 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOOCRep: A Unified Pre-trained Embedding of MOOC Entities
Paper and Code
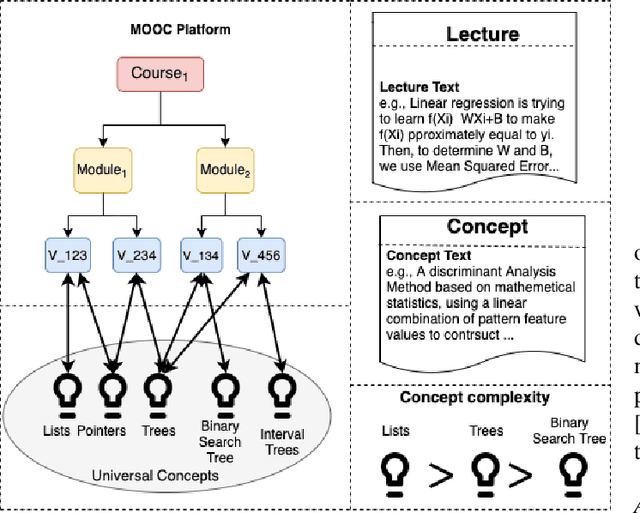
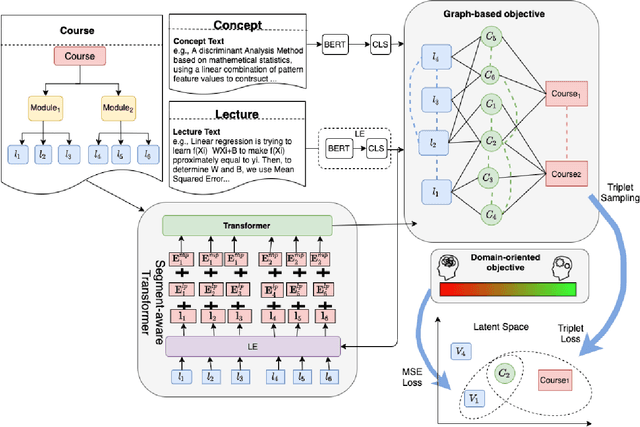
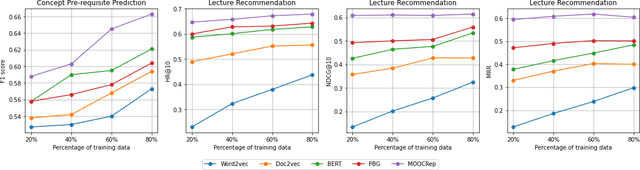

Many machine learning models have been built to tackle information overload issues on Massive Open Online Courses (MOOC) platforms. These models rely on learning powerful representations of MOOC entities. However, they suffer from the problem of scarce expert label data. To overcome this problem, we propose to learn pre-trained representations of MOOC entities using abundant unlabeled data from the structure of MOOCs which can directly be applied to the downstream tasks. While existing pre-training methods have been successful in NLP areas as they learn powerful textual representation, their models do not leverage the richer information about MOOC entities. This richer information includes the graph relationship between the lectures, concepts, and courses along with the domain knowledge about the complexity of a concept. We develop MOOCRep, a novel method based on Transformer language model trained with two pre-training objectives : 1) graph-based objective to capture the powerful signal of entities and relations that exist in the graph, and 2) domain-oriented objective to effectively incorporate the complexity level of concepts. Our experiments reveal that MOOCRep's embeddings outperform state-of-the-art representation learning methods on two tasks important for education community, concept pre-requisite prediction and lecture recommendation.