 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Automatic Machine Translation Evaluation Metric Based on Dependency Parsing Model
Nov 04, 2016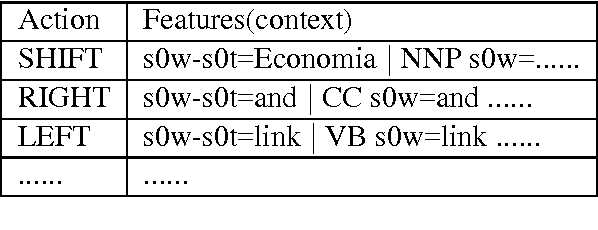



Most of the syntax-based metrics obtain the similarity by comparing the sub-structures extracted from the trees of hypothesis and reference. These sub-structures are defined by human and can't express all the information in the trees because of the limited length of sub-structures. In addition, the overlapped parts between these sub-structures are computed repeatedly. To avoid these problems, we propose a novel automatic evaluation metric based on dependency parsing model, with no need to define sub-structures by human. First, we train a dependency parsing model by the reference dependency tree. Then we generate the hypothesis dependency tree and the corresponding probability by the dependency parsing model. The quality of the hypothesis can be judged by this probability. In order to obtain the lexicon similarity, we also introduce the unigram F-score to the new metric. Experiment results show that the new metric gets the state-of-the-art performance on system level, and is comparable with METEOR on sentence level.