 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Robustness Verification for Spatio-Temporal Neural Networks
Jun 08, 2026With AI increasingly deployed in safety-critical systems, providing formal robustness guarantees for the underlying models is essential. Existing verification methods either rely on overly conservative approximations or incur prohibitive computational costs. For example, the use of lp-norm perturbations in video settings encodes the belief that the adversary can inject noise in every video frame. In practice, adversarial perturbations exhibit structured spatial and temporal correlations, constrained to lower-dimensional, semantically meaningful subspaces. In this work, we study robustness verification of 3D CNNs processing video and volumetric inputs, targeting applications in action recognition (UCF-101), autonomous driving (Udacity), and medical imaging (MedMNIST) exploiting realistic assumptions on adversarial strength by modelling them as spatio-temporal constraints - where the attacker can modify either a subset of frames or patches within a set of consecutive frames. We demonstrate that modelling realistic constraints enables tighter approximations. We introduce Spatio-Temporal Bound Propagation (STBP), a verification framework that computes an exact closed-form characterization of the first convolutional layer and propagates certified bounds through subsequent layers using scalable approximations. Computing the exact closed form provides the tightest bounds for the first convolutional layer. Thus, we utilise approximation methods in the remainder of the network. To spur further progress in this field, we propose ST-Bench, a verification benchmark for autonomous driving and activity recognition, to systematically evaluate verifiable robustness. Compared to existing verification-based approaches, STBP provides stronger robustness guarantees with significantly improved scalability, achieving 1.7x higher certified robust accuracy under identical perturbation budgets.
A Scalable Approach to Probabilistic Neuro-Symbolic Verification
Feb 05, 2025



Neuro-Symbolic Artificial Intelligence (NeSy AI) has emerged as a promising direction for integrating neural learning with symbolic reasoning. In the probabilistic variant of such systems, a neural network first extracts a set of symbols from sub-symbolic input, which are then used by a symbolic component to reason in a probabilistic manner towards answering a query. In this work, we address the problem of formally verifying the robustness of such NeSy probabilistic reasoning systems, therefore paving the way for their safe deployment in critical domains. We analyze the complexity of solving this problem exactly, and show that it is $\mathrm{NP}^{\# \mathrm{P}}$-hard. To overcome this issue, we propose the first approach for approximate, relaxation-based verification of probabilistic NeSy systems. We demonstrate experimentally that the proposed method scales exponentially better than solver-based solutions and apply our technique to a real-world autonomous driving dataset, where we verify a safety property under large input dimensionalities and network sizes.
Efficient support ticket resolution using Knowledge Graphs
Dec 31, 2024

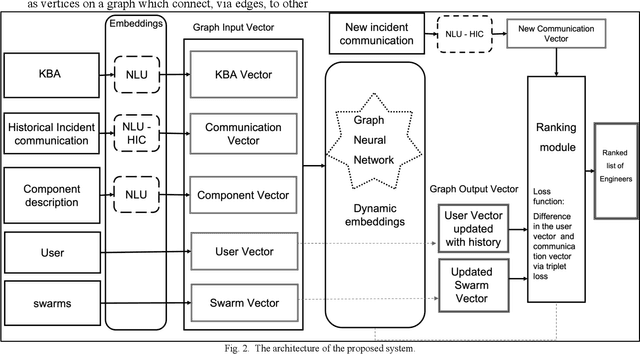

A review of over 160,000 customer cases indicates that about 90% of time is spent by the product support for solving around 10% of subset of tickets where a trivial solution may not exist. Many of these challenging cases require the support of several engineers working together within a "swarm", and some also need to go to development support as bugs. These challenging customer issues represent a major opportunity for machine learning and knowledge graph that identifies the ideal engineer / group of engineers(swarm) that can best address the solution, reducing the wait times for the customer. The concrete ML task we consider here is a learning-to-rank(LTR) task that given an incident and a set of engineers currently assigned to the incident (which might be the empty set in the non-swarming context), produce a ranked list of engineers best fit to help resolve that incident. To calculate the rankings, we may consider a wide variety of input features including the incident description provided by the customer, the affected component(s), engineer ratings of their expertise, knowledge base article text written by engineers, response to customer text written by engineers, and historic swarming data. The central hypothesis test is that by including a holistic set of contextual data around which cases an engineer has solved, we can significantly improve the LTR algorithm over benchmark models. The article proposes a novel approach of modelling Knowledge Graph embeddings from multiple data sources, including the swarm information. The results obtained proves that by incorporating this additional context, we can improve the recommendations significantly over traditional machine learning methods like TF-IDF.