 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOOCRep: A Unified Pre-trained Embedding of MOOC Entities
Jul 12, 2021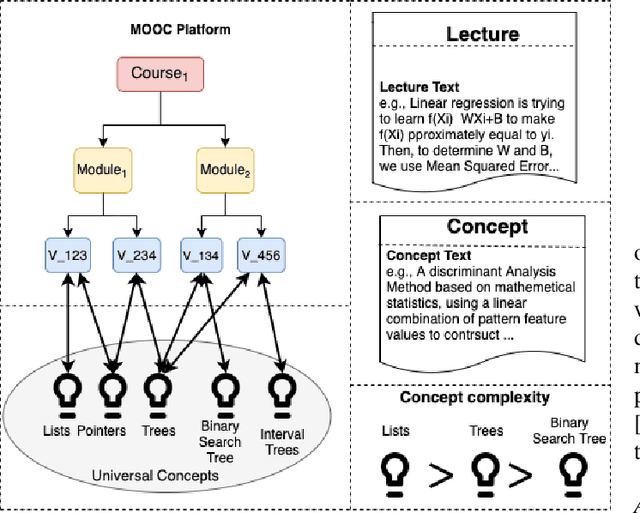
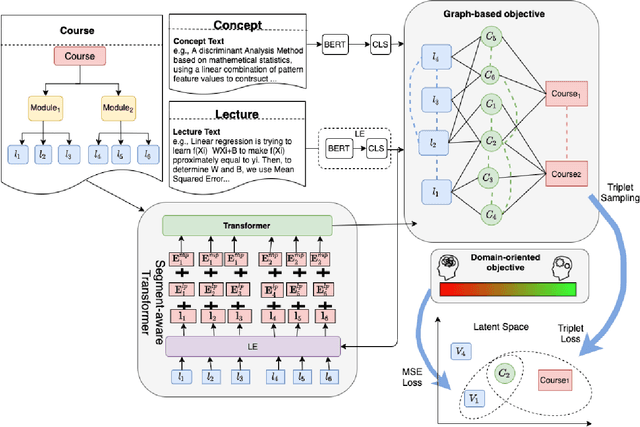
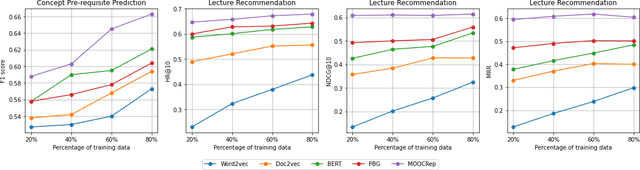

Many machine learning models have been built to tackle information overload issues on Massive Open Online Courses (MOOC) platforms. These models rely on learning powerful representations of MOOC entities. However, they suffer from the problem of scarce expert label data. To overcome this problem, we propose to learn pre-trained representations of MOOC entities using abundant unlabeled data from the structure of MOOCs which can directly be applied to the downstream tasks. While existing pre-training methods have been successful in NLP areas as they learn powerful textual representation, their models do not leverage the richer information about MOOC entities. This richer information includes the graph relationship between the lectures, concepts, and courses along with the domain knowledge about the complexity of a concept. We develop MOOCRep, a novel method based on Transformer language model trained with two pre-training objectives : 1) graph-based objective to capture the powerful signal of entities and relations that exist in the graph, and 2) domain-oriented objective to effectively incorporate the complexity level of concepts. Our experiments reveal that MOOCRep's embeddings outperform state-of-the-art representation learning methods on two tasks important for education community, concept pre-requisite prediction and lecture recommendation.
IACN: Influence-aware and Attention-based Co-evolutionary Network for Recommendation
Mar 04, 2021
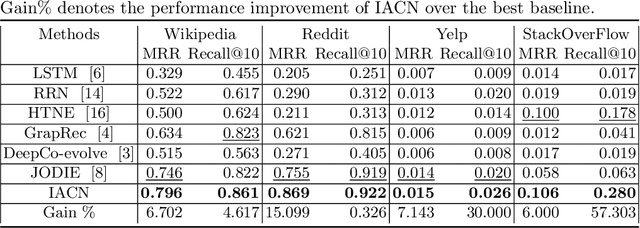
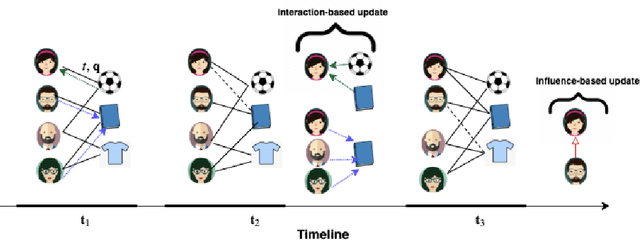

Recommending relevant items to users is a crucial task on online communities such as Reddit and Twitter. For recommendation system, representation learning presents a powerful technique that learns embeddings to represent user behaviors and capture item properties. However, learning embeddings on online communities is a challenging task because the user interest keep evolving. This evolution can be captured from 1) interaction between user and item, 2) influence from other users in the community. The existing dynamic embedding models only consider either of the factors to update user embeddings. However, at a given time, user interest evolves due to a combination of the two factors. To this end, we propose Influence-aware and Attention-based Co-evolutionary Network (IACN). Essentially, IACN consists of two key components: interaction modeling and influence modeling layer. The interaction modeling layer is responsible for updating the embedding of a user and an item when the user interacts with the item. The influence modeling layer captures the temporal excitation caused by interactions of other users. To integrate the signals obtained from the two layers, we design a novel fusion layer that effectively combines interaction-based and influence-based embeddings to predict final user embedding. Our model outperforms the existing state-of-the-art models from various domains.
Learning Student Interest Trajectory for MOOCThread Recommendation
Jan 16, 2021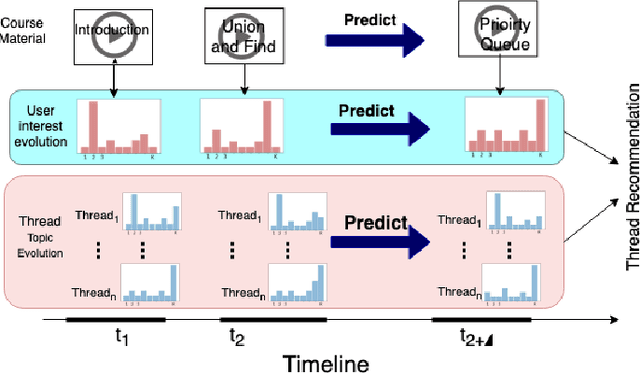
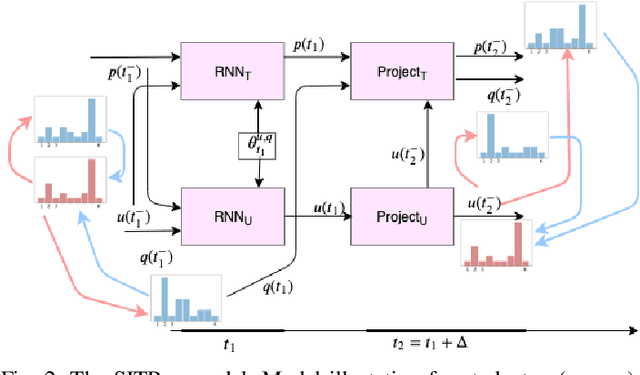
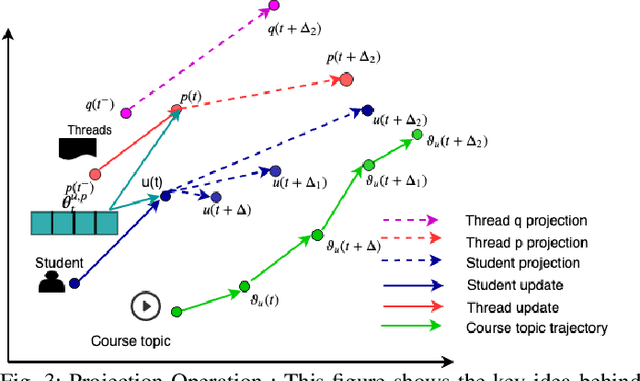
In recent years, Massive Open Online Courses (MOOCs) have witnessed immense growth in popularity. Now, due to the recent Covid19 pandemic situation, it is important to push the limits of online education. Discussion forums are primary means of interaction among learners and instructors. However, with growing class size, students face the challenge of finding useful and informative discussion forums. This problem can be solved by matching the interest of students with thread contents. The fundamental challenge is that the student interests drift as they progress through the course, and forum contents evolve as students or instructors update them. In our paper, we propose to predict future interest trajectories of students. Our model consists of two key operations: 1) Update operation and 2) Projection operation. Update operation models the inter-dependency between the evolution of student and thread using coupled Recurrent Neural Networks when the student posts on the thread. The projection operation learns to estimate future embedding of students and threads. For students, the projection operation learns the drift in their interests caused by the change in the course topic they study. The projection operation for threads exploits how different posts induce varying interest levels in a student according to the thread structure. Extensive experimentation on three real-world MOOC datasets shows that our model significantly outperforms other baselines for thread recommendation.
An Empirical Comparison of Deep Learning Models for Knowledge Tracing on Large-Scale Dataset
Jan 16, 2021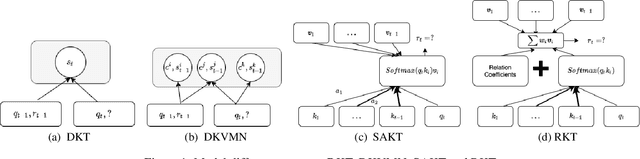
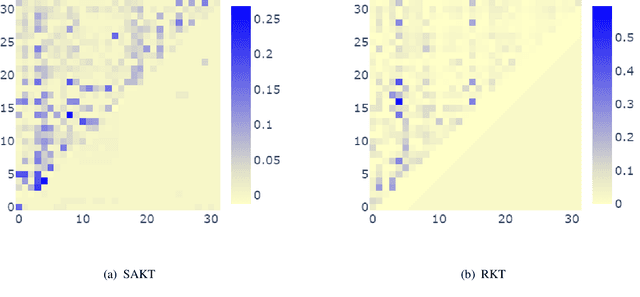
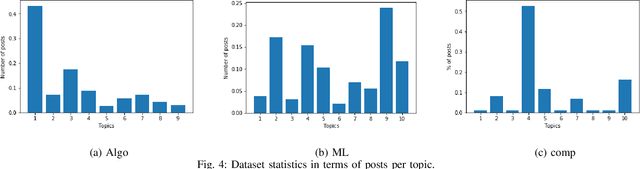
Knowledge tracing (KT) is the problem of modeling each student's mastery of knowledge concepts (KCs) as (s)he engages with a sequence of learning activities. It is an active research area to help provide learners with personalized feedback and materials. Various deep learning techniques have been proposed for solving KT. Recent release of large-scale student performance dataset \cite{choi2019ednet} motivates the analysis of performance of deep learning approaches that have been proposed to solve KT. Our analysis can help understand which method to adopt when large dataset related to student performance is available. We also show that incorporating contextual information such as relation between exercises and student forget behavior further improves the performance of deep learning models.
RKT : Relation-Aware Self-Attention for Knowledge Tracing
Aug 28, 2020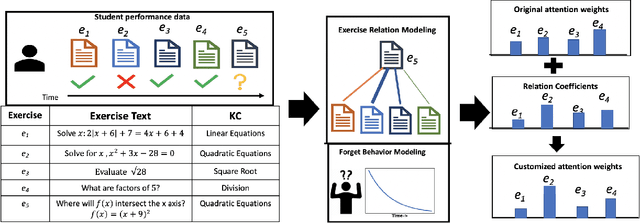
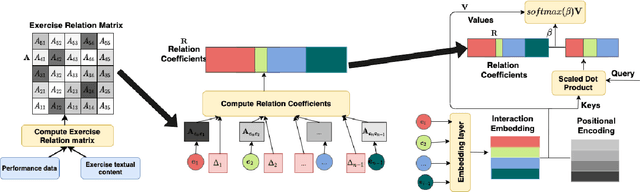
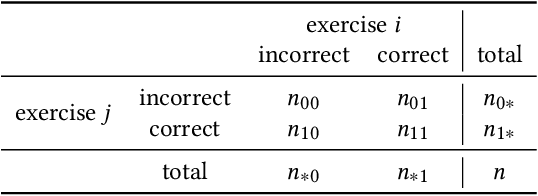
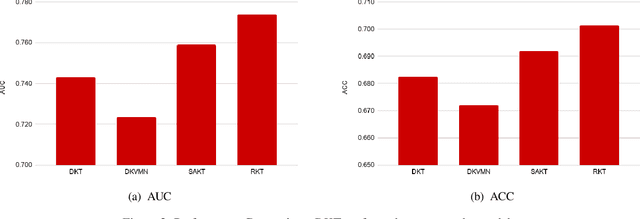
The world has transitioned into a new phase of online learning in response to the recent Covid19 pandemic. Now more than ever, it has become paramount to push the limits of online learning in every manner to keep flourishing the education system. One crucial component of online learning is Knowledge Tracing (KT). The aim of KT is to model student's knowledge level based on their answers to a sequence of exercises referred as interactions. Students acquire their skills while solving exercises and each such interaction has a distinct impact on student ability to solve a future exercise. This \textit{impact} is characterized by 1) the relation between exercises involved in the interactions and 2) student forget behavior. Traditional studies on knowledge tracing do not explicitly model both the components jointly to estimate the impact of these interactions. In this paper, we propose a novel Relation-aware self-attention model for Knowledge Tracing (RKT). We introduce a relation-aware self-attention layer that incorporates the contextual information. This contextual information integrates both the exercise relation information through their textual content as well as student performance data and the forget behavior information through modeling an exponentially decaying kernel function. Extensive experiments on three real-world datasets, among which two new collections are released to the public, show that our model outperforms state-of-the-art knowledge tracing methods. Furthermore, the interpretable attention weights help visualize the relation between interactions and temporal patterns in the human learning process.
A Self-Attentive model for Knowledge Tracing
Jul 16, 2019

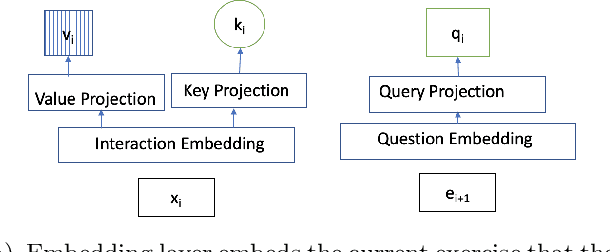
Knowledge tracing is the task of modeling each student's mastery of knowledge concepts (KCs) as (s)he engages with a sequence of learning activities. Each student's knowledge is modeled by estimating the performance of the student on the learning activities. It is an important research area for providing a personalized learning platform to students. In recent years, methods based on Recurrent Neural Networks (RNN) such as Deep Knowledge Tracing (DKT) and Dynamic Key-Value Memory Network (DKVMN) outperformed all the traditional methods because of their ability to capture complex representation of human learning. However, these methods face the issue of not generalizing well while dealing with sparse data which is the case with real-world data as students interact with few KCs. In order to address this issue, we develop an approach that identifies the KCs from the student's past activities that are \textit{relevant} to the given KC and predicts his/her mastery based on the relatively few KCs that it picked. Since predictions are made based on relatively few past activities, it handles the data sparsity problem better than the methods based on RNN. For identifying the relevance between the KCs, we propose a self-attention based approach, Self Attentive Knowledge Tracing (SAKT). Extensive experimentation on a variety of real-world dataset shows that our model outperforms the state-of-the-art models for knowledge tracing, improving AUC by 4.43% on average.