 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Active Learning for Computer Vision: Past and Future
Nov 27, 2022



As an important data selection schema, active learning emerges as the essential component when iterating an Artificial Intelligence (AI) model. It becomes even more critical given the dominance of deep neural network based models, which are composed of a large number of parameters and data hungry, in application. Despite its indispensable role for developing AI models, research on active learning is not as intensive as other research directions. In this paper, we present a review of active learning through deep active learning approaches from the following perspectives: 1) technical advancements in active learning, 2) applications of active learning in computer vision, 3) industrial systems leveraging or with potential to leverage active learning for data iteration, 4) current limitations and future research directions. We expect this paper to clarify the significance of active learning in a modern AI model manufacturing process and to bring additional research attention to active learning. By addressing data automation challenges and coping with automated machine learning systems, active learning will facilitate democratization of AI technologies by boosting model production at scale.
Resolution-invariant Person Re-Identification
Jun 28, 2019

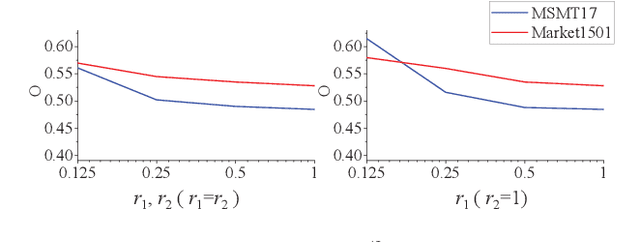
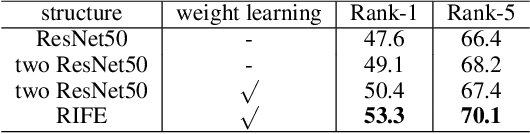
Exploiting resolution invariant representation is critical for person Re-Identification (ReID) in real applications, where the resolutions of captured person images may vary dramatically. This paper learns person representations robust to resolution variance through jointly training a Foreground-Focus Super-Resolution (FFSR) module and a Resolution-Invariant Feature Extractor (RIFE) by end-to-end CNN learning. FFSR upscales the person foreground using a fully convolutional auto-encoder with skip connections learned with a foreground focus training loss. RIFE adopts two feature extraction streams weighted by a dual-attention block to learn features for low and high resolution images, respectively. These two complementary modules are jointly trained, leading to a strong resolution invariant representation. We evaluate our methods on five datasets containing person images at a large range of resolutions, where our methods show substantial superiority to existing solutions. For instance, we achieve Rank-1 accuracy of 36.4% and 73.3% on CAVIAR and MLR-CUHK03, outperforming the state-of-the art by 2.9% and 2.6%, respectively.