 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphIt: Flexible Spherical Approximation of Robot Morphology for Representation-driven Adaptation
Jul 18, 2025



What if a robot could rethink its own morphological representation to better meet the demands of diverse tasks? Most robotic systems today treat their physical form as a fixed constraint rather than an adaptive resource, forcing the same rigid geometric representation to serve applications with vastly different computational and precision requirements. We introduce MorphIt, a novel algorithm for approximating robot morphology using spherical primitives that balances geometric accuracy with computational efficiency. Unlike existing approaches that rely on either labor-intensive manual specification or inflexible computational methods, MorphIt implements an automatic gradient-based optimization framework with tunable parameters that provides explicit control over the physical fidelity versus computational cost tradeoff. Quantitative evaluations demonstrate that MorphIt outperforms baseline approaches (Variational Sphere Set Approximation and Adaptive Medial-Axis Approximation) across multiple metrics, achieving better mesh approximation with fewer spheres and reduced computational overhead. Our experiments show enhanced robot capabilities in collision detection accuracy, contact-rich interaction simulation, and navigation through confined spaces. By dynamically adapting geometric representations to task requirements, robots can now exploit their physical embodiment as an active resource rather than an inflexible parameter, opening new frontiers for manipulation in environments where physical form must continuously balance precision with computational tractability.
Regressing Relative Fine-Grained Change for Sub-Groups in Unreliable Heterogeneous Data Through Deep Multi-Task Metric Learning
Aug 11, 2022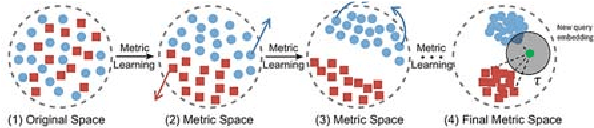

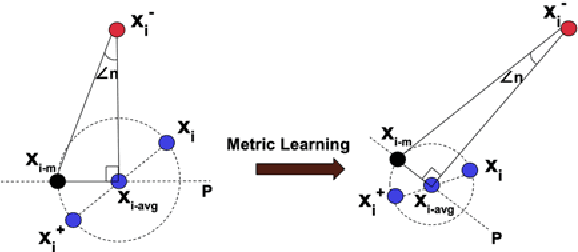

Fine-Grained Change Detection and Regression Analysis are essential in many applications of ArtificialIntelligence. In practice, this task is often challenging owing to the lack of reliable ground truth information andcomplexity arising from interactions between the many underlying factors affecting a system. Therefore,developing a framework which can represent the relatedness and reliability of multiple sources of informationbecomes critical. In this paper, we investigate how techniques in multi-task metric learning can be applied for theregression of fine-grained change in real data.The key idea is that if we incorporate the incremental change in a metric of interest between specific instancesof an individual object as one of the tasks in a multi-task metric learning framework, then interpreting thatdimension will allow the user to be alerted to fine-grained change invariant to what the overall metric isgeneralised to be. The techniques investigated are specifically tailored for handling heterogeneous data sources,i.e. the input data for each of the tasks might contain missing values, the scale and resolution of the values is notconsistent across tasks and the data contains non-independent and identically distributed (non-IID) instances. Wepresent the results of our initial experimental implementations of this idea and discuss related research in thisdomain which may offer direction for further research.
Less Is More: Improved RNN-T Decoding Using Limited Label Context and Path Merging
Dec 12, 2020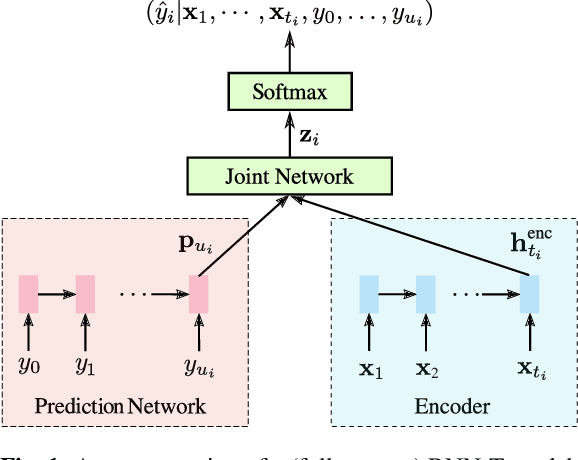
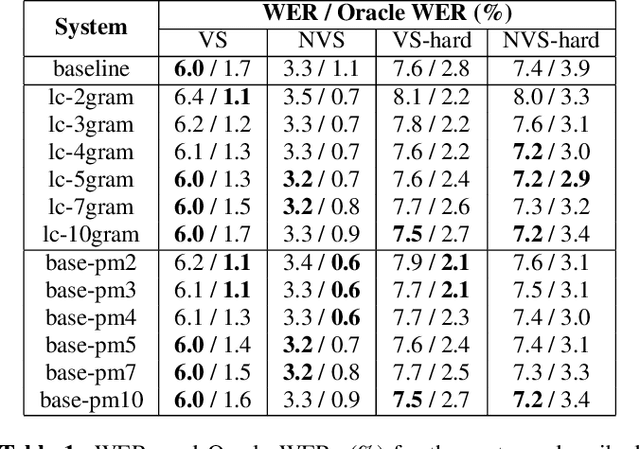
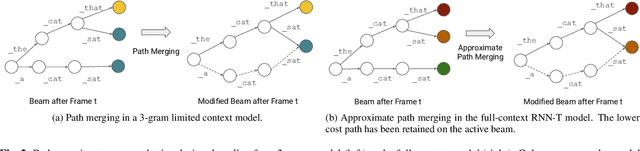
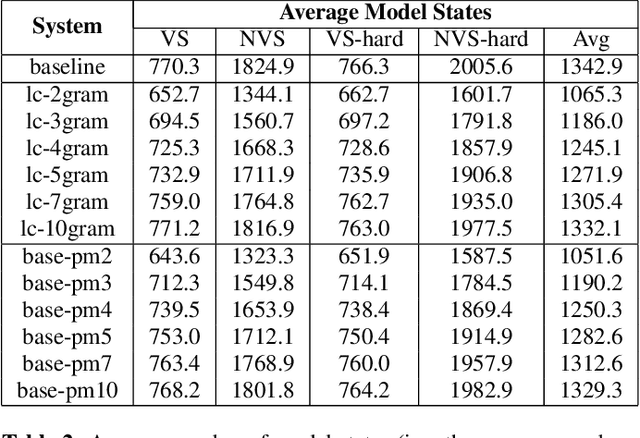
End-to-end models that condition the output label sequence on all previously predicted labels have emerged as popular alternatives to conventional systems for automatic speech recognition (ASR). Since unique label histories correspond to distinct models states, such models are decoded using an approximate beam-search process which produces a tree of hypotheses. In this work, we study the influence of the amount of label context on the model's accuracy, and its impact on the efficiency of the decoding process. We find that we can limit the context of the recurrent neural network transducer (RNN-T) during training to just four previous word-piece labels, without degrading word error rate (WER) relative to the full-context baseline. Limiting context also provides opportunities to improve the efficiency of the beam-search process during decoding by removing redundant paths from the active beam, and instead retaining them in the final lattice. This path-merging scheme can also be applied when decoding the baseline full-context model through an approximation. Overall, we find that the proposed path-merging scheme is extremely effective allowing us to improve oracle WERs by up to 36% over the baseline, while simultaneously reducing the number of model evaluations by up to 5.3% without any degradation in WER.
Understanding and Exploiting Dependent Variables with Deep Metric Learning
Sep 08, 2020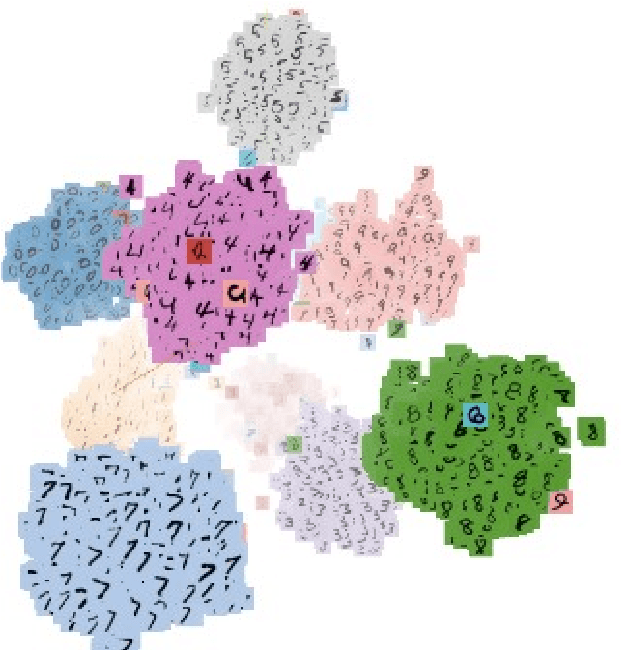
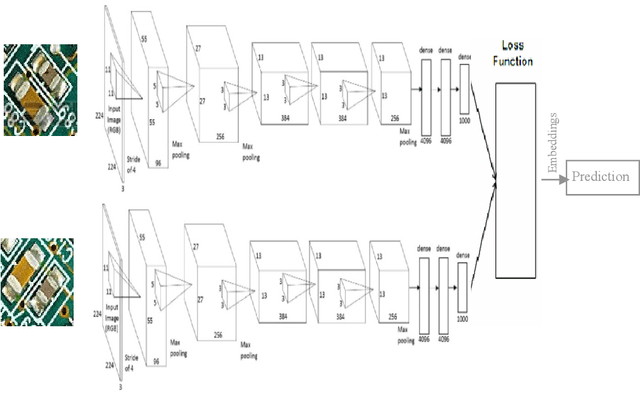

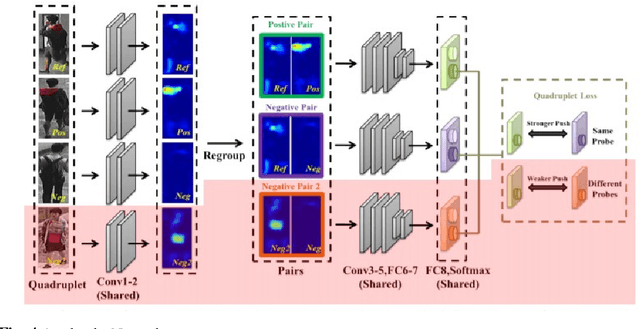
Deep Metric Learning (DML) approaches learn to represent inputs to a lower-dimensional latent space such that the distance between representations in this space corresponds with a predefined notion of similarity. This paper investigates how the mapping element of DML may be exploited in situations where the salient features in arbitrary classification problems vary over time or due to changing underlying variables. Examples of such variable features include seasonal and time-of-day variations in outdoor scenes in place recognition tasks for autonomous navigation and age/gender variations in human/animal subjects in classification tasks for medical/ethological studies. Through the use of visualisation tools for observing the distribution of DML representations per each query variable for which prior information is available, the influence of each variable on the classification task may be better understood. Based on these relationships, prior information on these salient background variables may be exploited at the inference stage of the DML approach by using a clustering algorithm to improve classification performance. This research proposes such a methodology establishing the saliency of query background variables and formulating clustering algorithms for better separating latent-space representations at run-time. The paper also discusses online management strategies to preserve the quality and diversity of data and the representation of each class in the gallery of embeddings in the DML approach. We also discuss latent works towards understanding the relevance of underlying/multiple variables with DML.
Deep Learning vs. Traditional Computer Vision
Oct 30, 2019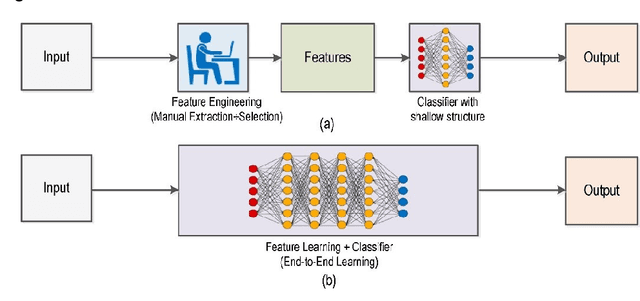
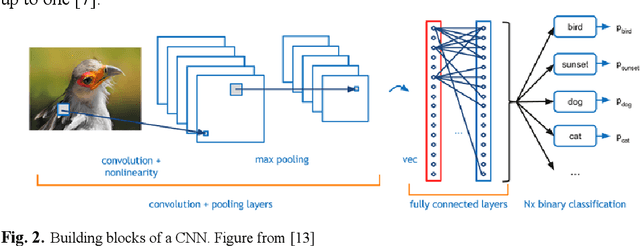
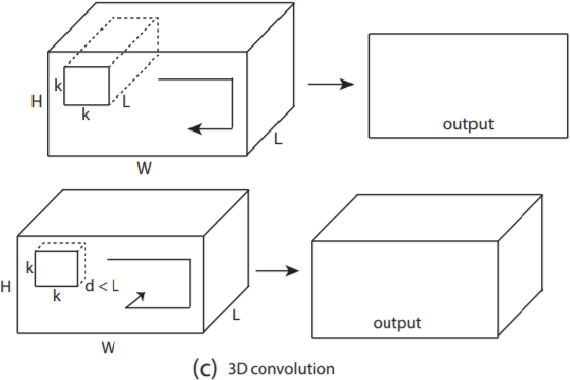

Deep Learning has pushed the limits of what was possible in the domain of Digital Image Processing. However, that is not to say that the traditional computer vision techniques which had been undergoing progressive development in years prior to the rise of DL have become obsolete. This paper will analyse the benefits and drawbacks of each approach. The aim of this paper is to promote a discussion on whether knowledge of classical computer vision techniques should be maintained. The paper will also explore how the two sides of computer vision can be combined. Several recent hybrid methodologies are reviewed which have demonstrated the ability to improve computer vision performance and to tackle problems not suited to Deep Learning. For example, combining traditional computer vision techniques with Deep Learning has been popular in emerging domains such as Panoramic Vision and 3D vision for which Deep Learning models have not yet been fully optimised