 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Consistency: Overcoming Annotation Scarcity and Domain Shifts
Apr 15, 2020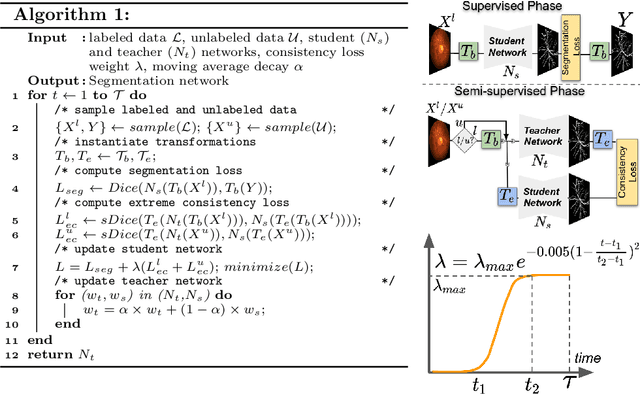
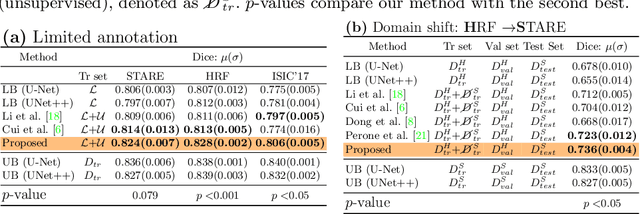
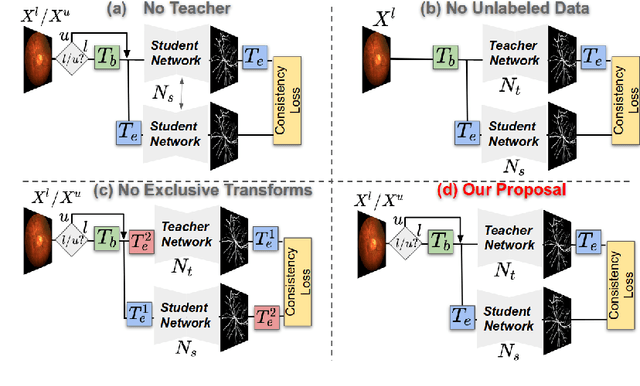
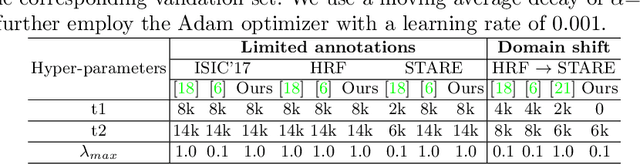
Supervised learning has proved effective for medical image analysis. However, it can utilize only the small labeled portion of data; it fails to leverage the large amounts of unlabeled data that is often available in medical image datasets. Supervised models are further handicapped by domain shifts, when the labeled dataset, despite being large enough, fails to cover different protocols or ethnicities. In this paper, we introduce \emph{extreme consistency}, which overcomes the above limitations, by maximally leveraging unlabeled data from the same or a different domain in a teacher-student semi-supervised paradigm. Extreme consistency is the process of sending an extreme transformation of a given image to the student network and then constraining its prediction to be consistent with the teacher network's prediction for the untransformed image. The extreme nature of our consistency loss distinguishes our method from related works that yield suboptimal performance by exercising only mild prediction consistency. Our method is 1) auto-didactic, as it requires no extra expert annotations; 2) versatile, as it handles both domain shift and limited annotation problems; 3) generic, as it is readily applicable to classification, segmentation, and detection tasks; and 4) simple to implement, as it requires no adversarial training. We evaluate our method for the tasks of lesion and retinal vessel segmentation in skin and fundus images. Our experiments demonstrate a significant performance gain over both modern supervised networks and recent semi-supervised models. This performance is attributed to the strong regularization enforced by extreme consistency, which enables the student network to learn how to handle extreme variants of both labeled and unlabeled images. This enhances the network's ability to tackle the inevitable same- and cross-domain data variability during inference.
ErrorNet: Learning error representations from limited data to improve vascular segmentation
Oct 21, 2019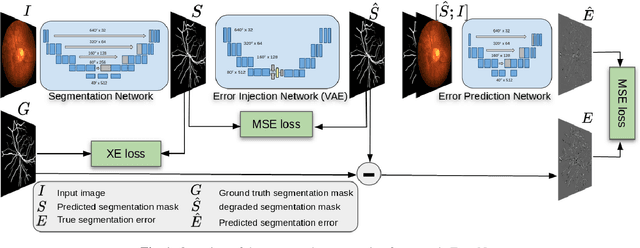
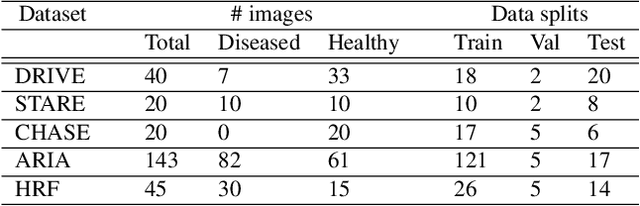

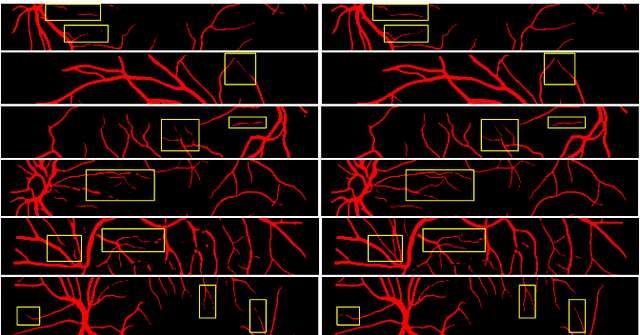
Deep convolutional neural networks have proved effective in segmenting lesions and anatomies in various medical imaging modalities. However, in the presence of small sample size and domain shift problems, these models often produce masks with non-intuitive segmentation mistakes. In this paper, we propose a segmentation framework called ErrorNet, which learns to correct these segmentation mistakes through the repeated process of injecting systematic segmentation errors to a segmentation mask based on a learned shape prior, followed by attempting to predict the injected error. During inference, ErrorNet corrects the segmentation mistakes by adding the predicted error map to the initial segmentation mask. ErrorNet has advantages over alternatives based on domain adaptation or CRF-based post processing, because it requires neither domain-specific parameter tuning nor any data from the target domains. We have evaluated ErrorNet using five public datasets for the task of retinal vessel segmentation. The selected datasets differ in size and patient population, allowing us to evaluate the effectiveness of ErrorNet in handling small sample size and domain shift problems. Our experiments demonstrate that ErrorNet outperforms a base segmentation model, a CRF-based post processing scheme, and a domain adaptation method, with a greater performance gain in the presence of dataset limitations above.