 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertified Unlearning in Decentralized Federated Learning
Jan 10, 2026Driven by the right to be forgotten (RTBF), machine unlearning has become an essential requirement for privacy-preserving machine learning. However, its realization in decentralized federated learning (DFL) remains largely unexplored. In DFL, clients exchange local updates only with neighbors, causing model information to propagate and mix across the network. As a result, when a client requests data deletion, its influence is implicitly embedded throughout the system, making removal difficult without centralized coordination. We propose a novel certified unlearning framework for DFL based on Newton-style updates. Our approach first quantifies how a client's data influence propagates during training. Leveraging curvature information of the loss with respect to the target data, we then construct corrective updates using Newton-style approximations. To ensure scalability, we approximate second-order information via Fisher information matrices. The resulting updates are perturbed with calibrated noise and broadcast through the network to eliminate residual influence across clients. We theoretically prove that our approach satisfies the formal definition of certified unlearning, ensuring that the unlearned model is difficult to distinguish from a retrained model without the deleted data. We also establish utility bounds showing that the unlearned model remains close to retraining from scratch. Extensive experiments across diverse decentralized settings demonstrate the effectiveness and efficiency of our framework.
Resource-Adaptive Newton's Method for Distributed Learning
Sep 02, 2023Distributed stochastic optimization methods based on Newton's method offer significant advantages over first-order methods by leveraging curvature information for improved performance. However, the practical applicability of Newton's method is hindered in large-scale and heterogeneous learning environments due to challenges such as high computation and communication costs associated with the Hessian matrix, sub-model diversity, staleness in training, and data heterogeneity. To address these challenges, this paper introduces a novel and efficient algorithm called RANL, which overcomes the limitations of Newton's method by employing a simple Hessian initialization and adaptive assignments of training regions. The algorithm demonstrates impressive convergence properties, which are rigorously analyzed under standard assumptions in stochastic optimization. The theoretical analysis establishes that RANL achieves a linear convergence rate while effectively adapting to available resources and maintaining high efficiency. Unlike traditional first-order methods, RANL exhibits remarkable independence from the condition number of the problem and eliminates the need for complex parameter tuning. These advantages make RANL a promising approach for distributed stochastic optimization in practical scenarios.
A Distributed Privacy-Preserving Learning Dynamics in General Social Networks
Nov 15, 2020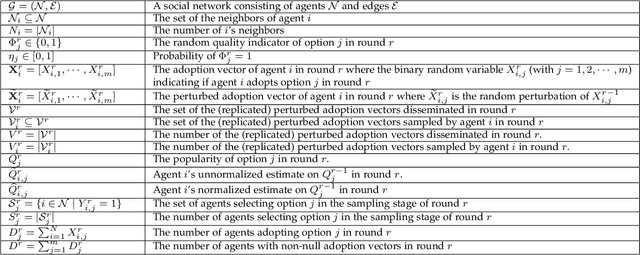
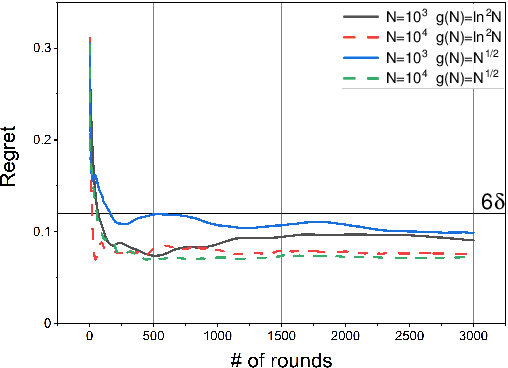
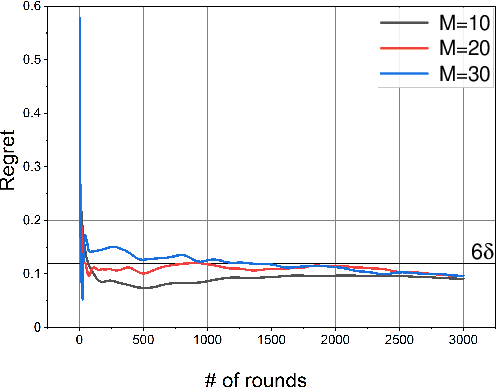
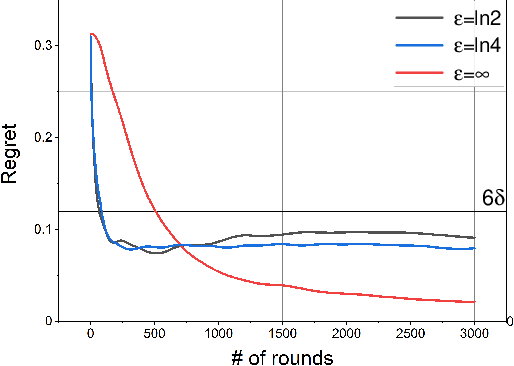
In this paper, we study a distributed privacy-preserving learning problem in general social networks. Specifically, we consider a very general problem setting where the agents in a given multi-hop social network are required to make sequential decisions to choose among a set of options featured by unknown stochastic quality signals. Each agent is allowed to interact with its peers through multi-hop communications but with its privacy preserved. To serve the above goals, we propose a four-staged distributed social learning algorithm. In a nutshell, our algorithm proceeds iteratively, and in every round, each agent i) randomly perturbs its adoption for privacy-preserving purpose, ii) disseminates the perturbed adoption over the social network in a nearly uniform manner through random walking, iii) selects an option by referring to its peers' perturbed latest adoptions, and iv) decides whether or not to adopt the selected option according to its latest quality signal. By our solid theoretical analysis, we provide answers to two fundamental algorithmic questions about the performance of our four-staged algorithm: on one hand, we illustrate the convergence of our algorithm when there are a sufficient number of agents in the social network, each of which are with incomplete and perturbed knowledge as input; on the other hand, we reveal the quantitative trade-off between the privacy loss and the communication overhead towards the convergence. We also perform extensive simulations to validate our theoretical analysis and to verify the efficacy of our algorithm.