 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Every Step Effective: Jailbreaking Large Vision-Language Models Through Hierarchical KV Equalization
Mar 14, 2025
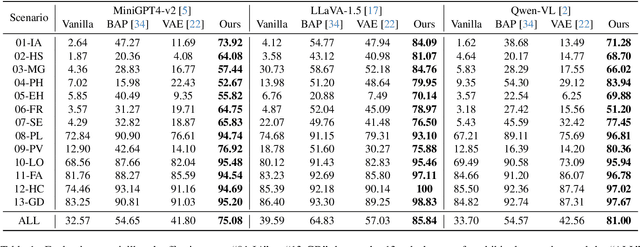


In the realm of large vision-language models (LVLMs), adversarial jailbreak attacks serve as a red-teaming approach to identify safety vulnerabilities of these models and their associated defense mechanisms. However, we identify a critical limitation: not every adversarial optimization step leads to a positive outcome, and indiscriminately accepting optimization results at each step may reduce the overall attack success rate. To address this challenge, we introduce HKVE (Hierarchical Key-Value Equalization), an innovative jailbreaking framework that selectively accepts gradient optimization results based on the distribution of attention scores across different layers, ensuring that every optimization step positively contributes to the attack. Extensive experiments demonstrate HKVE's significant effectiveness, achieving attack success rates of 75.08% on MiniGPT4, 85.84% on LLaVA and 81.00% on Qwen-VL, substantially outperforming existing methods by margins of 20.43\%, 21.01\% and 26.43\% respectively. Furthermore, making every step effective not only leads to an increase in attack success rate but also allows for a reduction in the number of iterations, thereby lowering computational costs. Warning: This paper contains potentially harmful example data.
Exploring Visual Vulnerabilities via Multi-Loss Adversarial Search for Jailbreaking Vision-Language Models
Nov 27, 2024Despite inheriting security measures from underlying language models, Vision-Language Models (VLMs) may still be vulnerable to safety alignment issues. Through empirical analysis, we uncover two critical findings: scenario-matched images can significantly amplify harmful outputs, and contrary to common assumptions in gradient-based attacks, minimal loss values do not guarantee optimal attack effectiveness. Building on these insights, we introduce MLAI (Multi-Loss Adversarial Images), a novel jailbreak framework that leverages scenario-aware image generation for semantic alignment, exploits flat minima theory for robust adversarial image selection, and employs multi-image collaborative attacks for enhanced effectiveness. Extensive experiments demonstrate MLAI's significant impact, achieving attack success rates of 77.75% on MiniGPT-4 and 82.80% on LLaVA-2, substantially outperforming existing methods by margins of 34.37% and 12.77% respectively. Furthermore, MLAI shows considerable transferability to commercial black-box VLMs, achieving up to 60.11% success rate. Our work reveals fundamental visual vulnerabilities in current VLMs safety mechanisms and underscores the need for stronger defenses. Warning: This paper contains potentially harmful example text.