 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Exploiting Dependent Variables with Deep Metric Learning
Paper and Code
Sep 08, 2020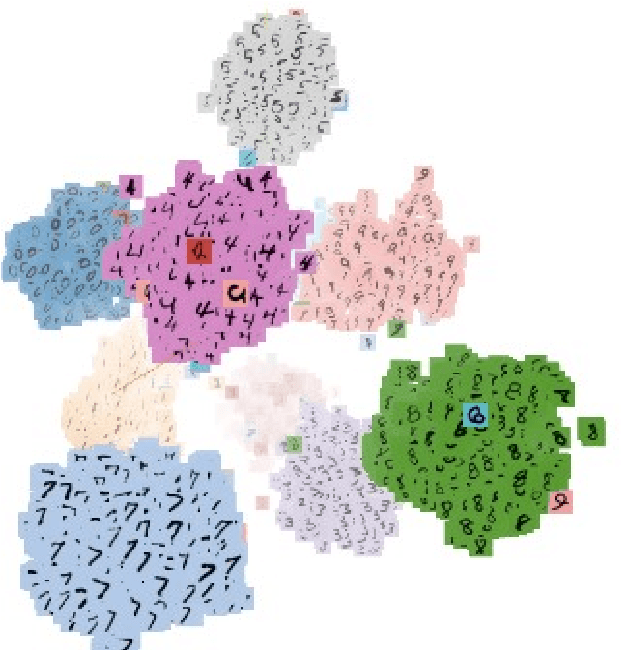

Deep Metric Learning (DML) approaches learn to represent inputs to a lower-dimensional latent space such that the distance between representations in this space corresponds with a predefined notion of similarity. This paper investigates how the mapping element of DML may be exploited in situations where the salient features in arbitrary classification problems vary over time or due to changing underlying variables. Examples of such variable features include seasonal and time-of-day variations in outdoor scenes in place recognition tasks for autonomous navigation and age/gender variations in human/animal subjects in classification tasks for medical/ethological studies. Through the use of visualisation tools for observing the distribution of DML representations per each query variable for which prior information is available, the influence of each variable on the classification task may be better understood. Based on these relationships, prior information on these salient background variables may be exploited at the inference stage of the DML approach by using a clustering algorithm to improve classification performance. This research proposes such a methodology establishing the saliency of query background variables and formulating clustering algorithms for better separating latent-space representations at run-time. The paper also discusses online management strategies to preserve the quality and diversity of data and the representation of each class in the gallery of embeddings in the DML approach. We also discuss latent works towards understanding the relevance of underlying/multiple variables with DML.