 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Match: An Open-Sourced Patient Matching Model Based on Large Language Models and Retrieval-Augmented Generation
Mar 17, 2025Patient matching is the process of linking patients to appropriate clinical trials by accurately identifying and matching their medical records with trial eligibility criteria. We propose LLM-Match, a novel framework for patient matching leveraging fine-tuned open-source large language models. Our approach consists of four key components. First, a retrieval-augmented generation (RAG) module extracts relevant patient context from a vast pool of electronic health records (EHRs). Second, a prompt generation module constructs input prompts by integrating trial eligibility criteria (both inclusion and exclusion criteria), patient context, and system instructions. Third, a fine-tuning module with a classification head optimizes the model parameters using structured prompts and ground-truth labels. Fourth, an evaluation module assesses the fine-tuned model's performance on the testing datasets. We evaluated LLM-Match on four open datasets, n2c2, SIGIR, TREC 2021, and TREC 2022, using open-source models, comparing it against TrialGPT, Zero-Shot, and GPT-4-based closed models. LLM-Match outperformed all baselines.
Evaluation of GPT-3 for Anti-Cancer Drug Sensitivity Prediction
Sep 18, 2023In this study, we investigated the potential of GPT-3 for the anti-cancer drug sensitivity prediction task using structured pharmacogenomics data across five tissue types and evaluated its performance with zero-shot prompting and fine-tuning paradigms. The drug's smile representation and cell line's genomic mutation features were predictive of the drug response. The results from this study have the potential to pave the way for designing more efficient treatment protocols in precision oncology.
Ensemble Fine-tuned mBERT for Translation Quality Estimation
Sep 08, 2021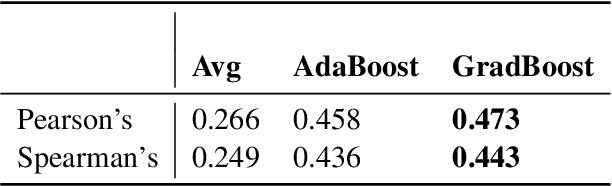
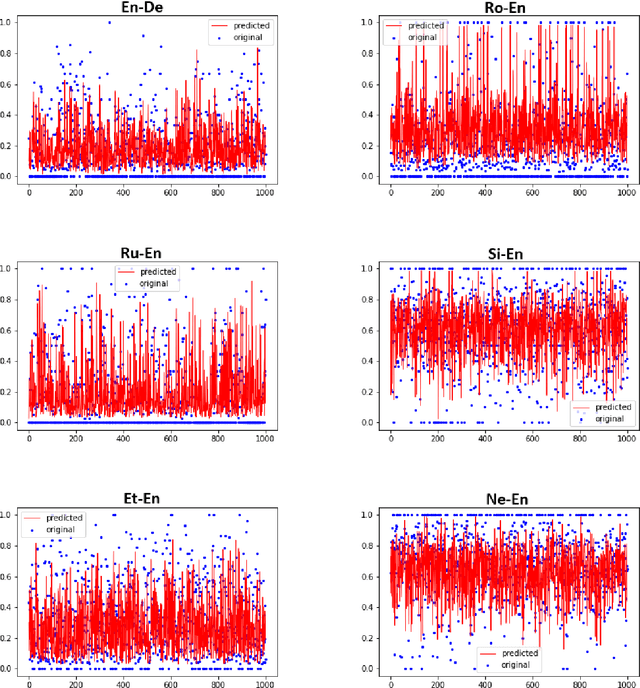
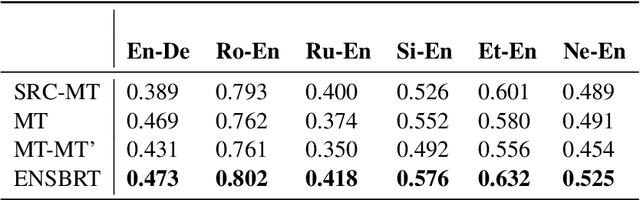
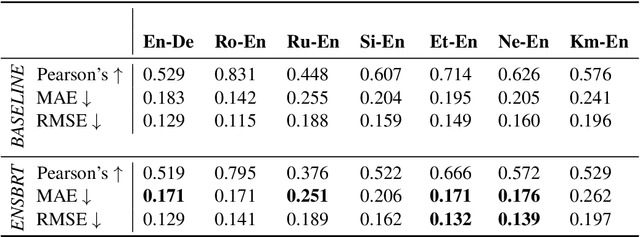
Quality Estimation (QE) is an important component of the machine translation workflow as it assesses the quality of the translated output without consulting reference translations. In this paper, we discuss our submission to the WMT 2021 QE Shared Task. We participate in Task 2 sentence-level sub-task that challenge participants to predict the HTER score for sentence-level post-editing effort. Our proposed system is an ensemble of multilingual BERT (mBERT)-based regression models, which are generated by fine-tuning on different input settings. It demonstrates comparable performance with respect to the Pearson's correlation and beats the baseline system in MAE/ RMSE for several language pairs. In addition, we adapt our system for the zero-shot setting by exploiting target language-relevant language pairs and pseudo-reference translations.
Interpretable Multi-Step Reasoning with Knowledge Extraction on Complex Healthcare Question Answering
Aug 06, 2020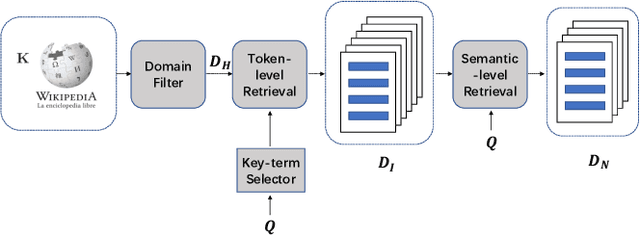
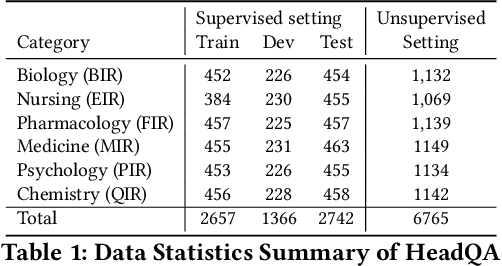
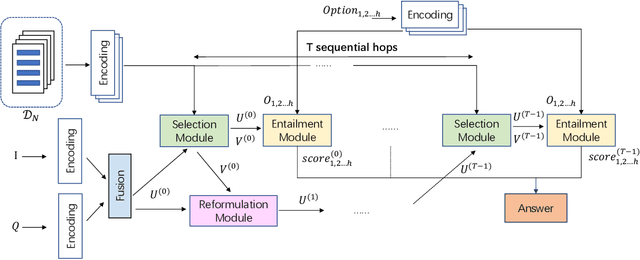
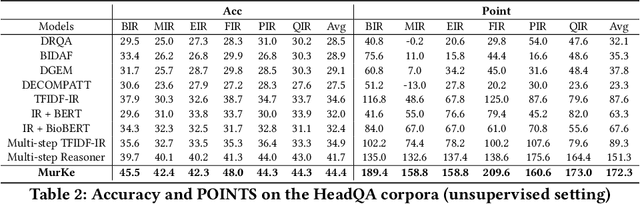
Healthcare question answering assistance aims to provide customer healthcare information, which widely appears in both Web and mobile Internet. The questions usually require the assistance to have proficient healthcare background knowledge as well as the reasoning ability on the knowledge. Recently a challenge involving complex healthcare reasoning, HeadQA dataset, has been proposed, which contains multiple-choice questions authorized for the public healthcare specialization exam. Unlike most other QA tasks that focus on linguistic understanding, HeadQA requires deeper reasoning involving not only knowledge extraction, but also complex reasoning with healthcare knowledge. These questions are the most challenging for current QA systems, and the current performance of the state-of-the-art method is slightly better than a random guess. In order to solve this challenging task, we present a Multi-step reasoning with Knowledge extraction framework (MurKe). The proposed framework first extracts the healthcare knowledge as supporting documents from the large corpus. In order to find the reasoning chain and choose the correct answer, MurKe iterates between selecting the supporting documents, reformulating the query representation using the supporting documents and getting entailment score for each choice using the entailment model. The reformulation module leverages selected documents for missing evidence, which maintains interpretability. Moreover, we are striving to make full use of off-the-shelf pre-trained models. With less trainable weight, the pre-trained model can easily adapt to healthcare tasks with limited training samples. From the experimental results and ablation study, our system is able to outperform several strong baselines on the HeadQA dataset.
Med2Meta: Learning Representations of Medical Concepts with Meta-Embeddings
Jan 04, 2020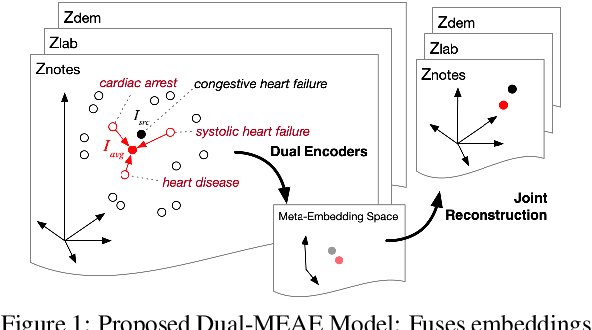
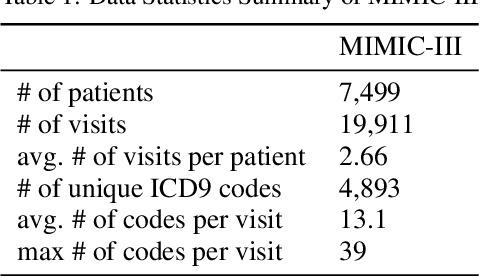
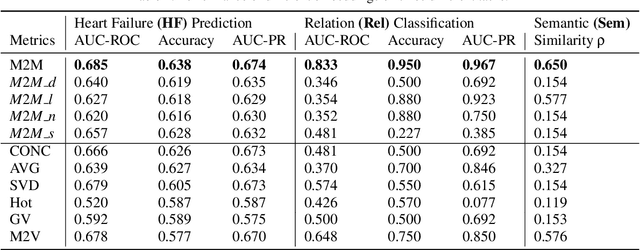

Distributed representations of medical concepts have been used to support downstream clinical tasks recently. Electronic Health Records (EHR) capture different aspects of patients' hospital encounters and serve as a rich source for augmenting clinical decision making by learning robust medical concept embeddings. However, the same medical concept can be recorded in different modalities (e.g., clinical notes, lab results)-with each capturing salient information unique to that modality-and a holistic representation calls for relevant feature ensemble from all information sources. We hypothesize that representations learned from heterogeneous data types would lead to performance enhancement on various clinical informatics and predictive modeling tasks. To this end, our proposed approach makes use of meta-embeddings, embeddings aggregated from learned embeddings. Firstly, modality-specific embeddings for each medical concept is learned with graph autoencoders. The ensemble of all the embeddings is then modeled as a meta-embedding learning problem to incorporate their correlating and complementary information through a joint reconstruction. Empirical results of our model on both quantitative and qualitative clinical evaluations have shown improvements over state-of-the-art embedding models, thus validating our hypothesis.
* 9 pages
Hierarchical Semantic Correspondence Learning for Post-Discharge Patient Mortality Prediction
Oct 15, 2019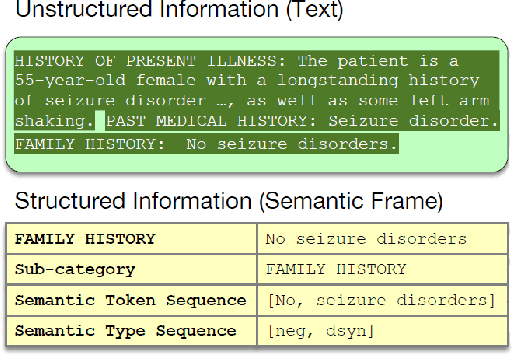

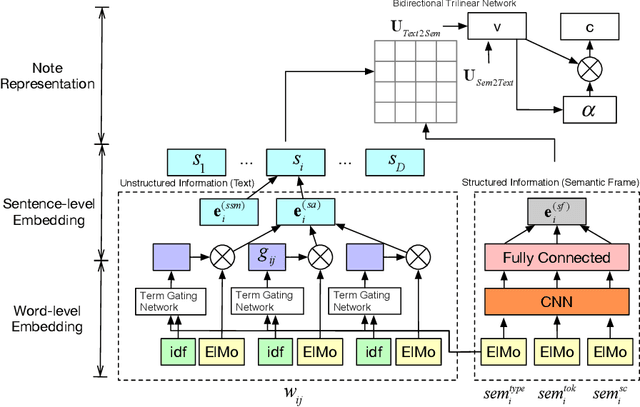
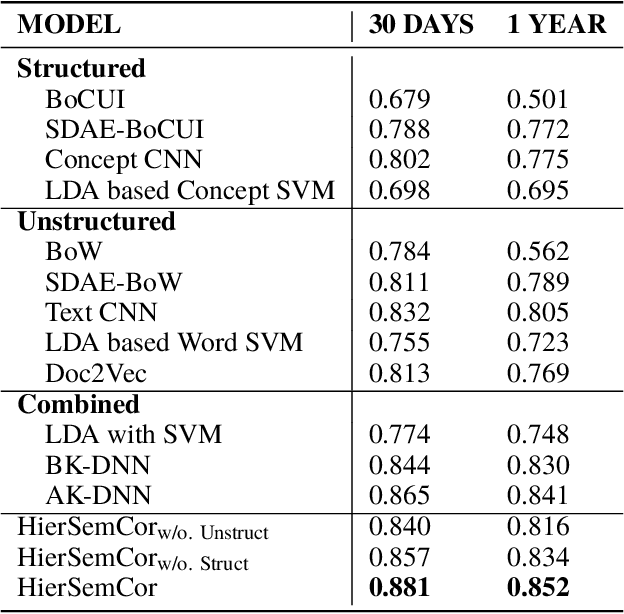
Predicting patient mortality is an important and challenging problem in the healthcare domain, especially for intensive care unit (ICU) patients. Electronic health notes serve as a rich source for learning patient representations, that can facilitate effective risk assessment. However, a large portion of clinical notes are unstructured and also contain domain specific terminologies, from which we need to extract structured information. In this paper, we introduce an embedding framework to learn semantically-plausible distributed representations of clinical notes that exploits the semantic correspondence between the unstructured texts and their corresponding structured knowledge, known as semantic frame, in a hierarchical fashion. Our approach integrates text modeling and semantic correspondence learning into a single model that comprises 1) an unstructured embedding module that makes use of self-similarity matrix representations in order to inject structural regularities of different segments inherent in clinical texts to promote local coherence, 2) a structured embedding module to embed the semantic frames (e.g., UMLS semantic types) with deep ConvNet and 3) a hierarchical semantic correspondence module that embeds by enhancing the interactions between text-semantic frame embedding pairs at multiple levels (i.e., words, sentence, note). Evaluations on multiple embedding benchmarks on post discharge intensive care patient mortality prediction tasks demonstrate its effectiveness compared to approaches that do not exploit the semantic interactions between structured and unstructured information present in clinical notes.
Mixed Pooling Multi-View Attention Autoencoder for Representation Learning in Healthcare
Oct 14, 2019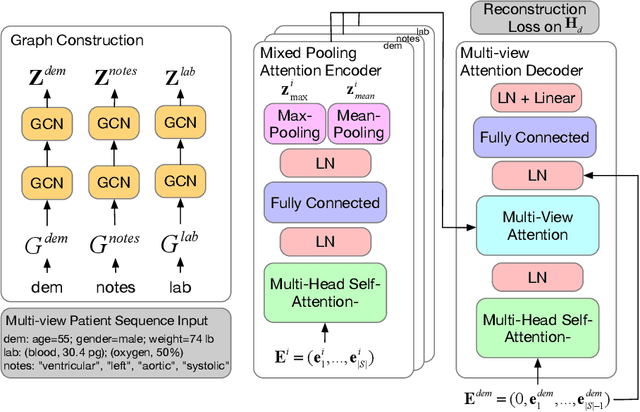

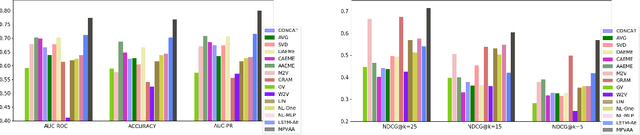
Distributed representations have been used to support downstream tasks in healthcare recently. Healthcare data (e.g., electronic health records) contain multiple modalities of data from heterogeneous sources that can provide complementary information, alongside an added dimension to learning personalized patient representations. To this end, in this paper we propose a novel unsupervised encoder-decoder model, namely Mixed Pooling Multi-View Attention Autoencoder (MPVAA), that generates patient representations encapsulating a holistic view of their medical profile. Specifically, by first learning personalized graph embeddings pertaining to each patient's heterogeneous healthcare data, it then integrates the non-linear relationships among them into a unified representation through multi-view attention mechanism. Additionally, a mixed pooling strategy is incorporated in the encoding step to learn diverse information specific to each data modality. Experiments conducted for multiple tasks demonstrate the effectiveness of the proposed model over the state-of-the-art representation learning methods in healthcare.
Multi-Task Pharmacovigilance Mining from Social Media Posts
Feb 16, 2018

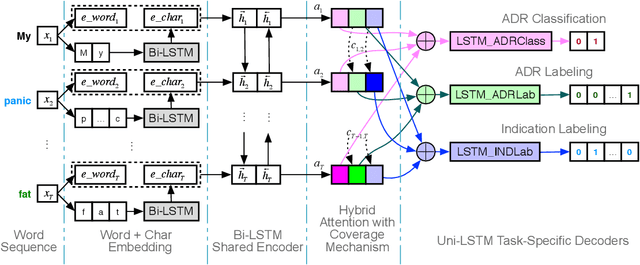
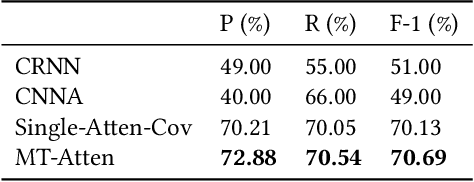
Social media has grown to be a crucial information source for pharmacovigilance studies where an increasing number of people post adverse reactions to medical drugs that are previously unreported. Aiming to effectively monitor various aspects of Adverse Drug Reactions (ADRs) from diversely expressed social medical posts, we propose a multi-task neural network framework that learns several tasks associated with ADR monitoring with different levels of supervisions collectively. Besides being able to correctly classify ADR posts and accurately extract ADR mentions from online posts, the proposed framework is also able to further understand reasons for which the drug is being taken, known as 'indication', from the given social media post. A coverage-based attention mechanism is adopted in our framework to help the model properly identify 'phrasal' ADRs and Indications that are attentive to multiple words in a post. Our framework is applicable in situations where limited parallel data for different pharmacovigilance tasks are available.We evaluate the proposed framework on real-world Twitter datasets, where the proposed model outperforms the state-of-the-art alternatives of each individual task consistently.