 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Modular LLM Framework for Explainable Price Outlier Detection
Mar 21, 2026Detecting product price outliers is important for retail and e-commerce stores as erroneous or unexpectedly high prices adversely affect competitiveness, revenue, and consumer trust. Classical techniques offer simple thresholds while ignoring the rich semantic relationships among product attributes. We propose an agentic Large Language Model (LLM) framework that treats outlier price flagging as a reasoning task grounded in related product detection and comparison. The system processes the prices of target products in three stages: (i) relevance classification selects price-relevant similar products using product descriptions and attributes; (ii) relative utility assessment evaluates the target product against each similar product along price influencing dimensions (e.g., brand, size, features); (iii) reasoning-based decision aggregates these justifications into an explainable price outlier judgment. The framework attains over 75% agreement with human auditors on a test dataset, and outperforms zero-shot and retrieval based LLM techniques. Ablation studies show the sensitivity of the method to key hyper-parameters and testify on its flexibility to be applied to cases with different accuracy requirement and auditor agreements.
LG-Sleep: Local and Global Temporal Dependencies for Mice Sleep Scoring
Dec 19, 2024



Efficiently identifying sleep stages is crucial for unraveling the intricacies of sleep in both preclinical and clinical research. The labor-intensive nature of manual sleep scoring, demanding substantial expertise, has prompted a surge of interest in automated alternatives. Sleep studies in mice play a significant role in understanding sleep patterns and disorders and underscore the need for robust scoring methodologies. In response, this study introduces LG-Sleep, a novel subject-independent deep neural network architecture designed for mice sleep scoring through electroencephalogram (EEG) signals. LG-Sleep extracts local and global temporal transitions within EEG signals to categorize sleep data into three stages: wake, rapid eye movement (REM) sleep, and non-rapid eye movement (NREM) sleep. The model leverages local and global temporal information by employing time-distributed convolutional neural networks to discern local temporal transitions in EEG data. Subsequently, features derived from the convolutional filters traverse long short-term memory blocks, capturing global transitions over extended periods. Crucially, the model is optimized in an autoencoder-decoder fashion, facilitating generalization across distinct subjects and adapting to limited training samples. Experimental findings demonstrate superior performance of LG-Sleep compared to conventional deep neural networks. Moreover, the model exhibits good performance across different sleep stages even when tasked with scoring based on limited training samples.
Robust EEG-based Emotion Recognition Using an Inception and Two-sided Perturbation Model
Apr 21, 2024



Automated emotion recognition using electroencephalogram (EEG) signals has gained substantial attention. Although deep learning approaches exhibit strong performance, they often suffer from vulnerabilities to various perturbations, like environmental noise and adversarial attacks. In this paper, we propose an Inception feature generator and two-sided perturbation (INC-TSP) approach to enhance emotion recognition in brain-computer interfaces. INC-TSP integrates the Inception module for EEG data analysis and employs two-sided perturbation (TSP) as a defensive mechanism against input perturbations. TSP introduces worst-case perturbations to the model's weights and inputs, reinforcing the model's elasticity against adversarial attacks. The proposed approach addresses the challenge of maintaining accurate emotion recognition in the presence of input uncertainties. We validate INC-TSP in a subject-independent three-class emotion recognition scenario, demonstrating robust performance.
Multi-Source Domain Adaptation with Transformer-based Feature Generation for Subject-Independent EEG-based Emotion Recognition
Jan 04, 2024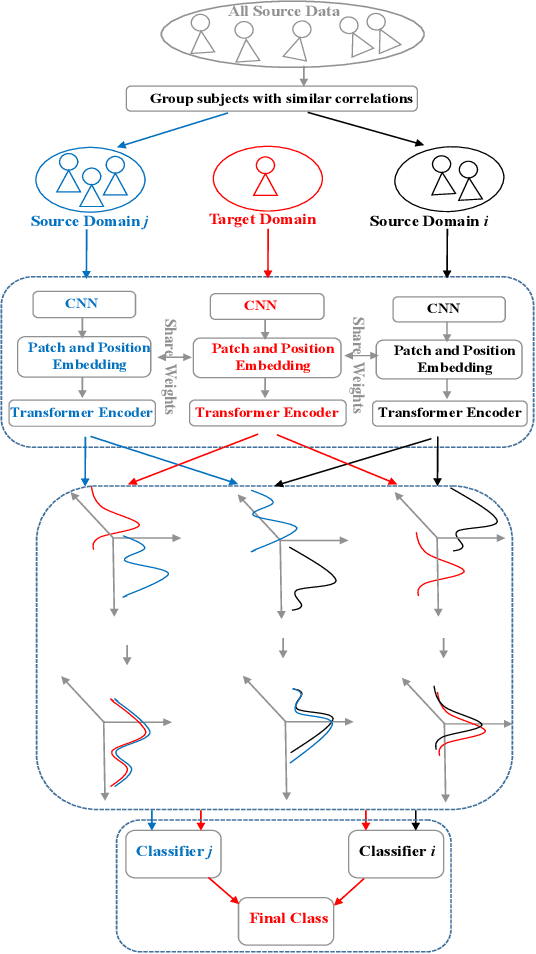

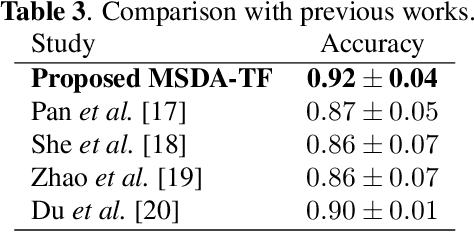
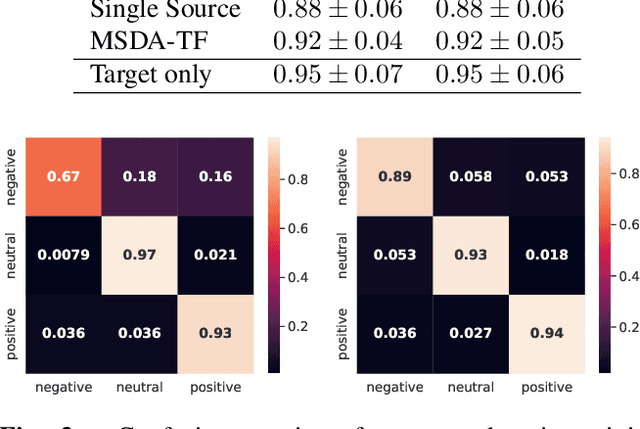
Although deep learning-based algorithms have demonstrated excellent performance in automated emotion recognition via electroencephalogram (EEG) signals, variations across brain signal patterns of individuals can diminish the model's effectiveness when applied across different subjects. While transfer learning techniques have exhibited promising outcomes, they still encounter challenges related to inadequate feature representations and may overlook the fact that source subjects themselves can possess distinct characteristics. In this work, we propose a multi-source domain adaptation approach with a transformer-based feature generator (MSDA-TF) designed to leverage information from multiple sources. The proposed feature generator retains convolutional layers to capture shallow spatial, temporal, and spectral EEG data representations, while self-attention mechanisms extract global dependencies within these features. During the adaptation process, we group the source subjects based on correlation values and aim to align the moments of the target subject with each source as well as within the sources. MSDA-TF is validated on the SEED dataset and is shown to yield promising results.
A Hybrid End-to-End Spatio-Temporal Attention Neural Network with Graph-Smooth Signals for EEG Emotion Recognition
Jul 06, 2023Recently, physiological data such as electroencephalography (EEG) signals have attracted significant attention in affective computing. In this context, the main goal is to design an automated model that can assess emotional states. Lately, deep neural networks have shown promising performance in emotion recognition tasks. However, designing a deep architecture that can extract practical information from raw data is still a challenge. Here, we introduce a deep neural network that acquires interpretable physiological representations by a hybrid structure of spatio-temporal encoding and recurrent attention network blocks. Furthermore, a preprocessing step is applied to the raw data using graph signal processing tools to perform graph smoothing in the spatial domain. We demonstrate that our proposed architecture exceeds state-of-the-art results for emotion classification on the publicly available DEAP dataset. To explore the generality of the learned model, we also evaluate the performance of our architecture towards transfer learning (TL) by transferring the model parameters from a specific source to other target domains. Using DEAP as the source dataset, we demonstrate the effectiveness of our model in performing cross-modality TL and improving emotion classification accuracy on DREAMER and the Emotional English Word (EEWD) datasets, which involve EEG-based emotion classification tasks with different stimuli.
Manifold Regularization for Memory-Efficient Training of Deep Neural Networks
May 26, 2023One of the prevailing trends in the machine- and deep-learning community is to gravitate towards the use of increasingly larger models in order to keep pushing the state-of-the-art performance envelope. This tendency makes access to the associated technologies more difficult for the average practitioner and runs contrary to the desire to democratize knowledge production in the field. In this paper, we propose a framework for achieving improved memory efficiency in the process of learning traditional neural networks by leveraging inductive-bias-driven network design principles and layer-wise manifold-oriented regularization objectives. Use of the framework results in improved absolute performance and empirical generalization error relative to traditional learning techniques. We provide empirical validation of the framework, including qualitative and quantitative evidence of its effectiveness on two standard image datasets, namely CIFAR-10 and CIFAR-100. The proposed framework can be seamlessly combined with existing network compression methods for further memory savings.