 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseSpikformer: A Co-Design Framework for Token and Weight Pruning in Spiking Transformer
Nov 15, 2023As the third-generation neural network, the Spiking Neural Network (SNN) has the advantages of low power consumption and high energy efficiency, making it suitable for implementation on edge devices. More recently, the most advanced SNN, Spikformer, combines the self-attention module from Transformer with SNN to achieve remarkable performance. However, it adopts larger channel dimensions in MLP layers, leading to an increased number of redundant model parameters. To effectively decrease the computational complexity and weight parameters of the model, we explore the Lottery Ticket Hypothesis (LTH) and discover a very sparse ($\ge$90%) subnetwork that achieves comparable performance to the original network. Furthermore, we also design a lightweight token selector module, which can remove unimportant background information from images based on the average spike firing rate of neurons, selecting only essential foreground image tokens to participate in attention calculation. Based on that, we present SparseSpikformer, a co-design framework aimed at achieving sparsity in Spikformer through token and weight pruning techniques. Experimental results demonstrate that our framework can significantly reduce 90% model parameters and cut down Giga Floating-Point Operations (GFLOPs) by 20% while maintaining the accuracy of the original model.
SPA: Stochastic Probability Adjustment for System Balance of Unsupervised SNNs
Oct 19, 2020
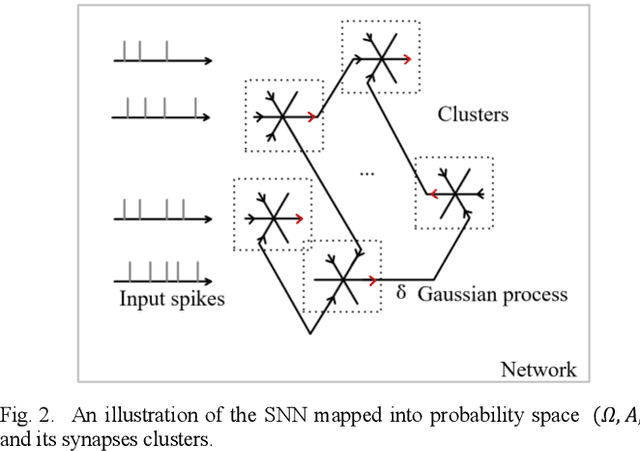
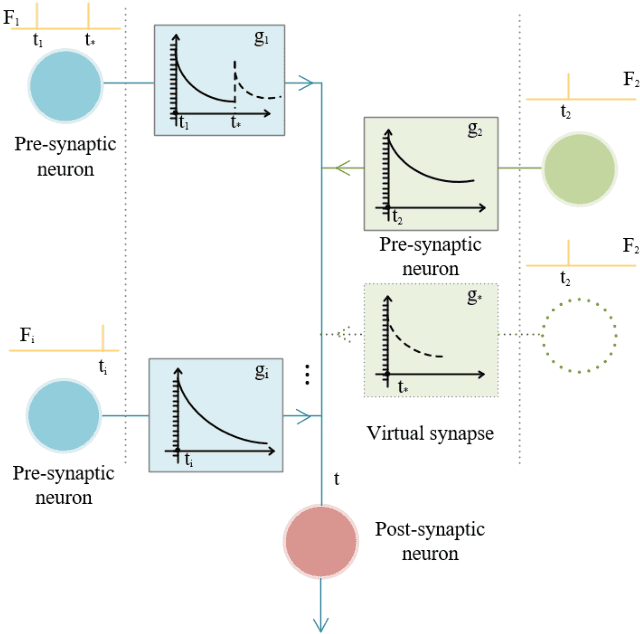
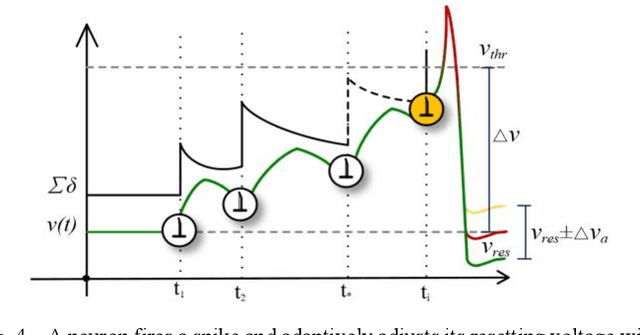
Spiking neural networks (SNNs) receive widespread attention because of their low-power hardware characteristic and brain-like signal response mechanism, but currently, the performance of SNNs is still behind Artificial Neural Networks (ANNs). We build an information theory-inspired system called Stochastic Probability Adjustment (SPA) system to reduce this gap. The SPA maps the synapses and neurons of SNNs into a probability space where a neuron and all connected pre-synapses are represented by a cluster. The movement of synaptic transmitter between different clusters is modeled as a Brownian-like stochastic process in which the transmitter distribution is adaptive at different firing phases. We experimented with a wide range of existing unsupervised SNN architectures and achieved consistent performance improvements. The improvements in classification accuracy have reached 1.99% and 6.29% on the MNIST and EMNIST datasets respectively.
Spiking Inception Module for Multi-layer Unsupervised Spiking Neural Networks
Feb 14, 2020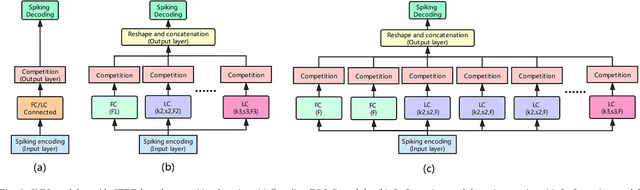
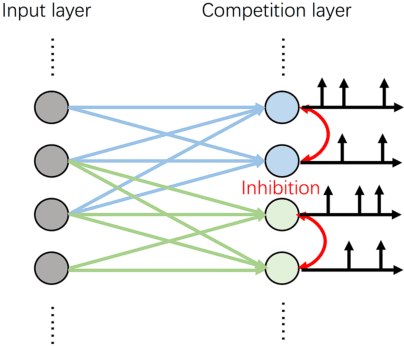
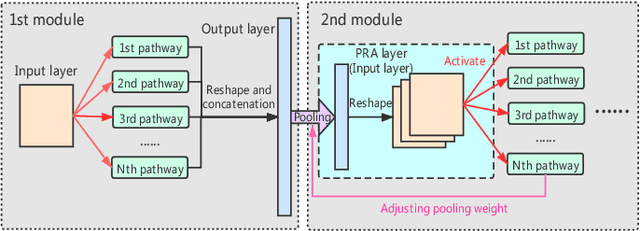
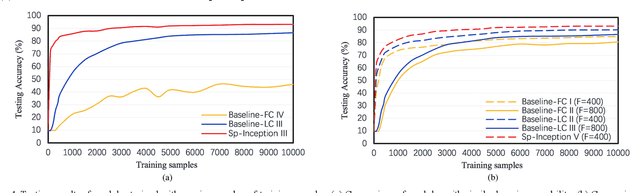
Spiking Neural Network (SNN), as a brain-inspired approach, is attracting attentions due to its potential to produce ultra-high-energy-efficient hardware. Competitive learning based on Spike-Timing-Dependent Plasticity (STDP) is a popular method to train unsupervised SNN. However, previous unsupervised SNNs trained through this method are limited to shallow networks with only one learnable layer and can't achieve satisfactory results when compared with multi-layer SNNs. In this paper, we ease this limitation by: 1)We propose Spiking Inception (Sp-Inception) module, inspired by the Inception module in Artificial Neural Network (ANN) literature. This module is trained through STDP- based competitive learning and outperforms baseline modules on learning capability, learning efficiency, and robustness; 2)We propose Pooling-Reshape-Activate (PRA) layer to make Sp-Inception module stackable; 3)We stack multiple Sp-Inception modules to construct multi-layer SNNs. Our method greatly exceeds baseline methods on image classification tasks and reaches state-of-the-art results on MNIST dataset among existing unsupervised SNNs.
BioSNet: A Fast-Learning and High-Robustness Unsupervised Biomimetic Spiking Neural Network
Jan 18, 2020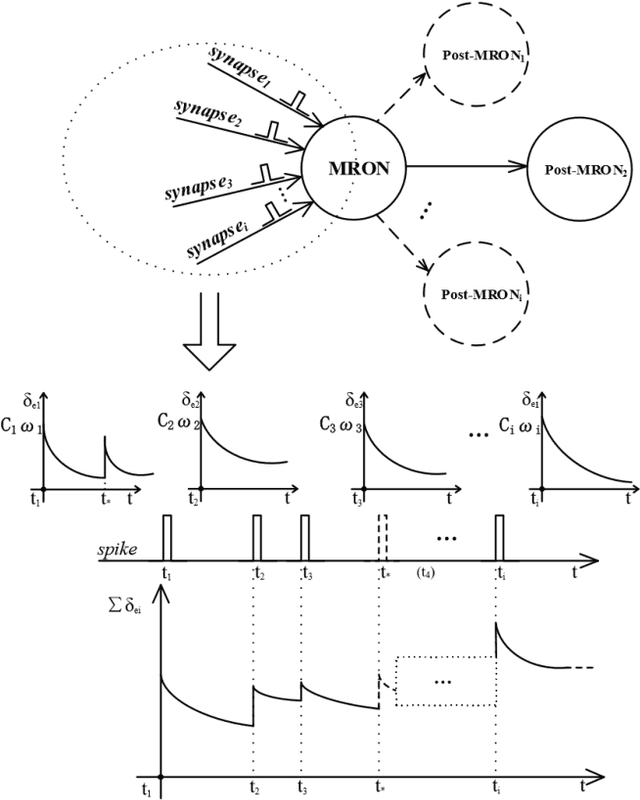
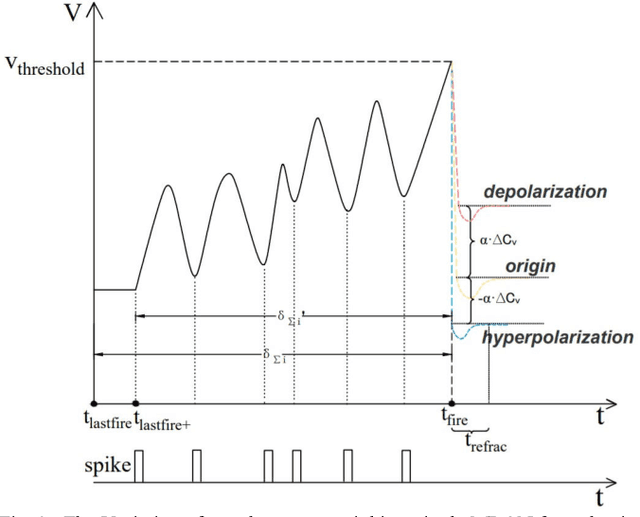
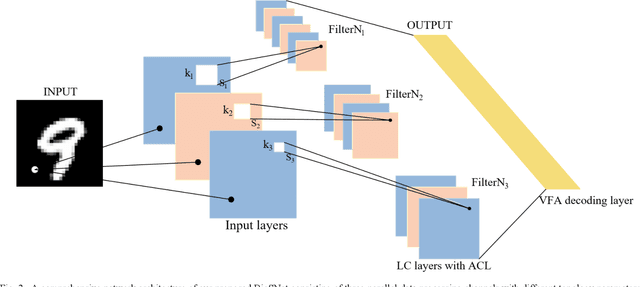
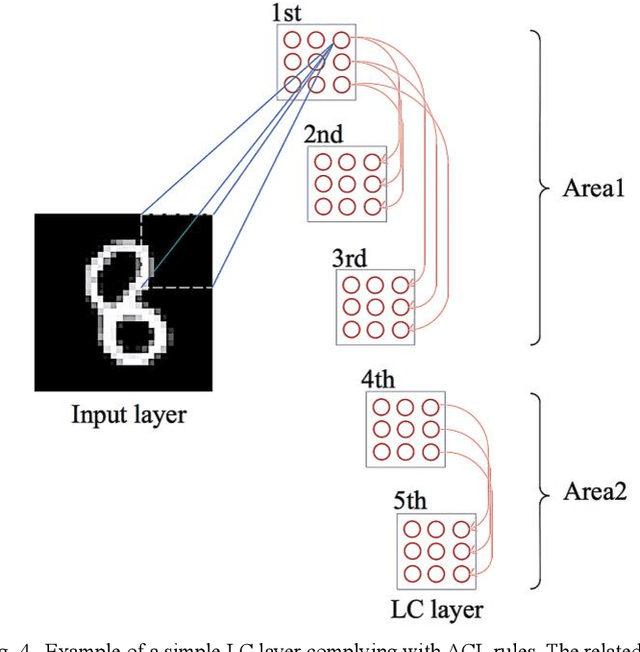
Spiking Neural Network (SNN), as a brain-inspired machine learning algorithm, is closer to the computing mechanism of human brain and more suitable to reveal the essence of intelligence compared with Artificial Neural Networks (ANN), attracting more and more attention in recent years. In addition, the information processed by SNN is in the form of discrete spikes, which makes SNN have low power consumption characteristics. In this paper, we propose an efficient and strong unsupervised SNN named BioSNet with high biological plausibility to handle image classification tasks. In BioSNet, we propose a new biomimetic spiking neuron model named MRON inspired by 'recognition memory' in the human brain, design an efficient and robust network architecture corresponding to biological characteristics of the human brain as well, and extend the traditional voting mechanism to the Vote-for-All (VFA) decoding layer so as to reduce information loss during decoding. Simulation results show that BioSNet not only achieves state-of-the-art unsupervised classification accuracy on MNIST/EMNIST data sets, but also exhibits superior learning efficiency and high robustness. Specifically, the BioSNet trained with only dozens of samples per class can achieve a favorable classification accuracy over 80% and randomly deleting even 95% of synapses or neurons in the BioSNet only leads to slight performance degradation.