 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBMPQ: Bit-Gradient Sensitivity Driven Mixed-Precision Quantization of DNNs from Scratch
Dec 24, 2021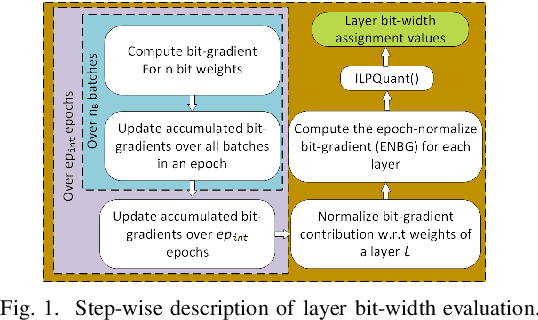
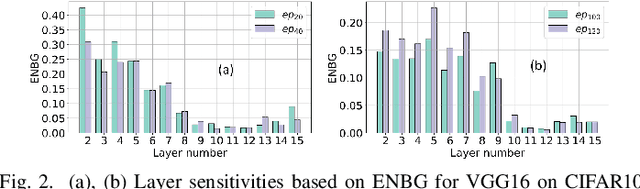
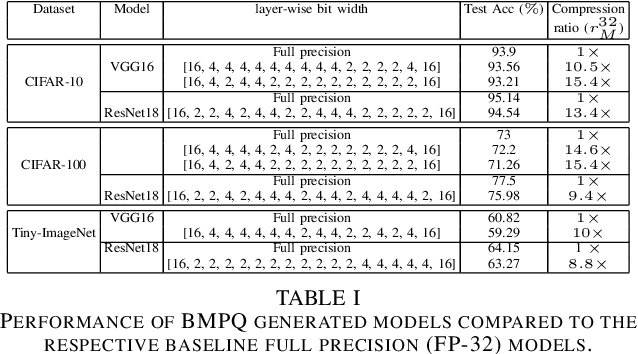
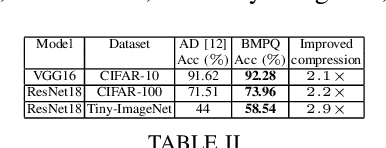
Large DNNs with mixed-precision quantization can achieve ultra-high compression while retaining high classification performance. However, because of the challenges in finding an accurate metric that can guide the optimization process, these methods either sacrifice significant performance compared to the 32-bit floating-point (FP-32) baseline or rely on a compute-expensive, iterative training policy that requires the availability of a pre-trained baseline. To address this issue, this paper presents BMPQ, a training method that uses bit gradients to analyze layer sensitivities and yield mixed-precision quantized models. BMPQ requires a single training iteration but does not need a pre-trained baseline. It uses an integer linear program (ILP) to dynamically adjust the precision of layers during training, subject to a fixed hardware budget. To evaluate the efficacy of BMPQ, we conduct extensive experiments with VGG16 and ResNet18 on CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets. Compared to the baseline FP-32 models, BMPQ can yield models that have 15.4x fewer parameter bits with a negligible drop in accuracy. Compared to the SOTA "during training", mixed-precision training scheme, our models are 2.1x, 2.2x, and 2.9x smaller, on CIFAR-10, CIFAR-100, and Tiny-ImageNet, respectively, with an improved accuracy of up to 14.54%.