Weight-Only Transfer Learning and a Large Corpus
Dec 22, 2024



Speech-based algorithms have gained interest for the management of behavioral health conditions such as depression. We explore a speech-based transfer learning approach that uses a lightweight encoder and that transfers only the encoder weights, enabling a simplified run-time model. Our study uses a large data set containing roughly two orders of magnitude more speakers and sessions than used in prior work. The large data set enables reliable estimation of improvement from transfer learning. Results for the prediction of PHQ-8 labels show up to 27% relative performance gains for binary classification; these gains are statistically significant with a p-value close to zero. Improvements were also found for regression. Additionally, the gain from transfer learning does not appear to require strong source task performance. Results suggest that this approach is flexible and offers promise for efficient implementation.
Improved EEG Event Classification Using Differential Energy
Jan 03, 2018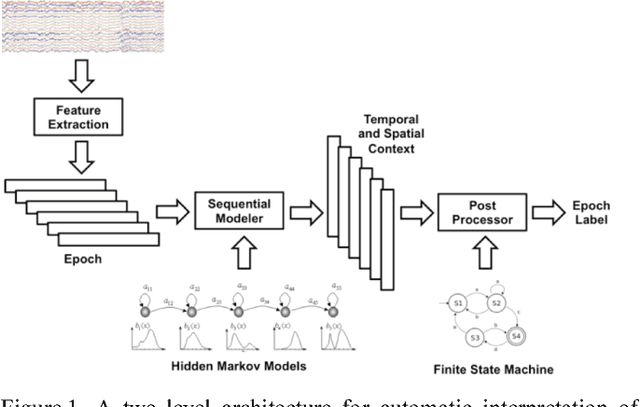
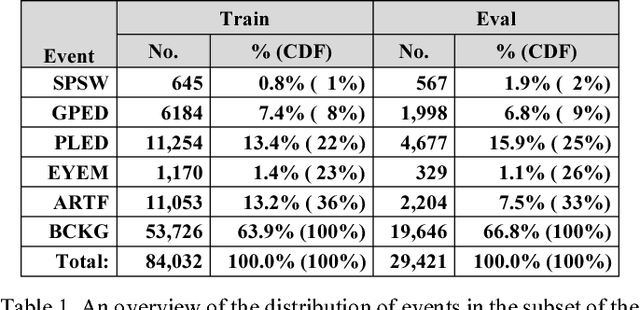
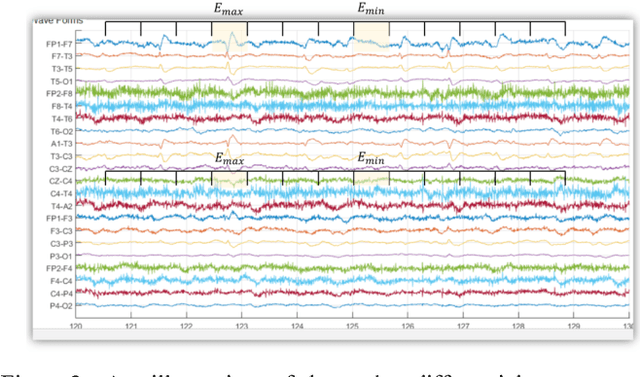
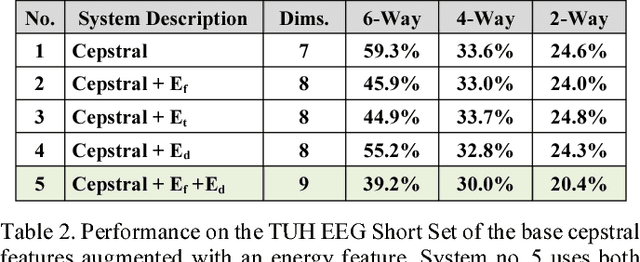
Feature extraction for automatic classification of EEG signals typically relies on time frequency representations of the signal. Techniques such as cepstral-based filter banks or wavelets are popular analysis techniques in many signal processing applications including EEG classification. In this paper, we present a comparison of a variety of approaches to estimating and postprocessing features. To further aid in discrimination of periodic signals from aperiodic signals, we add a differential energy term. We evaluate our approaches on the TUH EEG Corpus, which is the largest publicly available EEG corpus and an exceedingly challenging task due to the clinical nature of the data. We demonstrate that a variant of a standard filter bank-based approach, coupled with first and second derivatives, provides a substantial reduction in the overall error rate. The combination of differential energy and derivatives produces a 24% absolute reduction in the error rate and improves our ability to discriminate between signal events and background noise. This relatively simple approach proves to be comparable to other popular feature extraction approaches such as wavelets, but is much more computationally efficient.
* Published in IEEE Signal Processing in Medicine and Biology Symposium. Philadelphia, Pennsylvania, USA