 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Analysis of Input Modalities for Fracture Classification of the Paediatric Wrist
Dec 18, 2024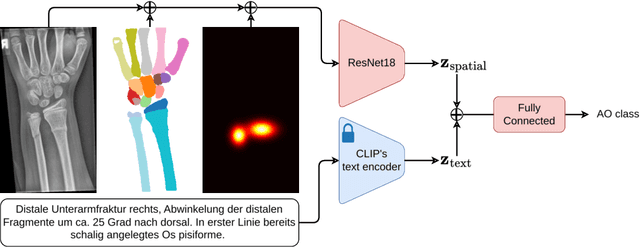
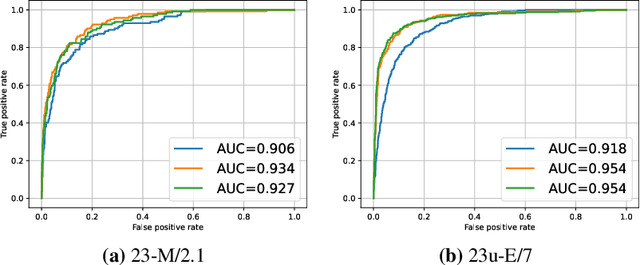
Fractures, particularly in the distal forearm, are among the most common injuries in children and adolescents, with approximately 800 000 cases treated annually in Germany. The AO/OTA system provides a structured fracture type classification, which serves as the foundation for treatment decisions. Although accurately classifying fractures can be challenging, current deep learning models have demonstrated performance comparable to that of experienced radiologists. While most existing approaches rely solely on radiographs, the potential impact of incorporating other additional modalities, such as automatic bone segmentation, fracture location, and radiology reports, remains underexplored. In this work, we systematically analyse the contribution of these three additional information types, finding that combining them with radiographs increases the AUROC from 91.71 to 93.25. Our code is available on GitHub.
Building RadiologyNET: Unsupervised annotation of a large-scale multimodal medical database
Jul 27, 2023Background and objective: The usage of machine learning in medical diagnosis and treatment has witnessed significant growth in recent years through the development of computer-aided diagnosis systems that are often relying on annotated medical radiology images. However, the availability of large annotated image datasets remains a major obstacle since the process of annotation is time-consuming and costly. This paper explores how to automatically annotate a database of medical radiology images with regard to their semantic similarity. Material and methods: An automated, unsupervised approach is used to construct a large annotated dataset of medical radiology images originating from Clinical Hospital Centre Rijeka, Croatia, utilising multimodal sources, including images, DICOM metadata, and narrative diagnoses. Several appropriate feature extractors are tested for each of the data sources, and their utility is evaluated using k-means and k-medoids clustering on a representative data subset. Results: The optimal feature extractors are then integrated into a multimodal representation, which is then clustered to create an automated pipeline for labelling a precursor dataset of 1,337,926 medical images into 50 clusters of visually similar images. The quality of the clusters is assessed by examining their homogeneity and mutual information, taking into account the anatomical region and modality representation. Conclusion: The results suggest that fusing the embeddings of all three data sources together works best for the task of unsupervised clustering of large-scale medical data, resulting in the most concise clusters. Hence, this work is the first step towards building a much larger and more fine-grained annotated dataset of medical radiology images.