 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-AVDT: Audio-Visual Cross-Attention for Robust Deepfake Detection
Mar 09, 2026The surge of highly realistic synthetic videos produced by contemporary generative systems has significantly increased the risk of malicious use, challenging both humans and existing detectors. Against this backdrop, we take a generator-side view and observe that internal cross-attention mechanisms in these models encode fine-grained speech-motion alignment, offering useful correspondence cues for forgery detection. Building on this insight, we propose X-AVDT, a robust and generalizable deepfake detector that probes generator-internal audio-visual signals accessed via DDIM inversion to expose these cues. X-AVDT extracts two complementary signals: (i) a video composite capturing inversion-induced discrepancies, and (ii) an audio-visual cross-attention feature reflecting modality alignment enforced during generation. To enable faithful cross-generator evaluation, we further introduce MMDF, a new multimodal deepfake dataset spanning diverse manipulation types and rapidly evolving synthesis paradigms, including GANs, diffusion, and flow-matching. Extensive experiments demonstrate that X-AVDT achieves leading performance on MMDF and generalizes strongly to external benchmarks and unseen generators, outperforming existing methods with accuracy improved by 13.1%. Our findings highlight the importance of leveraging internal audio-visual consistency cues for robustness to future generators in deepfake detection.
Deep Learning Based Facial Retargeting Using Local Patches
Jan 13, 2026In the era of digital animation, the quest to produce lifelike facial animations for virtual characters has led to the development of various retargeting methods. While the retargeting facial motion between models of similar shapes has been very successful, challenges arise when the retargeting is performed on stylized or exaggerated 3D characters that deviate significantly from human facial structures. In this scenario, it is important to consider the target character's facial structure and possible range of motion to preserve the semantics assumed by the original facial motions after the retargeting. To achieve this, we propose a local patch-based retargeting method that transfers facial animations captured in a source performance video to a target stylized 3D character. Our method consists of three modules. The Automatic Patch Extraction Module extracts local patches from the source video frame. These patches are processed through the Reenactment Module to generate correspondingly re-enacted target local patches. The Weight Estimation Module calculates the animation parameters for the target character at every frame for the creation of a complete facial animation sequence. Extensive experiments demonstrate that our method can successfully transfer the semantic meaning of source facial expressions to stylized characters with considerable variations in facial feature proportion.
* Eurographics 25
Neural Face Skinning for Mesh-agnostic Facial Expression Cloning
May 28, 2025
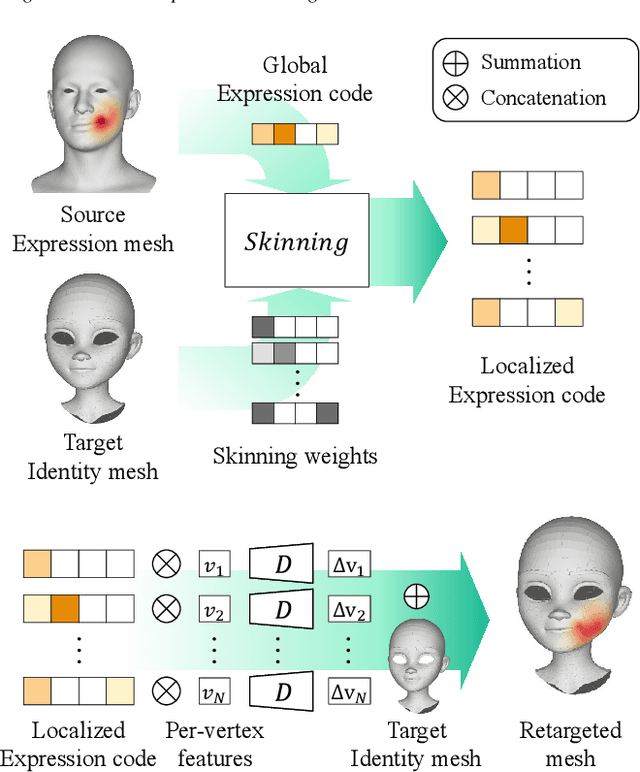
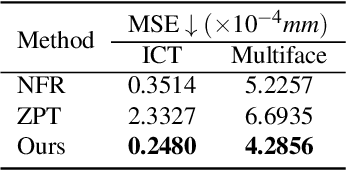
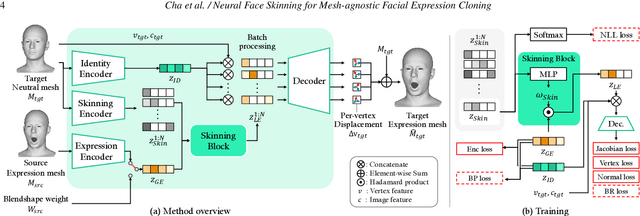
Accurately retargeting facial expressions to a face mesh while enabling manipulation is a key challenge in facial animation retargeting. Recent deep-learning methods address this by encoding facial expressions into a global latent code, but they often fail to capture fine-grained details in local regions. While some methods improve local accuracy by transferring deformations locally, this often complicates overall control of the facial expression. To address this, we propose a method that combines the strengths of both global and local deformation models. Our approach enables intuitive control and detailed expression cloning across diverse face meshes, regardless of their underlying structures. The core idea is to localize the influence of the global latent code on the target mesh. Our model learns to predict skinning weights for each vertex of the target face mesh through indirect supervision from predefined segmentation labels. These predicted weights localize the global latent code, enabling precise and region-specific deformations even for meshes with unseen shapes. We supervise the latent code using Facial Action Coding System (FACS)-based blendshapes to ensure interpretability and allow straightforward editing of the generated animation. Through extensive experiments, we demonstrate improved performance over state-of-the-art methods in terms of expression fidelity, deformation transfer accuracy, and adaptability across diverse mesh structures.
SALAD: Skeleton-aware Latent Diffusion for Text-driven Motion Generation and Editing
Mar 18, 2025

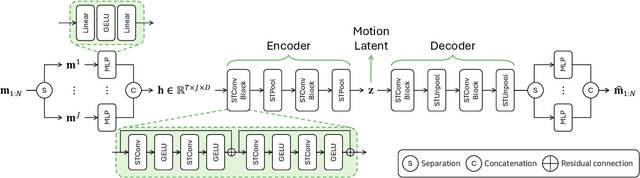
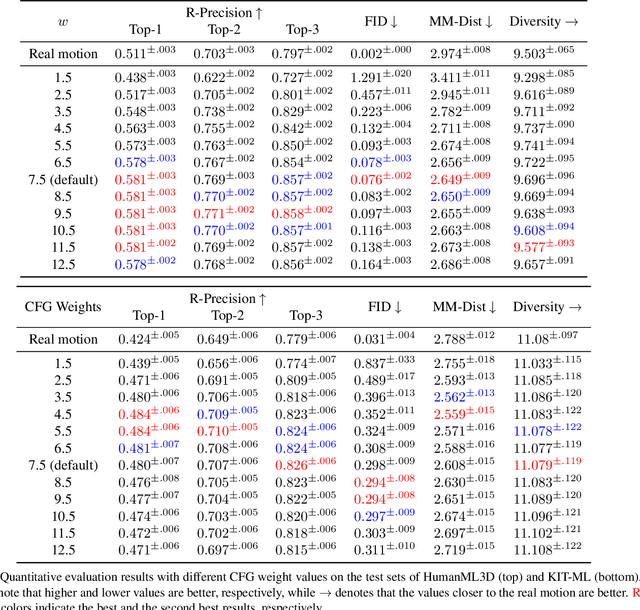
Text-driven motion generation has advanced significantly with the rise of denoising diffusion models. However, previous methods often oversimplify representations for the skeletal joints, temporal frames, and textual words, limiting their ability to fully capture the information within each modality and their interactions. Moreover, when using pre-trained models for downstream tasks, such as editing, they typically require additional efforts, including manual interventions, optimization, or fine-tuning. In this paper, we introduce a skeleton-aware latent diffusion (SALAD), a model that explicitly captures the intricate inter-relationships between joints, frames, and words. Furthermore, by leveraging cross-attention maps produced during the generation process, we enable attention-based zero-shot text-driven motion editing using a pre-trained SALAD model, requiring no additional user input beyond text prompts. Our approach significantly outperforms previous methods in terms of text-motion alignment without compromising generation quality, and demonstrates practical versatility by providing diverse editing capabilities beyond generation. Code is available at project page.
ASMR: Adaptive Skeleton-Mesh Rigging and Skinning via 2D Generative Prior
Mar 17, 2025Despite the growing accessibility of skeletal motion data, integrating it for animating character meshes remains challenging due to diverse configurations of both skeletons and meshes. Specifically, the body scale and bone lengths of the skeleton should be adjusted in accordance with the size and proportions of the mesh, ensuring that all joints are accurately positioned within the character mesh. Furthermore, defining skinning weights is complicated by variations in skeletal configurations, such as the number of joints and their hierarchy, as well as differences in mesh configurations, including their connectivity and shapes. While existing approaches have made efforts to automate this process, they hardly address the variations in both skeletal and mesh configurations. In this paper, we present a novel method for the automatic rigging and skinning of character meshes using skeletal motion data, accommodating arbitrary configurations of both meshes and skeletons. The proposed method predicts the optimal skeleton aligned with the size and proportion of the mesh as well as defines skinning weights for various mesh-skeleton configurations, without requiring explicit supervision tailored to each of them. By incorporating Diffusion 3D Features (Diff3F) as semantic descriptors of character meshes, our method achieves robust generalization across different configurations. To assess the performance of our method in comparison to existing approaches, we conducted comprehensive evaluations encompassing both quantitative and qualitative analyses, specifically examining the predicted skeletons, skinning weights, and deformation quality.
NeRFFaceSpeech: One-shot Audio-driven 3D Talking Head Synthesis via Generative Prior
May 10, 2024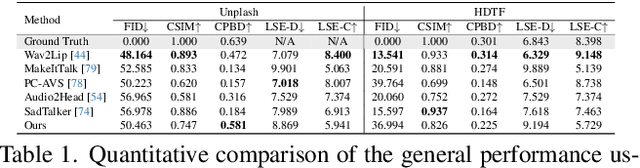
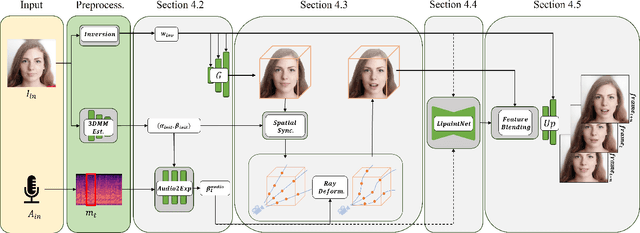
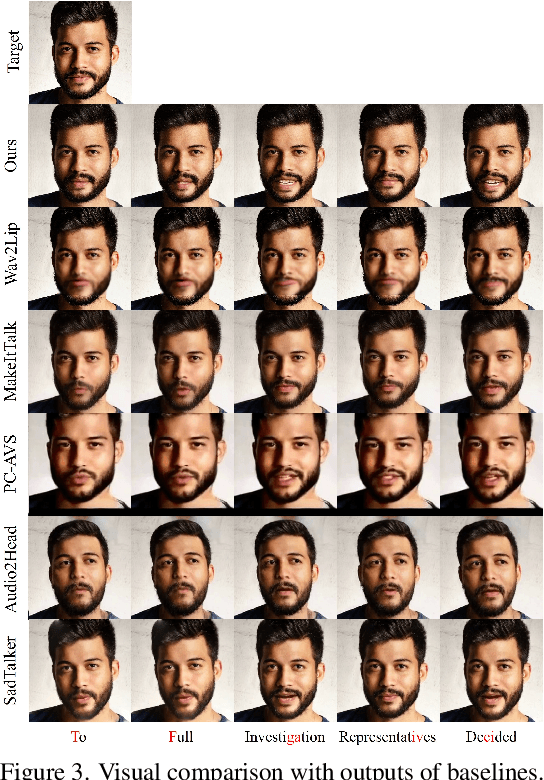
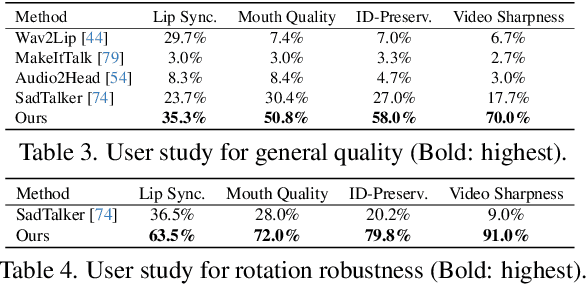
Audio-driven talking head generation is advancing from 2D to 3D content. Notably, Neural Radiance Field (NeRF) is in the spotlight as a means to synthesize high-quality 3D talking head outputs. Unfortunately, this NeRF-based approach typically requires a large number of paired audio-visual data for each identity, thereby limiting the scalability of the method. Although there have been attempts to generate audio-driven 3D talking head animations with a single image, the results are often unsatisfactory due to insufficient information on obscured regions in the image. In this paper, we mainly focus on addressing the overlooked aspect of 3D consistency in the one-shot, audio-driven domain, where facial animations are synthesized primarily in front-facing perspectives. We propose a novel method, NeRFFaceSpeech, which enables to produce high-quality 3D-aware talking head. Using prior knowledge of generative models combined with NeRF, our method can craft a 3D-consistent facial feature space corresponding to a single image. Our spatial synchronization method employs audio-correlated vertex dynamics of a parametric face model to transform static image features into dynamic visuals through ray deformation, ensuring realistic 3D facial motion. Moreover, we introduce LipaintNet that can replenish the lacking information in the inner-mouth area, which can not be obtained from a given single image. The network is trained in a self-supervised manner by utilizing the generative capabilities without additional data. The comprehensive experiments demonstrate the superiority of our method in generating audio-driven talking heads from a single image with enhanced 3D consistency compared to previous approaches. In addition, we introduce a quantitative way of measuring the robustness of a model against pose changes for the first time, which has been possible only qualitatively.
LeGO: Leveraging a Surface Deformation Network for Animatable Stylized Face Generation with One Example
Mar 22, 2024



Recent advances in 3D face stylization have made significant strides in few to zero-shot settings. However, the degree of stylization achieved by existing methods is often not sufficient for practical applications because they are mostly based on statistical 3D Morphable Models (3DMM) with limited variations. To this end, we propose a method that can produce a highly stylized 3D face model with desired topology. Our methods train a surface deformation network with 3DMM and translate its domain to the target style using a paired exemplar. The network achieves stylization of the 3D face mesh by mimicking the style of the target using a differentiable renderer and directional CLIP losses. Additionally, during the inference process, we utilize a Mesh Agnostic Encoder (MAGE) that takes deformation target, a mesh of diverse topologies as input to the stylization process and encodes its shape into our latent space. The resulting stylized face model can be animated by commonly used 3DMM blend shapes. A set of quantitative and qualitative evaluations demonstrate that our method can produce highly stylized face meshes according to a given style and output them in a desired topology. We also demonstrate example applications of our method including image-based stylized avatar generation, linear interpolation of geometric styles, and facial animation of stylized avatars.
Generating Texture for 3D Human Avatar from a Single Image using Sampling and Refinement Networks
May 01, 2023There has been significant progress in generating an animatable 3D human avatar from a single image. However, recovering texture for the 3D human avatar from a single image has been relatively less addressed. Because the generated 3D human avatar reveals the occluded texture of the given image as it moves, it is critical to synthesize the occluded texture pattern that is unseen from the source image. To generate a plausible texture map for 3D human avatars, the occluded texture pattern needs to be synthesized with respect to the visible texture from the given image. Moreover, the generated texture should align with the surface of the target 3D mesh. In this paper, we propose a texture synthesis method for a 3D human avatar that incorporates geometry information. The proposed method consists of two convolutional networks for the sampling and refining process. The sampler network fills in the occluded regions of the source image and aligns the texture with the surface of the target 3D mesh using the geometry information. The sampled texture is further refined and adjusted by the refiner network. To maintain the clear details in the given image, both sampled and refined texture is blended to produce the final texture map. To effectively guide the sampler network to achieve its goal, we designed a curriculum learning scheme that starts from a simple sampling task and gradually progresses to the task where the alignment needs to be considered. We conducted experiments to show that our method outperforms previous methods qualitatively and quantitatively.