 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Generative Artificial Intelligence Method for Interference Study on Multiplex Brightfield Immunohistochemistry Images
Aug 15, 2024



Multiplex brightfield imaging offers the advantage of simultaneously analyzing multiple biomarkers on a single slide, as opposed to single biomarker labeling on multiple consecutive slides. To accurately analyze multiple biomarkers localized at the same cellular compartment, two representative biomarker sets were selected as assay models - cMET-PDL1-EGFR and CD8-LAG3-PDL1, where all three biomarkers can co-localize on the cell membrane. One of the most crucial preliminary stages for analyzing such assay is identifying each unique chromogen on individual cells. This is a challenging problem due to the co-localization of membrane stains from all the three biomarkers. It requires advanced color unmixing for creating the equivalent singleplex images from each triplex image for each biomarker. In this project, we developed a cycle-Generative Adversarial Network (cycle-GAN) method for unmixing the triplex images generated from the above-mentioned assays. Three different models were designed to generate the singleplex image for each of the three stains Tamra (purple), QM-Dabsyl (yellow) and Green. A notable novelty of our approach was that the input to the network were images in the optical density domain instead of conventionally used RGB images. The use of the optical density domain helped in reducing the blurriness of the synthetic singleplex images, which was often observed when the network was trained on RGB images. The cycle-GAN models were validated on 10,800 lung, gastric and colon images for the cMET-PDL1-EGFR assay and 3600 colon images for the CD8-LAG3-PDL1 assay. Visual as well as quantified assessments demonstrated that the proposed method is effective and efficient when compared with the manual reviewing results and is readily applicable to various multiplex assays.
Structured Model Pruning for Efficient Inference in Computational Pathology
Apr 12, 2024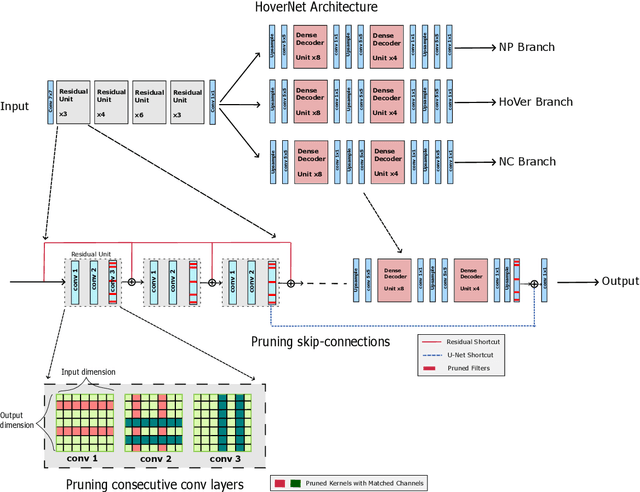

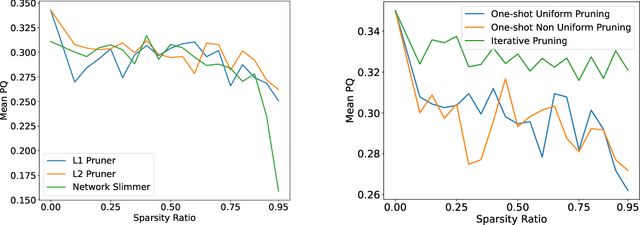

Recent years have seen significant efforts to adopt Artificial Intelligence (AI) in healthcare for various use cases, from computer-aided diagnosis to ICU triage. However, the size of AI models has been rapidly growing due to scaling laws and the success of foundational models, which poses an increasing challenge to leverage advanced models in practical applications. It is thus imperative to develop efficient models, especially for deploying AI solutions under resource-constrains or with time sensitivity. One potential solution is to perform model compression, a set of techniques that remove less important model components or reduce parameter precision, to reduce model computation demand. In this work, we demonstrate that model pruning, as a model compression technique, can effectively reduce inference cost for computational and digital pathology based analysis with a negligible loss of analysis performance. To this end, we develop a methodology for pruning the widely used U-Net-style architectures in biomedical imaging, with which we evaluate multiple pruning heuristics on nuclei instance segmentation and classification, and empirically demonstrate that pruning can compress models by at least 70% with a negligible drop in performance.
Continual Learning for Tumor Classification in Histopathology Images
Aug 07, 2022Recent years have seen great advancements in the development of deep learning models for histopathology image analysis in digital pathology applications, evidenced by the increasingly common deployment of these models in both research and clinical settings. Although such models have shown unprecedented performance in solving fundamental computational tasks in DP applications, they suffer from catastrophic forgetting when adapted to unseen data with transfer learning. With an increasing need for deep learning models to handle ever changing data distributions, including evolving patient population and new diagnosis assays, continual learning models that alleviate model forgetting need to be introduced in DP based analysis. However, to our best knowledge, there is no systematic study of such models for DP-specific applications. Here, we propose CL scenarios in DP settings, where histopathology image data from different sources/distributions arrive sequentially, the knowledge of which is integrated into a single model without training all the data from scratch. We then established an augmented dataset for colorectal cancer H&E classification to simulate shifts of image appearance and evaluated CL model performance in the proposed CL scenarios. We leveraged a breast tumor H&E dataset along with the colorectal cancer to evaluate CL from different tumor types. In addition, we evaluated CL methods in an online few-shot setting under the constraints of annotation and computational resources. We revealed promising results of CL in DP applications, potentially paving the way for application of these methods in clinical practice.