 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom 3D Pose to Prose: Biomechanics-Grounded Vision--Language Coaching
Mar 27, 2026We present BioCoach, a biomechanics-grounded vision--language framework for fitness coaching from streaming video. BioCoach fuses visual appearance and 3D skeletal kinematics, through a novel three-stage pipeline: an exercise-specific degree-of-freedom selector that focuses analysis on salient joints; a structured biomechanical context that pairs individualized morphometrics with cycle and constraint analysis; and a vision--biomechanics conditioned feedback module that applies cross-attention to generate precise, actionable text. Using parameter-efficient training that freezes the vision and language backbones, BioCoach yields transparent, personalized reasoning rather than pattern matching. To enable learning and fair evaluation, we augment QEVD-fit-coach with biomechanics-oriented feedback to create QEVD-bio-fit-coach, and we introduce a biomechanics-aware LLM judge metric. BioCoach delivers clear gains on QEVD-bio-fit-coach across lexical and judgment metrics while maintaining temporal triggering; on the original QEVD-fit-coach, it improves text quality and correctness with near-parity timing, demonstrating that explicit kinematics and constraints are key to accurate, phase-aware coaching.
RePLAy: Remove Projective LiDAR Depthmap Artifacts via Exploiting Epipolar Geometry
Jul 27, 2024



3D sensing is a fundamental task for Autonomous Vehicles. Its deployment often relies on aligned RGB cameras and LiDAR. Despite meticulous synchronization and calibration, systematic misalignment persists in LiDAR projected depthmap. This is due to the physical baseline distance between the two sensors. The artifact is often reflected as background LiDAR incorrectly projected onto the foreground, such as cars and pedestrians. The KITTI dataset uses stereo cameras as a heuristic solution to remove artifacts. However most AV datasets, including nuScenes, Waymo, and DDAD, lack stereo images, making the KITTI solution inapplicable. We propose RePLAy, a parameter-free analytical solution to remove the projective artifacts. We construct a binocular vision system between a hypothesized virtual LiDAR camera and the RGB camera. We then remove the projective artifacts by determining the epipolar occlusion with the proposed analytical solution. We show unanimous improvement in the State-of-The-Art (SoTA) monocular depth estimators and 3D object detectors with the artifacts-free depthmaps.
Revisit Self-supervised Depth Estimation with Local Structure-from-Motion
Jul 27, 2024



Both self-supervised depth estimation and Structure-from-Motion (SfM) recover scene depth from RGB videos. Despite sharing a similar objective, the two approaches are disconnected. Prior works of self-supervision backpropagate losses defined within immediate neighboring frames. Instead of learning-through-loss, this work proposes an alternative scheme by performing local SfM. First, with calibrated RGB or RGB-D images, we employ a depth and correspondence estimator to infer depthmaps and pair-wise correspondence maps. Then, a novel bundle-RANSAC-adjustment algorithm jointly optimizes camera poses and one depth adjustment for each depthmap. Finally, we fix camera poses and employ a NeRF, however, without a neural network, for dense triangulation and geometric verification. Poses, depth adjustments, and triangulated sparse depths are our outputs. For the first time, we show self-supervision within $5$ frames already benefits SoTA supervised depth and correspondence models.
Tame a Wild Camera: In-the-Wild Monocular Camera Calibration
Jun 19, 2023



3D sensing for monocular in-the-wild images, e.g., depth estimation and 3D object detection, has become increasingly important. However, the unknown intrinsic parameter hinders their development and deployment. Previous methods for the monocular camera calibration rely on specific 3D objects or strong geometry prior, such as using a checkerboard or imposing a Manhattan World assumption. This work solves the problem from the other perspective by exploiting the monocular 3D prior. Our method is assumption-free and calibrates the complete $4$ Degree-of-Freedom (DoF) intrinsic parameters. First, we demonstrate intrinsic is solved from two well-studied monocular priors, i.e., monocular depthmap, and surface normal map. However, this solution imposes a low-bias and low-variance requirement for depth estimation. Alternatively, we introduce a novel monocular 3D prior, the incidence field, defined as the incidence rays between points in 3D space and pixels in the 2D imaging plane. The incidence field is a pixel-wise parametrization of the intrinsic invariant to image cropping and resizing. With the estimated incidence field, a robust RANSAC algorithm recovers intrinsic. We demonstrate the effectiveness of our method by showing superior performance on synthetic and zero-shot testing datasets. Beyond calibration, we demonstrate downstream applications in image manipulation detection & restoration, uncalibrated two-view pose estimation, and 3D sensing. Codes, models, and data will be held in https://github.com/ShngJZ/WildCamera.
PMatch: Paired Masked Image Modeling for Dense Geometric Matching
Mar 30, 2023

Dense geometric matching determines the dense pixel-wise correspondence between a source and support image corresponding to the same 3D structure. Prior works employ an encoder of transformer blocks to correlate the two-frame features. However, existing monocular pretraining tasks, e.g., image classification, and masked image modeling (MIM), can not pretrain the cross-frame module, yielding less optimal performance. To resolve this, we reformulate the MIM from reconstructing a single masked image to reconstructing a pair of masked images, enabling the pretraining of transformer module. Additionally, we incorporate a decoder into pretraining for improved upsampling results. Further, to be robust to the textureless area, we propose a novel cross-frame global matching module (CFGM). Since the most textureless area is planar surfaces, we propose a homography loss to further regularize its learning. Combined together, we achieve the State-of-The-Art (SoTA) performance on geometric matching. Codes and models are available at https://github.com/ShngJZ/PMatch.
The Edge of Depth: Explicit Constraints between Segmentation and Depth
Apr 01, 2020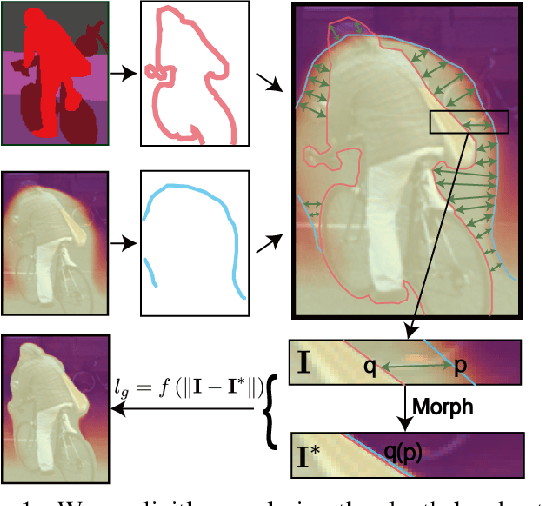
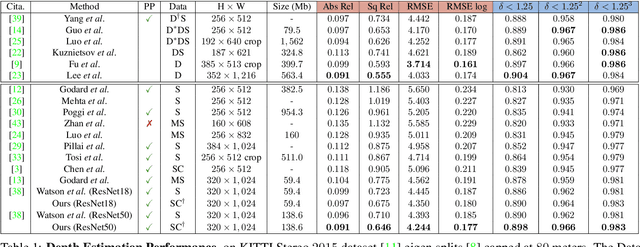
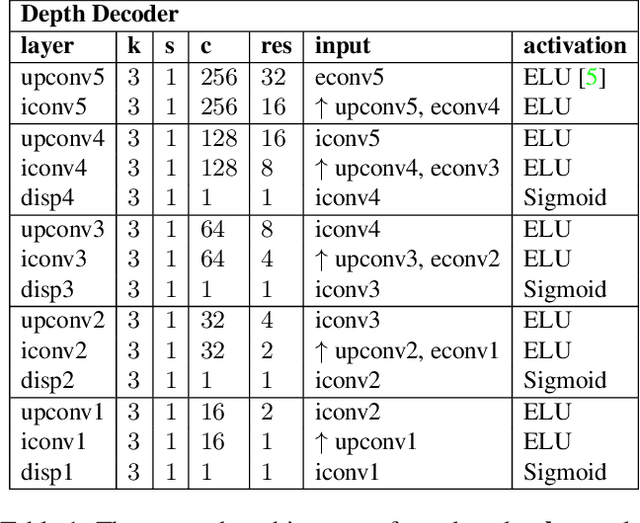
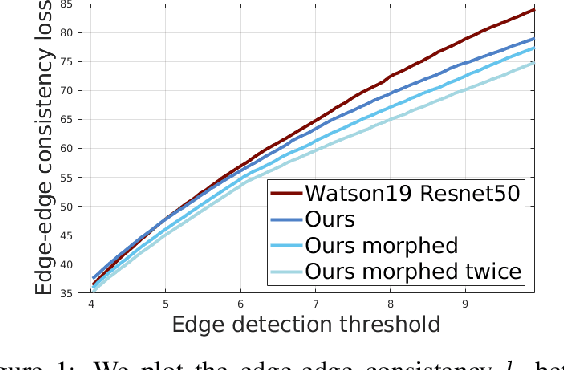
In this work we study the mutual benefits of two common computer vision tasks, self-supervised depth estimation and semantic segmentation from images. For example, to help unsupervised monocular depth estimation, constraints from semantic segmentation has been explored implicitly such as sharing and transforming features. In contrast, we propose to explicitly measure the border consistency between segmentation and depth and minimize it in a greedy manner by iteratively supervising the network towards a locally optimal solution. Partially this is motivated by our observation that semantic segmentation even trained with limited ground truth (200 images of KITTI) can offer more accurate border than that of any (monocular or stereo) image-based depth estimation. Through extensive experiments, our proposed approach advances the state of the art on unsupervised monocular depth estimation in the KITTI.