 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Class-Incremental Learning with Non-IID Decentralized Data
Sep 18, 2024

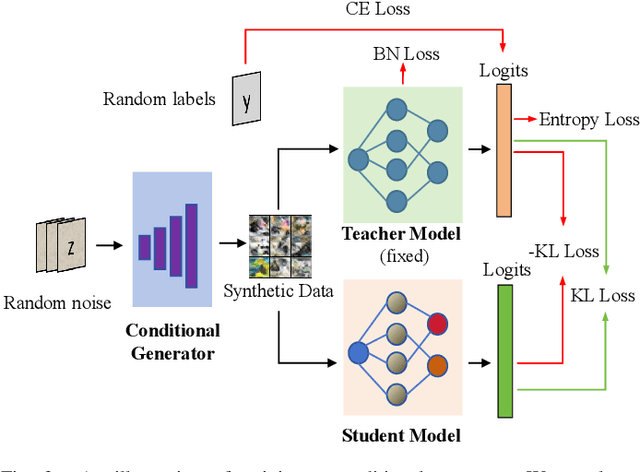

Few-shot class-incremental learning is crucial for developing scalable and adaptive intelligent systems, as it enables models to acquire new classes with minimal annotated data while safeguarding the previously accumulated knowledge. Nonetheless, existing methods deal with continuous data streams in a centralized manner, limiting their applicability in scenarios that prioritize data privacy and security. To this end, this paper introduces federated few-shot class-incremental learning, a decentralized machine learning paradigm tailored to progressively learn new classes from scarce data distributed across multiple clients. In this learning paradigm, clients locally update their models with new classes while preserving data privacy, and then transmit the model updates to a central server where they are aggregated globally. However, this paradigm faces several issues, such as difficulties in few-shot learning, catastrophic forgetting, and data heterogeneity. To address these challenges, we present a synthetic data-driven framework that leverages replay buffer data to maintain existing knowledge and facilitate the acquisition of new knowledge. Within this framework, a noise-aware generative replay module is developed to fine-tune local models with a balance of new and replay data, while generating synthetic data of new classes to further expand the replay buffer for future tasks. Furthermore, a class-specific weighted aggregation strategy is designed to tackle data heterogeneity by adaptively aggregating class-specific parameters based on local models performance on synthetic data. This enables effective global model optimization without direct access to client data. Comprehensive experiments across three widely-used datasets underscore the effectiveness and preeminence of the introduced framework.
A Transformer-Based Adaptive Semantic Aggregation Method for UAV Visual Geo-Localization
Jan 03, 2024This paper addresses the task of Unmanned Aerial Vehicles (UAV) visual geo-localization, which aims to match images of the same geographic target taken by different platforms, i.e., UAVs and satellites. In general, the key to achieving accurate UAV-satellite image matching lies in extracting visual features that are robust against viewpoint changes, scale variations, and rotations. Current works have shown that part matching is crucial for UAV visual geo-localization since part-level representations can capture image details and help to understand the semantic information of scenes. However, the importance of preserving semantic characteristics in part-level representations is not well discussed. In this paper, we introduce a transformer-based adaptive semantic aggregation method that regards parts as the most representative semantics in an image. Correlations of image patches to different parts are learned in terms of the transformer's feature map. Then our method decomposes part-level features into an adaptive sum of all patch features. By doing this, the learned parts are encouraged to focus on patches with typical semantics. Extensive experiments on the University-1652 dataset have shown the superiority of our method over the current works.
* 12 pages
View Distribution Alignment with Progressive Adversarial Learning for UAV Visual Geo-Localization
Jan 03, 2024Unmanned Aerial Vehicle (UAV) visual geo-localization aims to match images of the same geographic target captured from different views, i.e., the UAV view and the satellite view. It is very challenging due to the large appearance differences in UAV-satellite image pairs. Previous works map images captured by UAVs and satellites to a shared feature space and employ a classification framework to learn location-dependent features while neglecting the overall distribution shift between the UAV view and the satellite view. In this paper, we address these limitations by introducing distribution alignment of the two views to shorten their distance in a common space. Specifically, we propose an end-to-end network, called PVDA (Progressive View Distribution Alignment). During training, feature encoder, location classifier, and view discriminator are jointly optimized by a novel progressive adversarial learning strategy. Competition between feature encoder and view discriminator prompts both of them to be stronger. It turns out that the adversarial learning is progressively emphasized until UAV-view images are indistinguishable from satellite-view images. As a result, the proposed PVDA becomes powerful in learning location-dependent yet view-invariant features with good scalability towards unseen images of new locations. Compared to the state-of-the-art methods, the proposed PVDA requires less inference time but has achieved superior performance on the University-1652 dataset.
* 12 pages