Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Feasibility Study of Answer-Agnostic Question Generation for Education
Paper and Code
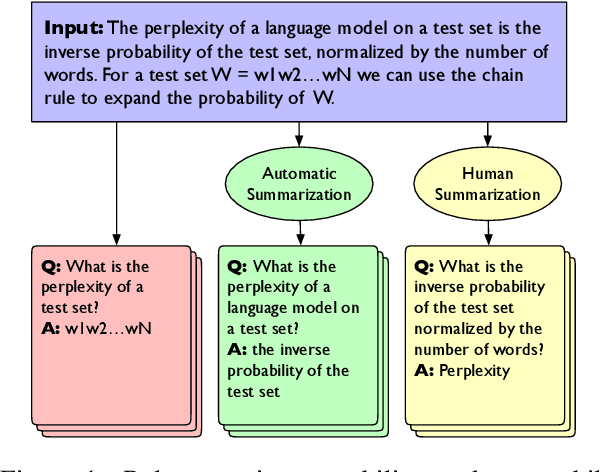
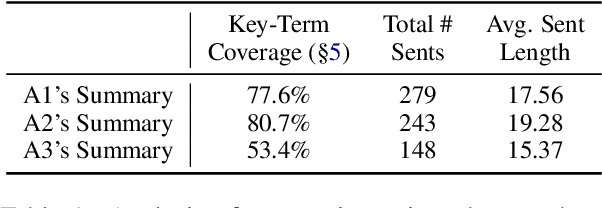
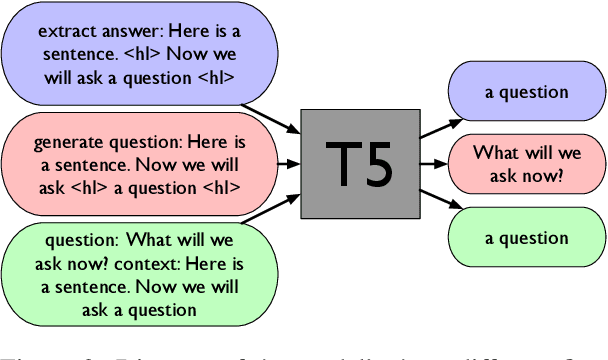
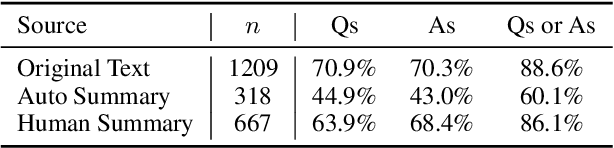
We conduct a feasibility study into the applicability of answer-agnostic question generation models to textbook passages. We show that a significant portion of errors in such systems arise from asking irrelevant or uninterpretable questions and that such errors can be ameliorated by providing summarized input. We find that giving these models human-written summaries instead of the original text results in a significant increase in acceptability of generated questions (33% $\rightarrow$ 83%) as determined by expert annotators. We also find that, in the absence of human-written summaries, automatic summarization can serve as a good middle ground.
* To be published in 60th Annual Meeting of the Association for
Computational Linguistics (ACL 2022)
View paper on