 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical-Neural Interaction Networks for Interpretable Mixed-Type Data Imputation
Jan 18, 2026Real-world tabular databases routinely combine continuous measurements and categorical records, yet missing entries are pervasive and can distort downstream analysis. We propose Statistical-Neural Interaction (SNI), an interpretable mixed-type imputation framework that couples correlation-derived statistical priors with neural feature attention through a Controllable-Prior Feature Attention (CPFA) module. CPFA learns head-wise prior-strength coefficients $\{λ_h\}$ that softly regularize attention toward the prior while allowing data-driven deviations when nonlinear patterns appear to be present in the data. Beyond imputation, SNI aggregates attention maps into a directed feature-dependency matrix that summarizes which variables the imputer relied on, without requiring post-hoc explainers. We evaluate SNI against six baselines (Mean/Mode, MICE, KNN, MissForest, GAIN, MIWAE) on six datasets spanning ICU monitoring, population surveys, socio-economic statistics, and engineering applications. Under MCAR/strict-MAR at 30\% missingness, SNI is generally competitive on continuous metrics but is often outperformed by accuracy-first baselines (MissForest, MIWAE) on categorical variables; in return, it provides intrinsic dependency diagnostics and explicit statistical-neural trade-off parameters. We additionally report MNAR stress tests (with a mask-aware variant) and discuss computational cost, limitations -- particularly for severely imbalanced categorical targets -- and deployment scenarios where interpretability may justify the trade-off.
Evolutionary Causal Discovery with Relative Impact Stratification for Interpretable Data Analysis
Apr 25, 2024This study proposes Evolutionary Causal Discovery (ECD) for causal discovery that tailors response variables, predictor variables, and corresponding operators to research datasets. Utilizing genetic programming for variable relationship parsing, the method proceeds with the Relative Impact Stratification (RIS) algorithm to assess the relative impact of predictor variables on the response variable, facilitating expression simplification and enhancing the interpretability of variable relationships. ECD proposes an expression tree to visualize the RIS results, offering a differentiated depiction of unknown causal relationships compared to conventional causal discovery. The ECD method represents an evolution and augmentation of existing causal discovery methods, providing an interpretable approach for analyzing variable relationships in complex systems, particularly in healthcare settings with Electronic Health Record (EHR) data. Experiments on both synthetic and real-world EHR datasets demonstrate the efficacy of ECD in uncovering patterns and mechanisms among variables, maintaining high accuracy and stability across different noise levels. On the real-world EHR dataset, ECD reveals the intricate relationships between the response variable and other predictive variables, aligning with the results of structural equation modeling and shapley additive explanations analyses.
Weakly-Supervised Multi-Person Action Recognition in 360$^{\circ}$ Videos
Feb 09, 2020
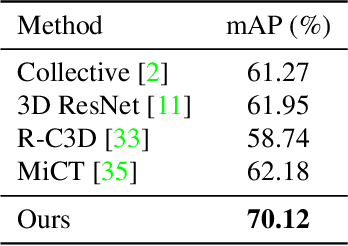
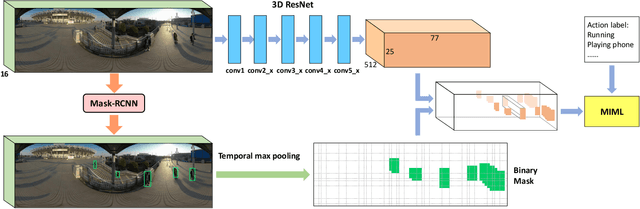

The recent development of commodity 360$^{\circ}$ cameras have enabled a single video to capture an entire scene, which endows promising potentials in surveillance scenarios. However, research in omnidirectional video analysis has lagged behind the hardware advances. In this work, we address the important problem of action recognition in top-view 360$^{\circ}$ videos. Due to the wide filed-of-view, 360$^{\circ}$ videos usually capture multiple people performing actions at the same time. Furthermore, the appearance of people are deformed. The proposed framework first transforms omnidirectional videos into panoramic videos, then it extracts spatial-temporal features using region-based 3D CNNs for action recognition. We propose a weakly-supervised method based on multi-instance multi-label learning, which trains the model to recognize and localize multiple actions in a video using only video-level action labels as supervision. We perform experiments to quantitatively validate the efficacy of the proposed method and qualitatively demonstrate action localization results. To enable research in this direction, we introduce 360Action, the first omnidirectional video dataset for multi-person action recognition.