 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCB Component Detection using Computer Vision for Hardware Assurance
Feb 17, 2022
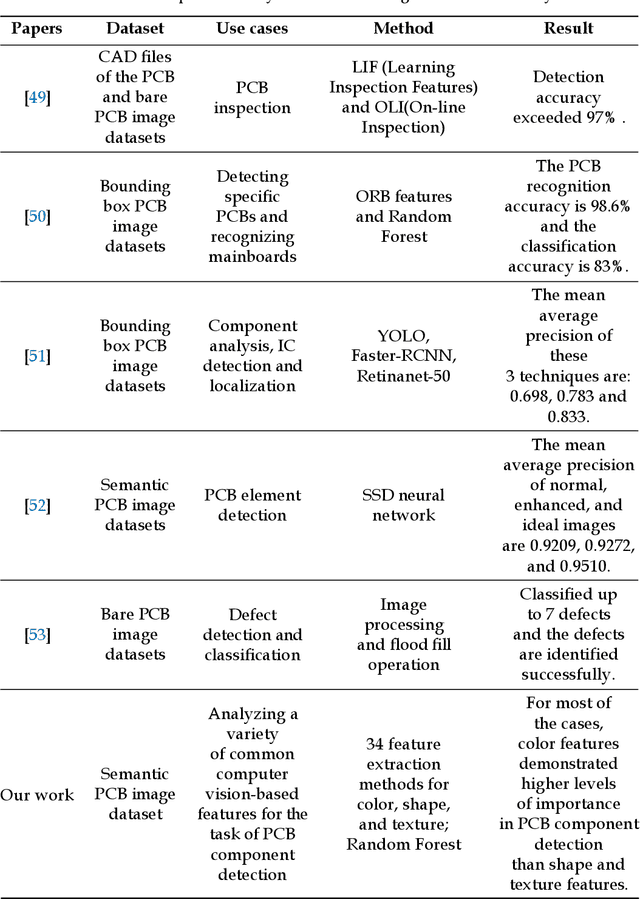
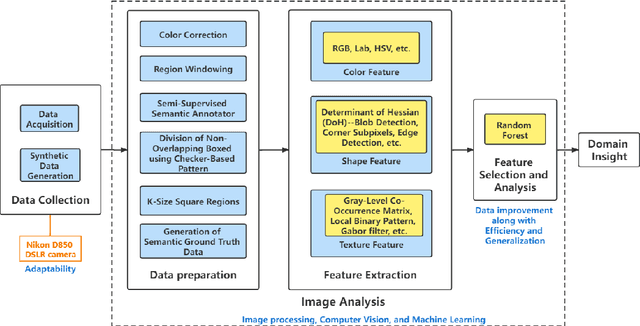
Printed Circuit Board (PCB) assurance in the optical domain is a crucial field of study. Though there are many existing PCB assurance methods using image processing, computer vision (CV), and machine learning (ML), the PCB field is complex and increasingly evolving so new techniques are required to overcome the emerging problems. Existing ML-based methods outperform traditional CV methods, however they often require more data, have low explainability, and can be difficult to adapt when a new technology arises. To overcome these challenges, CV methods can be used in tandem with ML methods. In particular, human-interpretable CV algorithms such as those that extract color, shape, and texture features increase PCB assurance explainability. This allows for incorporation of prior knowledge, which effectively reduce the number of trainable ML parameters and thus, the amount of data needed to achieve high accuracy when training or retraining an ML model. Hence, this study explores the benefits and limitations of a variety of common computer vision-based features for the task of PCB component detection using semantic data. Results of this study indicate that color features demonstrate promising performance for PCB component detection. The purpose of this paper is to facilitate collaboration between the hardware assurance, computer vision, and machine learning communities.
FPIC: A Novel Semantic Dataset for Optical PCB Assurance
Feb 17, 2022
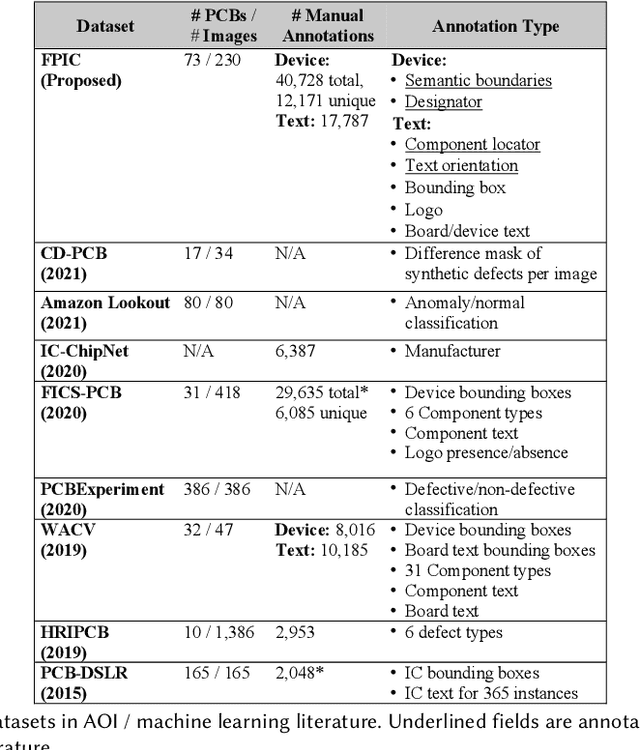
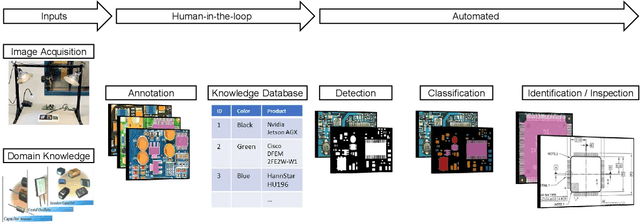
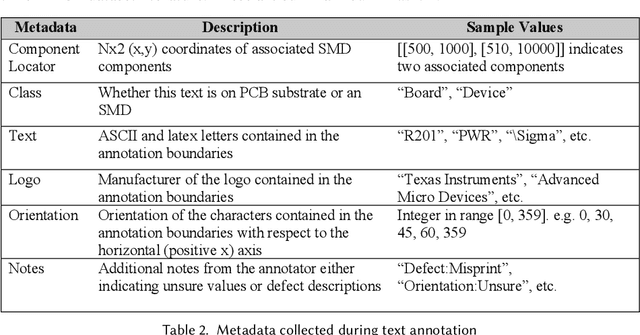
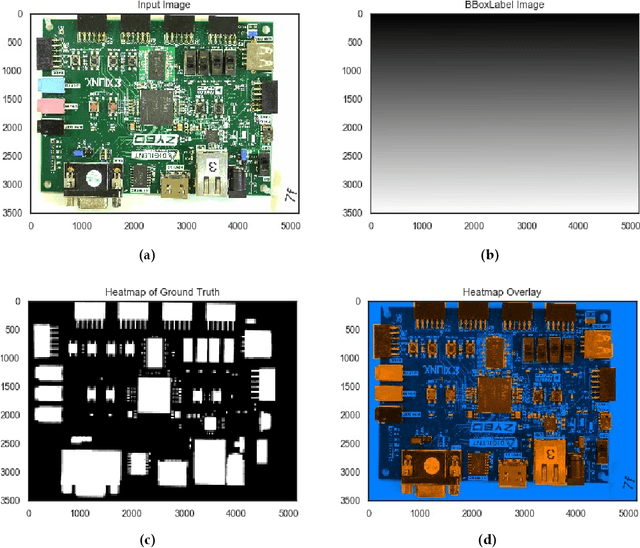
The continued outsourcing of printed circuit board (PCB) fabrication to overseas venues necessitates increased hardware assurance capabilities. Toward this end, several automated optical inspection (AOI) techniques have been proposed in the past exploring various aspects of PCB images acquired using digital cameras. In this work, we review state-of-the-art AOI techniques and observed the strong, rapid trend toward machine learning (ML) solutions. These require significant amounts of labeled ground truth data, which is lacking in the publicly available PCB data space. We propose the FICS PBC Image Collection (FPIC) dataset to address this bottleneck in available large-volume, diverse, semantic annotations. Additionally, this work covers the potential increase in hardware security capabilities and observed methodological distinctions highlighted during data collection.