 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConverting Artificial Neural Networks to Spiking Neural Networks via Parameter Calibration
May 06, 2022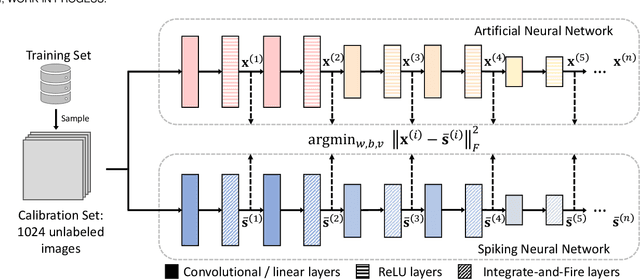

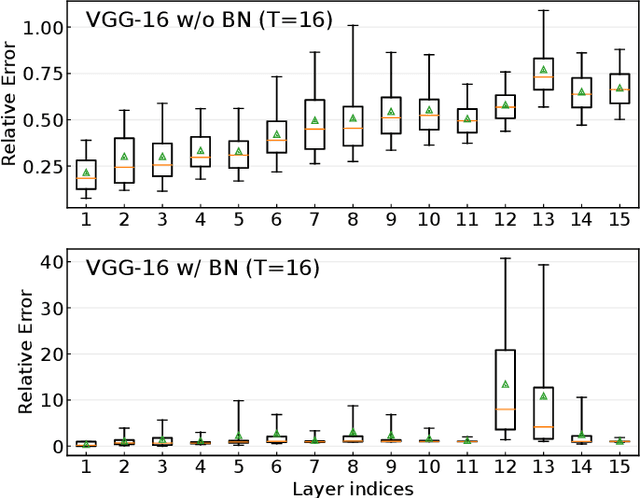
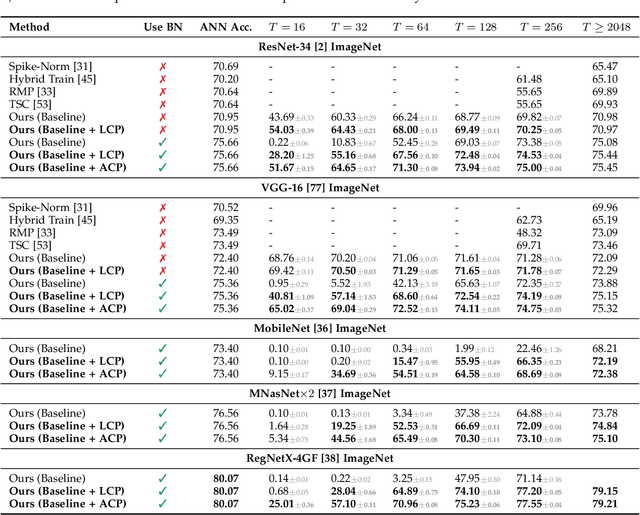
Spiking Neural Network (SNN), originating from the neural behavior in biology, has been recognized as one of the next-generation neural networks. Conventionally, SNNs can be obtained by converting from pre-trained Artificial Neural Networks (ANNs) by replacing the non-linear activation with spiking neurons without changing the parameters. In this work, we argue that simply copying and pasting the weights of ANN to SNN inevitably results in activation mismatch, especially for ANNs that are trained with batch normalization (BN) layers. To tackle the activation mismatch issue, we first provide a theoretical analysis by decomposing local conversion error to clipping error and flooring error, and then quantitatively measure how this error propagates throughout the layers using the second-order analysis. Motivated by the theoretical results, we propose a set of layer-wise parameter calibration algorithms, which adjusts the parameters to minimize the activation mismatch. Extensive experiments for the proposed algorithms are performed on modern architectures and large-scale tasks including ImageNet classification and MS COCO detection. We demonstrate that our method can handle the SNN conversion with batch normalization layers and effectively preserve the high accuracy even in 32 time steps. For example, our calibration algorithms can increase up to 65% accuracy when converting VGG-16 with BN layers.
Temporal Efficient Training of Spiking Neural Network via Gradient Re-weighting
Feb 24, 2022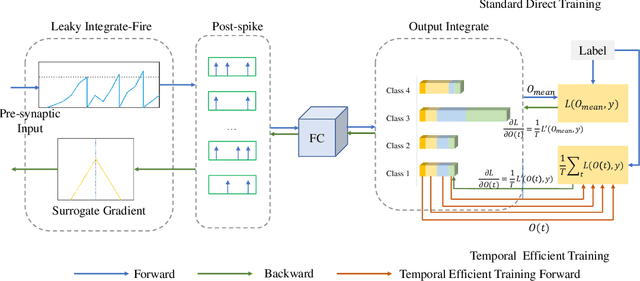
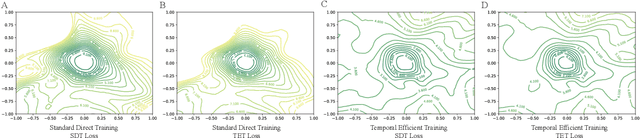
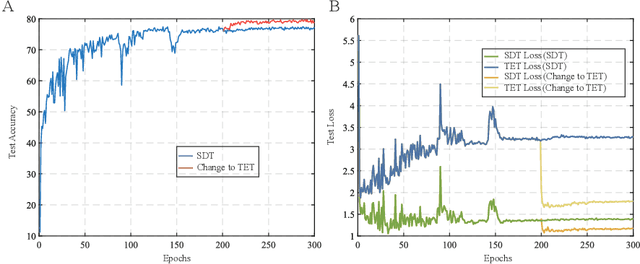
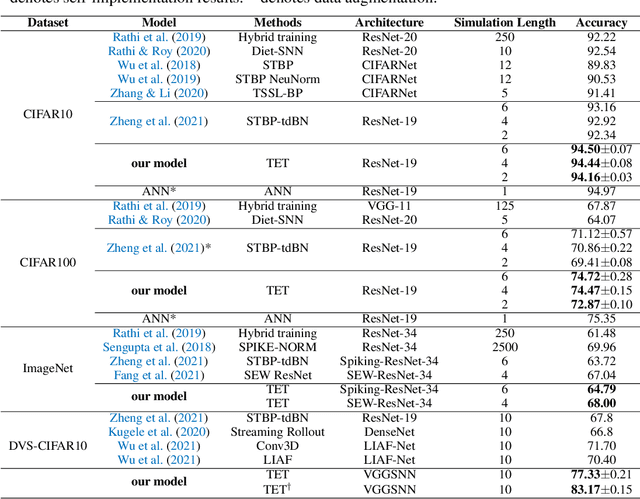
Recently, brain-inspired spiking neuron networks (SNNs) have attracted widespread research interest because of their event-driven and energy-efficient characteristics. Still, it is difficult to efficiently train deep SNNs due to the non-differentiability of its activation function, which disables the typically used gradient descent approaches for traditional artificial neural networks (ANNs). Although the adoption of surrogate gradient (SG) formally allows for the back-propagation of losses, the discrete spiking mechanism actually differentiates the loss landscape of SNNs from that of ANNs, failing the surrogate gradient methods to achieve comparable accuracy as for ANNs. In this paper, we first analyze why the current direct training approach with surrogate gradient results in SNNs with poor generalizability. Then we introduce the temporal efficient training (TET) approach to compensate for the loss of momentum in the gradient descent with SG so that the training process can converge into flatter minima with better generalizability. Meanwhile, we demonstrate that TET improves the temporal scalability of SNN and induces a temporal inheritable training for acceleration. Our method consistently outperforms the SOTA on all reported mainstream datasets, including CIFAR-10/100 and ImageNet. Remarkably on DVS-CIFAR10, we obtained 83$\%$ top-1 accuracy, over 10$\%$ improvement compared to existing state of the art. Codes are available at \url{https://github.com/Gus-Lab/temporal_efficient_training}.
A Free Lunch From ANN: Towards Efficient, Accurate Spiking Neural Networks Calibration
Jun 13, 2021
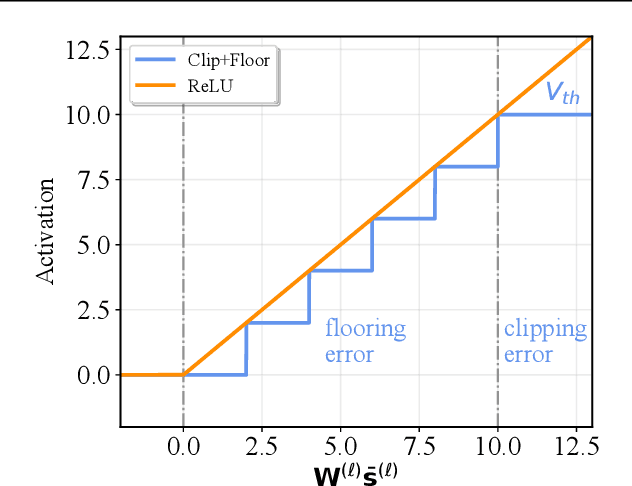
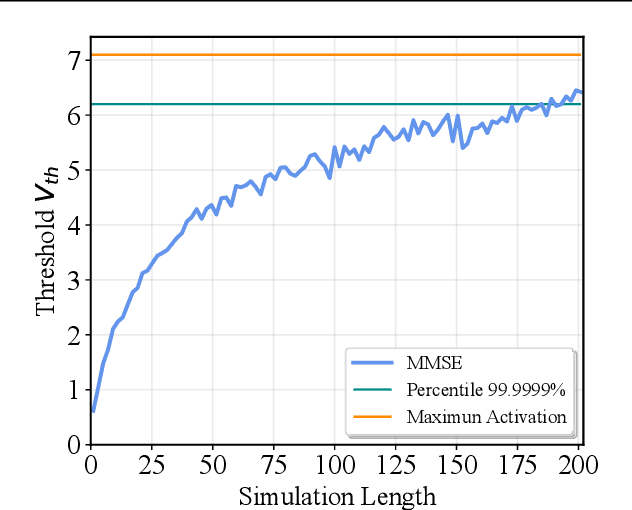
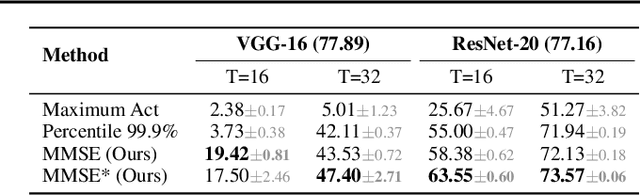
Spiking Neural Network (SNN) has been recognized as one of the next generation of neural networks. Conventionally, SNN can be converted from a pre-trained ANN by only replacing the ReLU activation to spike activation while keeping the parameters intact. Perhaps surprisingly, in this work we show that a proper way to calibrate the parameters during the conversion of ANN to SNN can bring significant improvements. We introduce SNN Calibration, a cheap but extraordinarily effective method by leveraging the knowledge within a pre-trained Artificial Neural Network (ANN). Starting by analyzing the conversion error and its propagation through layers theoretically, we propose the calibration algorithm that can correct the error layer-by-layer. The calibration only takes a handful number of training data and several minutes to finish. Moreover, our calibration algorithm can produce SNN with state-of-the-art architecture on the large-scale ImageNet dataset, including MobileNet and RegNet. Extensive experiments demonstrate the effectiveness and efficiency of our algorithm. For example, our advanced pipeline can increase up to 69% top-1 accuracy when converting MobileNet on ImageNet compared to baselines. Codes are released at https://github.com/yhhhli/SNN_Calibration.
Optimal Conversion of Conventional Artificial Neural Networks to Spiking Neural Networks
Feb 28, 2021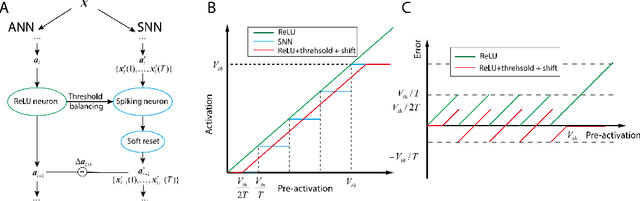
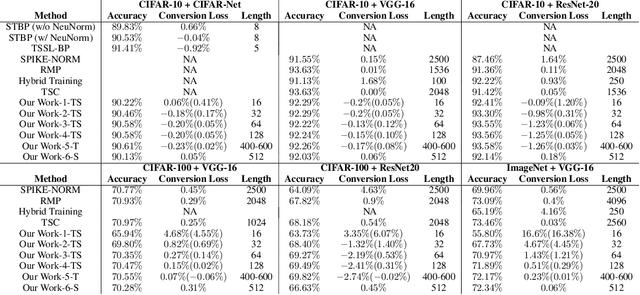
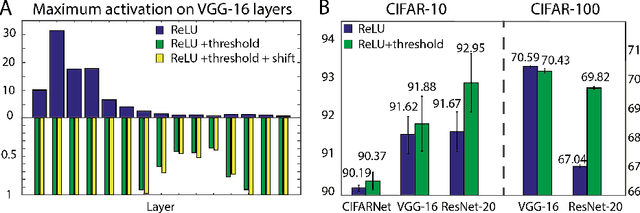
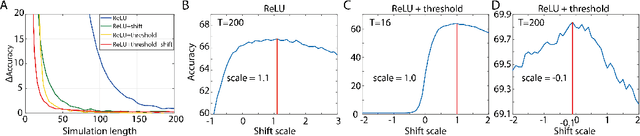
Spiking neural networks (SNNs) are biology-inspired artificial neural networks (ANNs) that comprise of spiking neurons to process asynchronous discrete signals. While more efficient in power consumption and inference speed on the neuromorphic hardware, SNNs are usually difficult to train directly from scratch with spikes due to the discreteness. As an alternative, many efforts have been devoted to converting conventional ANNs into SNNs by copying the weights from ANNs and adjusting the spiking threshold potential of neurons in SNNs. Researchers have designed new SNN architectures and conversion algorithms to diminish the conversion error. However, an effective conversion should address the difference between the SNN and ANN architectures with an efficient approximation \DSK{of} the loss function, which is missing in the field. In this work, we analyze the conversion error by recursive reduction to layer-wise summation and propose a novel strategic pipeline that transfers the weights to the target SNN by combining threshold balance and soft-reset mechanisms. This pipeline enables almost no accuracy loss between the converted SNNs and conventional ANNs with only $\sim1/10$ of the typical SNN simulation time. Our method is promising to get implanted onto embedded platforms with better support of SNNs with limited energy and memory.