 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALAD: Skeleton-aware Latent Diffusion for Text-driven Motion Generation and Editing
Mar 18, 2025Text-driven motion generation has advanced significantly with the rise of denoising diffusion models. However, previous methods often oversimplify representations for the skeletal joints, temporal frames, and textual words, limiting their ability to fully capture the information within each modality and their interactions. Moreover, when using pre-trained models for downstream tasks, such as editing, they typically require additional efforts, including manual interventions, optimization, or fine-tuning. In this paper, we introduce a skeleton-aware latent diffusion (SALAD), a model that explicitly captures the intricate inter-relationships between joints, frames, and words. Furthermore, by leveraging cross-attention maps produced during the generation process, we enable attention-based zero-shot text-driven motion editing using a pre-trained SALAD model, requiring no additional user input beyond text prompts. Our approach significantly outperforms previous methods in terms of text-motion alignment without compromising generation quality, and demonstrates practical versatility by providing diverse editing capabilities beyond generation. Code is available at project page.
ASMR: Adaptive Skeleton-Mesh Rigging and Skinning via 2D Generative Prior
Mar 17, 2025Despite the growing accessibility of skeletal motion data, integrating it for animating character meshes remains challenging due to diverse configurations of both skeletons and meshes. Specifically, the body scale and bone lengths of the skeleton should be adjusted in accordance with the size and proportions of the mesh, ensuring that all joints are accurately positioned within the character mesh. Furthermore, defining skinning weights is complicated by variations in skeletal configurations, such as the number of joints and their hierarchy, as well as differences in mesh configurations, including their connectivity and shapes. While existing approaches have made efforts to automate this process, they hardly address the variations in both skeletal and mesh configurations. In this paper, we present a novel method for the automatic rigging and skinning of character meshes using skeletal motion data, accommodating arbitrary configurations of both meshes and skeletons. The proposed method predicts the optimal skeleton aligned with the size and proportion of the mesh as well as defines skinning weights for various mesh-skeleton configurations, without requiring explicit supervision tailored to each of them. By incorporating Diffusion 3D Features (Diff3F) as semantic descriptors of character meshes, our method achieves robust generalization across different configurations. To assess the performance of our method in comparison to existing approaches, we conducted comprehensive evaluations encompassing both quantitative and qualitative analyses, specifically examining the predicted skeletons, skinning weights, and deformation quality.
AnyMoLe: Any Character Motion In-betweening Leveraging Video Diffusion Models
Mar 11, 2025

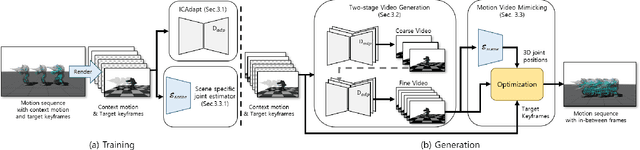

Despite recent advancements in learning-based motion in-betweening, a key limitation has been overlooked: the requirement for character-specific datasets. In this work, we introduce AnyMoLe, a novel method that addresses this limitation by leveraging video diffusion models to generate motion in-between frames for arbitrary characters without external data. Our approach employs a two-stage frame generation process to enhance contextual understanding. Furthermore, to bridge the domain gap between real-world and rendered character animations, we introduce ICAdapt, a fine-tuning technique for video diffusion models. Additionally, we propose a ``motion-video mimicking'' optimization technique, enabling seamless motion generation for characters with arbitrary joint structures using 2D and 3D-aware features. AnyMoLe significantly reduces data dependency while generating smooth and realistic transitions, making it applicable to a wide range of motion in-betweening tasks.