 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Superposition: A Theory of Feature Geometry
Feb 02, 2026Neural networks represent more features than they have dimensions via superposition, forcing features to share representational space. Current methods decompose activations into sparse linear features but discard geometric structure. We develop a theory for studying the geometric structre of features by analyzing the spectra (eigenvalues, eigenspaces, etc.) of weight derived matrices. In particular, we introduce the frame operator $F = WW^\top$, which gives us a spectral measure that describes how each feature allocates norm across eigenspaces. While previous tools could describe the pairwise interactions between features, spectral methods capture the global geometry (``how do all features interact?''). In toy models of superposition, we use this theory to prove that capacity saturation forces spectral localization: features collapse onto single eigenspaces, organize into tight frames, and admit discrete classification via association schemes, classifying all geometries from prior work (simplices, polygons, antiprisms). The spectral measure formalism applies to arbitrary weight matrices, enabling diagnosis of feature localization beyond toy settings. These results point toward a broader program: applying operator theory to interpretability.
Position: Require Frontier AI Labs To Release Small "Analog" Models
Oct 15, 2025Recent proposals for regulating frontier AI models have sparked concerns about the cost of safety regulation, and most such regulations have been shelved due to the safety-innovation tradeoff. This paper argues for an alternative regulatory approach that ensures AI safety while actively promoting innovation: mandating that large AI laboratories release small, openly accessible analog models (scaled-down versions) trained similarly to and distilled from their largest proprietary models. Analog models serve as public proxies, allowing broad participation in safety verification, interpretability research, and algorithmic transparency without forcing labs to disclose their full-scale models. Recent research demonstrates that safety and interpretability methods developed using these smaller models generalize effectively to frontier-scale systems. By enabling the wider research community to directly investigate and innovate upon accessible analogs, our policy substantially reduces the regulatory burden and accelerates safety advancements. This mandate promises minimal additional costs, leveraging reusable resources like data and infrastructure, while significantly contributing to the public good. Our hope is not only that this policy be adopted, but that it illustrates a broader principle supporting fundamental research in machine learning: deeper understanding of models relaxes the safety-innovation tradeoff and lets us have more of both.
A Feasibility Study of Answer-Agnostic Question Generation for Education
Mar 29, 2022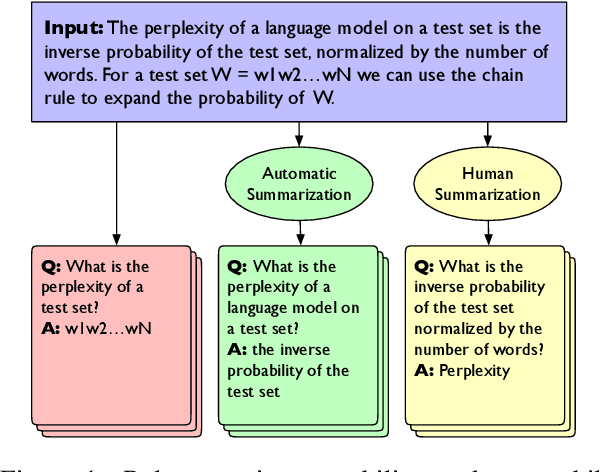
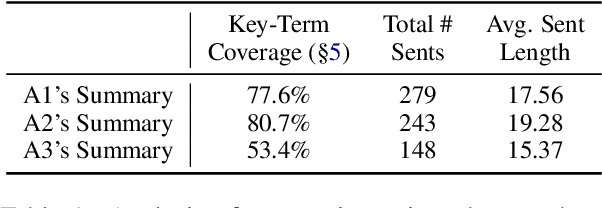
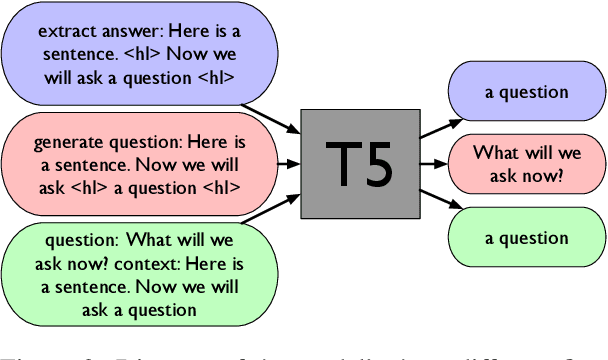
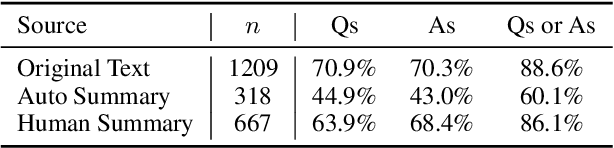
We conduct a feasibility study into the applicability of answer-agnostic question generation models to textbook passages. We show that a significant portion of errors in such systems arise from asking irrelevant or uninterpretable questions and that such errors can be ameliorated by providing summarized input. We find that giving these models human-written summaries instead of the original text results in a significant increase in acceptability of generated questions (33% $\rightarrow$ 83%) as determined by expert annotators. We also find that, in the absence of human-written summaries, automatic summarization can serve as a good middle ground.