 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Class-Incremental Learning with Non-IID Decentralized Data
Sep 18, 2024

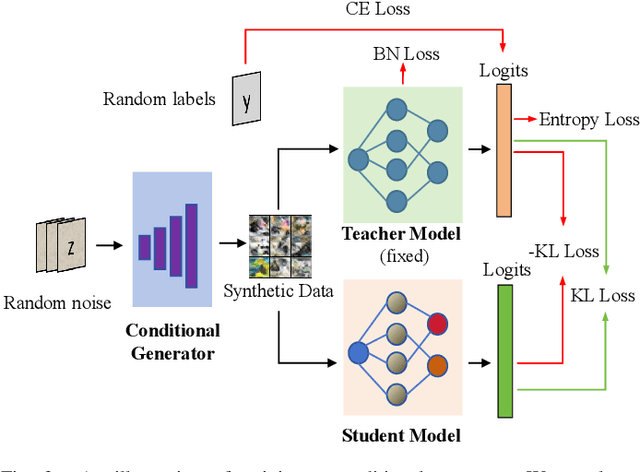

Few-shot class-incremental learning is crucial for developing scalable and adaptive intelligent systems, as it enables models to acquire new classes with minimal annotated data while safeguarding the previously accumulated knowledge. Nonetheless, existing methods deal with continuous data streams in a centralized manner, limiting their applicability in scenarios that prioritize data privacy and security. To this end, this paper introduces federated few-shot class-incremental learning, a decentralized machine learning paradigm tailored to progressively learn new classes from scarce data distributed across multiple clients. In this learning paradigm, clients locally update their models with new classes while preserving data privacy, and then transmit the model updates to a central server where they are aggregated globally. However, this paradigm faces several issues, such as difficulties in few-shot learning, catastrophic forgetting, and data heterogeneity. To address these challenges, we present a synthetic data-driven framework that leverages replay buffer data to maintain existing knowledge and facilitate the acquisition of new knowledge. Within this framework, a noise-aware generative replay module is developed to fine-tune local models with a balance of new and replay data, while generating synthetic data of new classes to further expand the replay buffer for future tasks. Furthermore, a class-specific weighted aggregation strategy is designed to tackle data heterogeneity by adaptively aggregating class-specific parameters based on local models performance on synthetic data. This enables effective global model optimization without direct access to client data. Comprehensive experiments across three widely-used datasets underscore the effectiveness and preeminence of the introduced framework.