 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyMoLe: Any Character Motion In-betweening Leveraging Video Diffusion Models
Mar 11, 2025

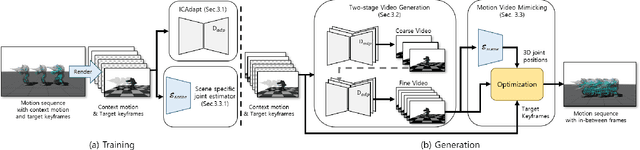

Despite recent advancements in learning-based motion in-betweening, a key limitation has been overlooked: the requirement for character-specific datasets. In this work, we introduce AnyMoLe, a novel method that addresses this limitation by leveraging video diffusion models to generate motion in-between frames for arbitrary characters without external data. Our approach employs a two-stage frame generation process to enhance contextual understanding. Furthermore, to bridge the domain gap between real-world and rendered character animations, we introduce ICAdapt, a fine-tuning technique for video diffusion models. Additionally, we propose a ``motion-video mimicking'' optimization technique, enabling seamless motion generation for characters with arbitrary joint structures using 2D and 3D-aware features. AnyMoLe significantly reduces data dependency while generating smooth and realistic transitions, making it applicable to a wide range of motion in-betweening tasks.
LeGO: Leveraging a Surface Deformation Network for Animatable Stylized Face Generation with One Example
Mar 22, 2024Recent advances in 3D face stylization have made significant strides in few to zero-shot settings. However, the degree of stylization achieved by existing methods is often not sufficient for practical applications because they are mostly based on statistical 3D Morphable Models (3DMM) with limited variations. To this end, we propose a method that can produce a highly stylized 3D face model with desired topology. Our methods train a surface deformation network with 3DMM and translate its domain to the target style using a paired exemplar. The network achieves stylization of the 3D face mesh by mimicking the style of the target using a differentiable renderer and directional CLIP losses. Additionally, during the inference process, we utilize a Mesh Agnostic Encoder (MAGE) that takes deformation target, a mesh of diverse topologies as input to the stylization process and encodes its shape into our latent space. The resulting stylized face model can be animated by commonly used 3DMM blend shapes. A set of quantitative and qualitative evaluations demonstrate that our method can produce highly stylized face meshes according to a given style and output them in a desired topology. We also demonstrate example applications of our method including image-based stylized avatar generation, linear interpolation of geometric styles, and facial animation of stylized avatars.
Stylized Face Sketch Extraction via Generative Prior with Limited Data
Mar 17, 2024Facial sketches are both a concise way of showing the identity of a person and a means to express artistic intention. While a few techniques have recently emerged that allow sketches to be extracted in different styles, they typically rely on a large amount of data that is difficult to obtain. Here, we propose StyleSketch, a method for extracting high-resolution stylized sketches from a face image. Using the rich semantics of the deep features from a pretrained StyleGAN, we are able to train a sketch generator with 16 pairs of face and the corresponding sketch images. The sketch generator utilizes part-based losses with two-stage learning for fast convergence during training for high-quality sketch extraction. Through a set of comparisons, we show that StyleSketch outperforms existing state-of-the-art sketch extraction methods and few-shot image adaptation methods for the task of extracting high-resolution abstract face sketches. We further demonstrate the versatility of StyleSketch by extending its use to other domains and explore the possibility of semantic editing. The project page can be found in https://kwanyun.github.io/stylesketch_project.
Representative Feature Extraction During Diffusion Process for Sketch Extraction with One Example
Jan 09, 2024We introduce DiffSketch, a method for generating a variety of stylized sketches from images. Our approach focuses on selecting representative features from the rich semantics of deep features within a pretrained diffusion model. This novel sketch generation method can be trained with one manual drawing. Furthermore, efficient sketch extraction is ensured by distilling a trained generator into a streamlined extractor. We select denoising diffusion features through analysis and integrate these selected features with VAE features to produce sketches. Additionally, we propose a sampling scheme for training models using a conditional generative approach. Through a series of comparisons, we verify that distilled DiffSketch not only outperforms existing state-of-the-art sketch extraction methods but also surpasses diffusion-based stylization methods in the task of extracting sketches.