 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Alternating Direction Method of Multipliers for Feed-forward Neural Networks
Paper and Code
Sep 06, 2020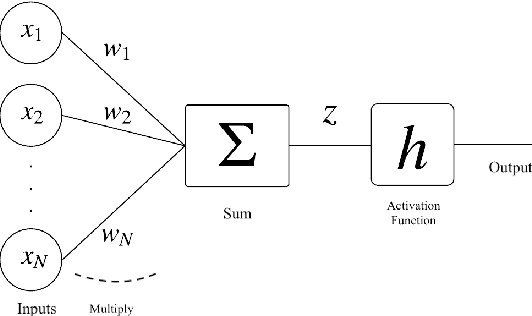
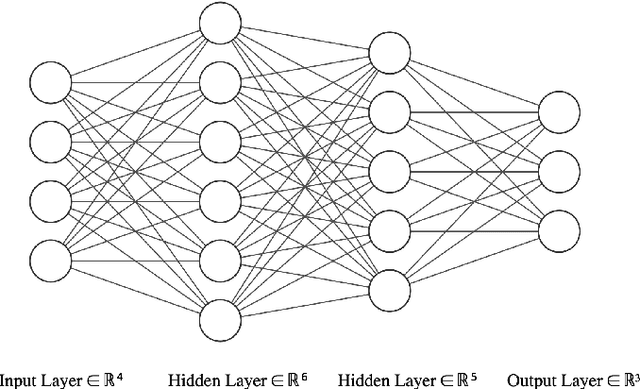
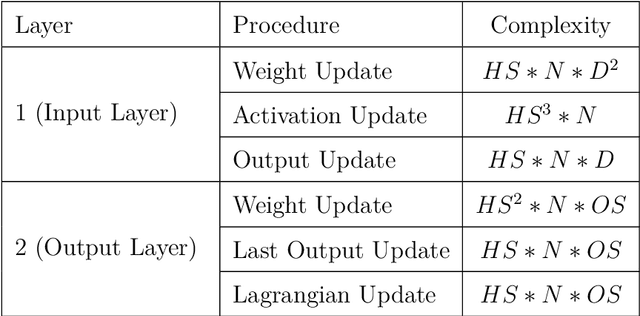
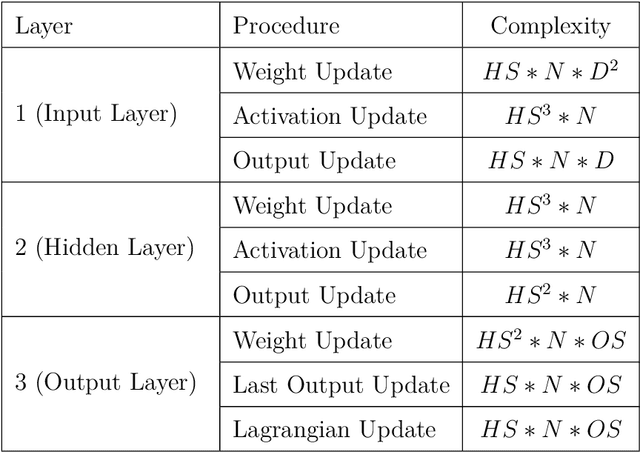
In this work, we present a hardware compatible neural network training algorithm in which we used alternating direction method of multipliers (ADMM) and iterative least-square methods. The motive behind this approach was to conduct a method of training neural networks that is scalable and can be parallelised. These characteristics make this algorithm suitable for hardware implementation. We have achieved 6.9\% and 6.8\% better accuracy comparing to SGD and Adam respectively, with a four-layer neural network with hidden size of 28 on HIGGS dataset. Likewise, we could observe 21.0\% and 2.2\% accuracy improvement comparing to SGD and Adam respectively, on IRIS dataset with a three-layer neural network with hidden size of 8. This is while the use of matrix inversion, which is challenging for hardware implementation, is avoided in this method. We assessed the impact of avoiding matrix inversion on ADMM accuracy and we observed that we can safely replace matrix inversion with iterative least-square methods and maintain the desired performance. Also, the computational complexity of the implemented method is polynomial regarding dimensions of the input dataset and hidden size of the network.