 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEC-Cox: Machine-Learning-Assisted Generalized Entropy Calibration for ATT Marginal Hazard-Ratio Estimation
Jun 06, 2026Externally controlled survival trials are increasingly used when concurrent randomized controls are infeasible, particularly in oncology and rare-disease settings with time-to-event endpoints. We target an average-treatment-effect-on-the-treated (ATT)-type marginal hazard-ratio estimand, comparing treatment with counterfactual control in the treated trial population, and estimate it using inverse-probability-weighted (IPW) Cox regression. Valid inference is challenging because IPW Cox regression depends on the weights through both event contributions and risk-set averages, making flexible machine-learning nuisance estimation difficult to incorporate directly. Building on machine-learning-assisted generalized entropy calibration (MEC) by Lee and Kim (2026), we propose MEC-Cox for ATT-weighted IPW Cox regression. The method begins with normalized source-propensity-score odds weights for external controls and then applies Bregman calibration to balance cross-fitted prognostic summaries between external controls and treated trial patients. The calibration basis may include control-survival predictions, Cox linear predictors, penalized-survival-model predictions, or other prognostic-score summaries. MEC-updated weights therefore play a dual role as source-transport and prognostic-score balancing weights. We establish consistency, characterize a calibration-induced efficiency gain, and develop a stacked sandwich variance estimator. Simulations show that MEC-Cox can reduce bias, increase efficiency, and improve coverage through flexible machine-learning-assisted adjustment.
MEC: Machine-Learning-Assisted Generalized Entropy Calibration for Semi-Supervised Mean Estimation
Apr 07, 2026Obtaining high-quality labels is costly, whereas unlabeled covariates are often abundant, motivating semi-supervised inference methods with reliable uncertainty quantification. Prediction-powered inference (PPI) leverages a machine-learning predictor trained on a small labeled sample to improve efficiency, but it can lose efficiency under model misspecification and suffer from coverage distortions due to label reuse. We introduce Machine-Learning-Assisted Generalized Entropy Calibration (MEC), a cross-fitted, calibration-weighted variant of PPI. MEC improves efficiency by reweighting labeled samples to better align with the target population, using a principled calibration framework based on Bregman projections. This yields robustness to affine transformations of the predictor and relaxes requirements for validity by replacing conditions on raw prediction error with weaker projection-error conditions. As a result, MEC attains the semiparametric efficiency bound under weaker assumptions than existing PPI variants. Across simulations and a real-data application, MEC achieves near-nominal coverage and tighter confidence intervals than CF-PPI and vanilla PPI.
Continuous shrinkage prior revisited: a collapsing behavior and remedy
Jul 04, 2020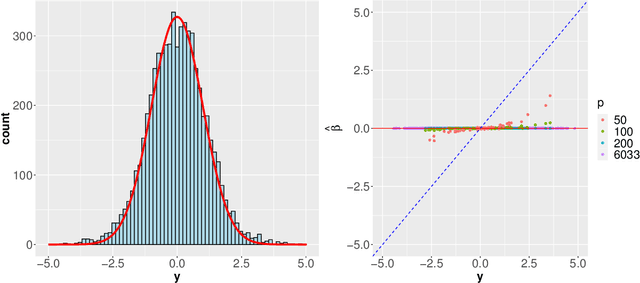
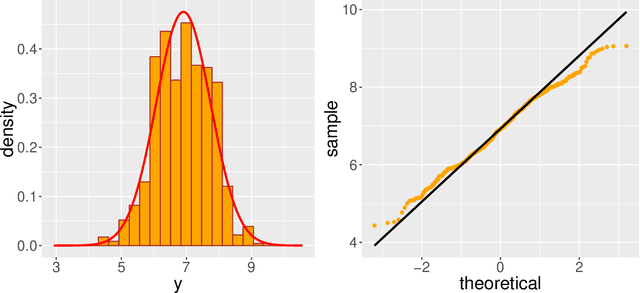

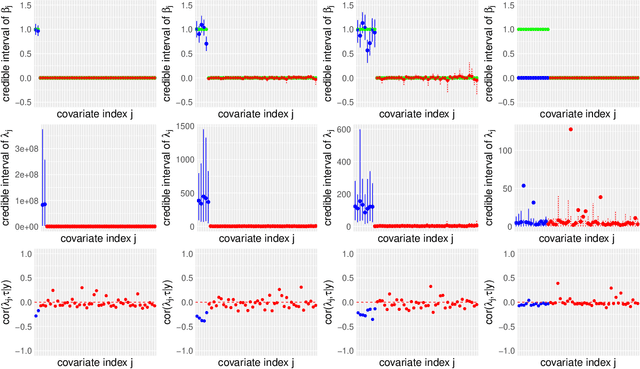
Modern genomic studies are increasingly focused on identifying more and more genes clinically associated with a health response. Commonly used Bayesian shrinkage priors are designed primarily to detect only a handful of signals when the dimension of the predictors is very high. In this article, we investigate the performance of a popular continuous shrinkage prior in the presence of relatively large number of true signals. We draw attention to an undesirable phenomenon; the posterior mean is rendered very close to a null vector, caused by a sharp underestimation of the global-scale parameter. The phenomenon is triggered by the absence of a tail-index controlling mechanism in the Bayesian shrinkage priors. We provide a remedy by developing a global-local-tail shrinkage prior which can automatically learn the tail-index and can provide accurate inference even in the presence of moderately large number of signals. The collapsing behavior of the Horseshoe with its remedy is exemplified in numerical examples and in two gene expression datasets.
Directionally Dependent Multi-View Clustering Using Copula Model
Mar 17, 2020



In recent biomedical scientific problems, it is a fundamental issue to integratively cluster a set of objects from multiple sources of datasets. Such problems are mostly encountered in genomics, where data is collected from various sources, and typically represent distinct yet complementary information. Integrating these data sources for multi-source clustering is challenging due to their complex dependence structure including directional dependency. Particularly in genomics studies, it is known that there is certain directional dependence between DNA expression, DNA methylation, and RNA expression, widely called The Central Dogma. Most of the existing multi-view clustering methods either assume an independent structure or pair-wise (non-directional) dependency, thereby ignoring the directional relationship. Motivated by this, we propose a copula-based multi-view clustering model where a copula enables the model to accommodate the directional dependence existing in the datasets. We conduct a simulation experiment where the simulated datasets exhibiting inherent directional dependence: it turns out that ignoring the directional dependence negatively affects the clustering performance. As a real application, we applied our model to the breast cancer tumor samples collected from The Cancer Genome Altas (TCGA).