 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Alternating Direction Method of Multipliers for Feed-forward Neural Networks
Sep 06, 2020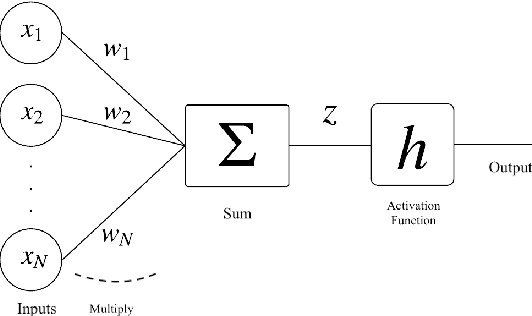
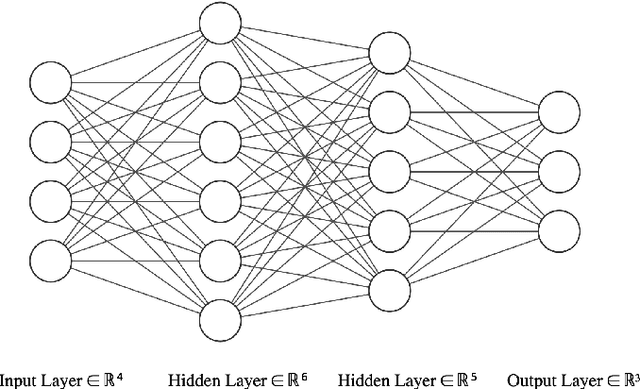
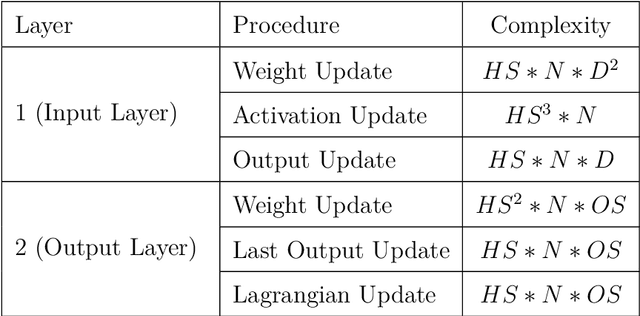
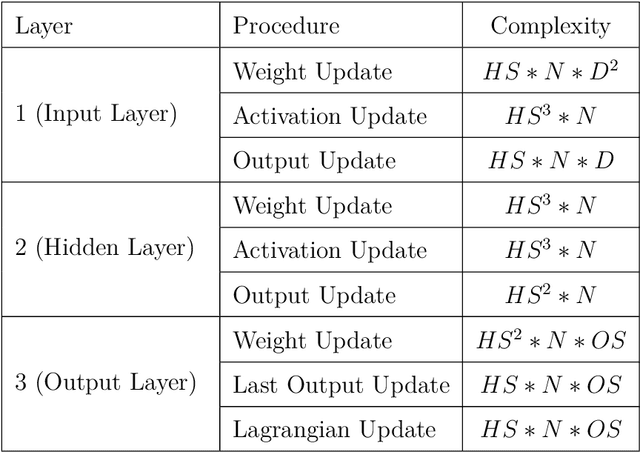
In this work, we present a hardware compatible neural network training algorithm in which we used alternating direction method of multipliers (ADMM) and iterative least-square methods. The motive behind this approach was to conduct a method of training neural networks that is scalable and can be parallelised. These characteristics make this algorithm suitable for hardware implementation. We have achieved 6.9\% and 6.8\% better accuracy comparing to SGD and Adam respectively, with a four-layer neural network with hidden size of 28 on HIGGS dataset. Likewise, we could observe 21.0\% and 2.2\% accuracy improvement comparing to SGD and Adam respectively, on IRIS dataset with a three-layer neural network with hidden size of 8. This is while the use of matrix inversion, which is challenging for hardware implementation, is avoided in this method. We assessed the impact of avoiding matrix inversion on ADMM accuracy and we observed that we can safely replace matrix inversion with iterative least-square methods and maintain the desired performance. Also, the computational complexity of the implemented method is polynomial regarding dimensions of the input dataset and hidden size of the network.
An FPGA Accelerated Method for Training Feed-forward Neural Networks Using Alternating Direction Method of Multipliers and LSMR
Sep 06, 2020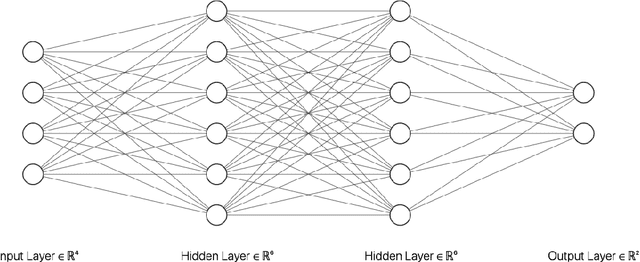

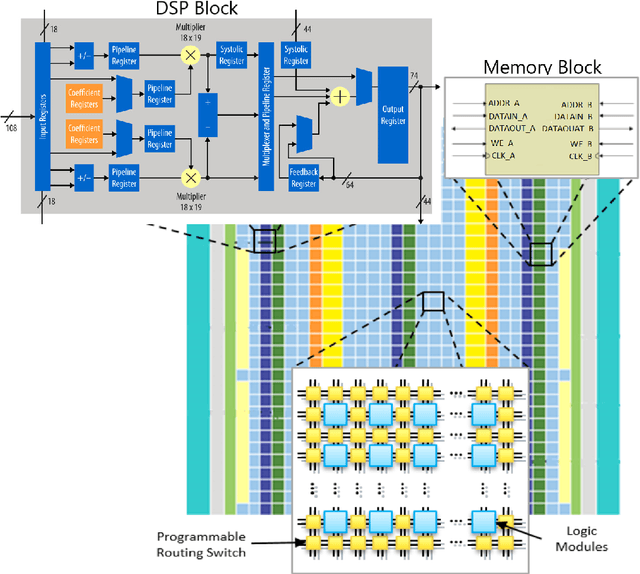
In this project, we have successfully designed, implemented, deployed and tested a novel FPGA accelerated algorithm for neural network training. The algorithm itself was developed in an independent study option. This training method is based on Alternating Direction Method of Multipliers algorithm, which has strong parallel characteristics and avoids procedures such as matrix inversion that are problematic in hardware designs by employing LSMR. As an intermediate stage, we fully implemented the ADMM-LSMR method in C language for feed-forward neural networks with a flexible number of layers and hidden size. We demonstrated that the method can operate with fixed-point arithmetic without compromising the accuracy. Next, we devised an FPGA accelerated version of the algorithm using Intel FPGA SDK for OpenCL and performed extensive optimisation stages followed by successful deployment of the program on an Intel Arria 10 GX FPGA. The FPGA accelerated program showed up to 6 times speed up comparing to equivalent CPU implementation while achieving promising accuracy.