 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Efficient support ticket resolution using Knowledge Graphs
Dec 31, 2024

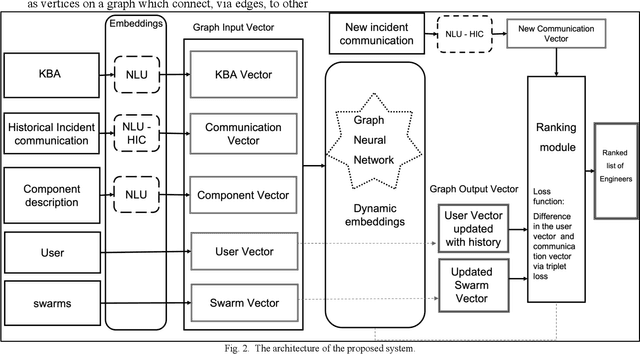

A review of over 160,000 customer cases indicates that about 90% of time is spent by the product support for solving around 10% of subset of tickets where a trivial solution may not exist. Many of these challenging cases require the support of several engineers working together within a "swarm", and some also need to go to development support as bugs. These challenging customer issues represent a major opportunity for machine learning and knowledge graph that identifies the ideal engineer / group of engineers(swarm) that can best address the solution, reducing the wait times for the customer. The concrete ML task we consider here is a learning-to-rank(LTR) task that given an incident and a set of engineers currently assigned to the incident (which might be the empty set in the non-swarming context), produce a ranked list of engineers best fit to help resolve that incident. To calculate the rankings, we may consider a wide variety of input features including the incident description provided by the customer, the affected component(s), engineer ratings of their expertise, knowledge base article text written by engineers, response to customer text written by engineers, and historic swarming data. The central hypothesis test is that by including a holistic set of contextual data around which cases an engineer has solved, we can significantly improve the LTR algorithm over benchmark models. The article proposes a novel approach of modelling Knowledge Graph embeddings from multiple data sources, including the swarm information. The results obtained proves that by incorporating this additional context, we can improve the recommendations significantly over traditional machine learning methods like TF-IDF.
Conditional mean embeddings and optimal feature selection via positive definite kernels
May 14, 2023


Motivated by applications, we consider here new operator theoretic approaches to Conditional mean embeddings (CME). Our present results combine a spectral analysis-based optimization scheme with the use of kernels, stochastic processes, and constructive learning algorithms. For initially given non-linear data, we consider optimization-based feature selections. This entails the use of convex sets of positive definite (p.d.) kernels in a construction of optimal feature selection via regression algorithms from learning models. Thus, with initial inputs of training data (for a suitable learning algorithm,) each choice of p.d. kernel $K$ in turn yields a variety of Hilbert spaces and realizations of features. A novel idea here is that we shall allow an optimization over selected sets of kernels $K$ from a convex set $C$ of positive definite kernels $K$. Hence our \textquotedblleft optimal\textquotedblright{} choices of feature representations will depend on a secondary optimization over p.d. kernels $K$ within a specified convex set $C$.
Operator theory, kernels, and Feedforward Neural Networks
Jan 05, 2023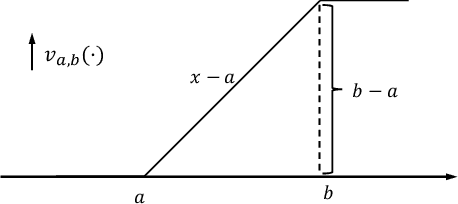
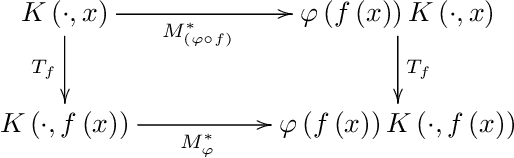
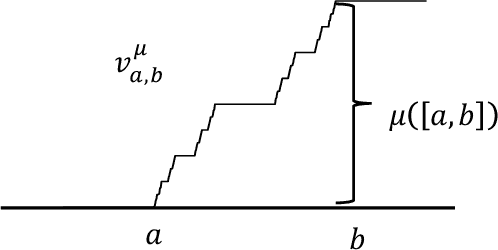

In this paper we show how specific families of positive definite kernels serve as powerful tools in analyses of iteration algorithms for multiple layer feedforward Neural Network models. Our focus is on particular kernels that adapt well to learning algorithms for data-sets/features which display intrinsic self-similarities at feedforward iterations of scaling.