 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised reference-based sketch extraction using a contrastive learning framework
Jul 19, 2024Sketches reflect the drawing style of individual artists; therefore, it is important to consider their unique styles when extracting sketches from color images for various applications. Unfortunately, most existing sketch extraction methods are designed to extract sketches of a single style. Although there have been some attempts to generate various style sketches, the methods generally suffer from two limitations: low quality results and difficulty in training the model due to the requirement of a paired dataset. In this paper, we propose a novel multi-modal sketch extraction method that can imitate the style of a given reference sketch with unpaired data training in a semi-supervised manner. Our method outperforms state-of-the-art sketch extraction methods and unpaired image translation methods in both quantitative and qualitative evaluations.
* Main paper 1-12 page, Supplementary 13-34 page
StyleCineGAN: Landscape Cinemagraph Generation using a Pre-trained StyleGAN
Mar 21, 2024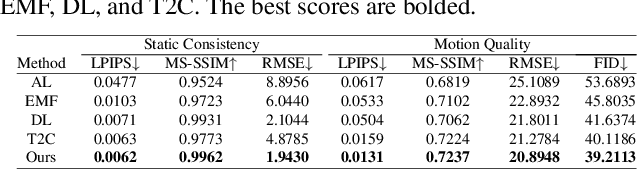
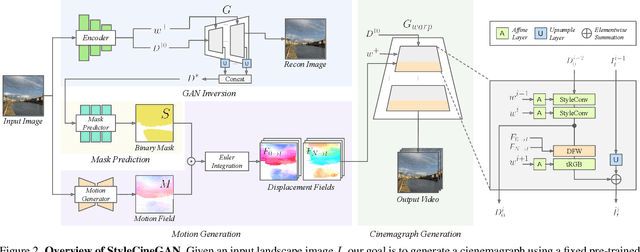
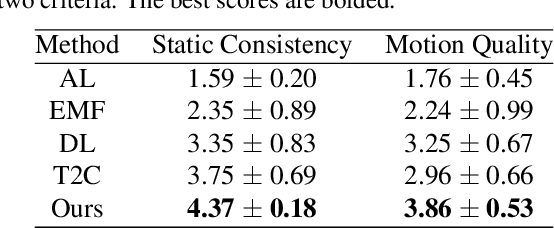
We propose a method that can generate cinemagraphs automatically from a still landscape image using a pre-trained StyleGAN. Inspired by the success of recent unconditional video generation, we leverage a powerful pre-trained image generator to synthesize high-quality cinemagraphs. Unlike previous approaches that mainly utilize the latent space of a pre-trained StyleGAN, our approach utilizes its deep feature space for both GAN inversion and cinemagraph generation. Specifically, we propose multi-scale deep feature warping (MSDFW), which warps the intermediate features of a pre-trained StyleGAN at different resolutions. By using MSDFW, the generated cinemagraphs are of high resolution and exhibit plausible looping animation. We demonstrate the superiority of our method through user studies and quantitative comparisons with state-of-the-art cinemagraph generation methods and a video generation method that uses a pre-trained StyleGAN.
Stylized Face Sketch Extraction via Generative Prior with Limited Data
Mar 17, 2024Facial sketches are both a concise way of showing the identity of a person and a means to express artistic intention. While a few techniques have recently emerged that allow sketches to be extracted in different styles, they typically rely on a large amount of data that is difficult to obtain. Here, we propose StyleSketch, a method for extracting high-resolution stylized sketches from a face image. Using the rich semantics of the deep features from a pretrained StyleGAN, we are able to train a sketch generator with 16 pairs of face and the corresponding sketch images. The sketch generator utilizes part-based losses with two-stage learning for fast convergence during training for high-quality sketch extraction. Through a set of comparisons, we show that StyleSketch outperforms existing state-of-the-art sketch extraction methods and few-shot image adaptation methods for the task of extracting high-resolution abstract face sketches. We further demonstrate the versatility of StyleSketch by extending its use to other domains and explore the possibility of semantic editing. The project page can be found in https://kwanyun.github.io/stylesketch_project.
Generating Texture for 3D Human Avatar from a Single Image using Sampling and Refinement Networks
May 01, 2023There has been significant progress in generating an animatable 3D human avatar from a single image. However, recovering texture for the 3D human avatar from a single image has been relatively less addressed. Because the generated 3D human avatar reveals the occluded texture of the given image as it moves, it is critical to synthesize the occluded texture pattern that is unseen from the source image. To generate a plausible texture map for 3D human avatars, the occluded texture pattern needs to be synthesized with respect to the visible texture from the given image. Moreover, the generated texture should align with the surface of the target 3D mesh. In this paper, we propose a texture synthesis method for a 3D human avatar that incorporates geometry information. The proposed method consists of two convolutional networks for the sampling and refining process. The sampler network fills in the occluded regions of the source image and aligns the texture with the surface of the target 3D mesh using the geometry information. The sampled texture is further refined and adjusted by the refiner network. To maintain the clear details in the given image, both sampled and refined texture is blended to produce the final texture map. To effectively guide the sampler network to achieve its goal, we designed a curriculum learning scheme that starts from a simple sampling task and gradually progresses to the task where the alignment needs to be considered. We conducted experiments to show that our method outperforms previous methods qualitatively and quantitatively.