 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasterful: A Training Platform for Computer Vision Models
May 21, 2022
Masterful is a software platform to train deep learning computer vision models. Data and model architecture are inputs to the platform, and the output is a trained model. The platform's primary goal is to maximize a trained model's accuracy, which it achieves through its regularization and semi-supervised learning implementations. The platform's secondary goal is to minimize the amount of manual experimentation typically required to tune training hyperparameters, which it achieves via multiple metalearning algorithms which are custom built to control the platform's regularization and semi-supervised learning implementations. The platform's tertiary goal is to minimize the computing resources required to train a model, which it achieves via another set of metalearning algorithms which are purpose built to control Tensorflow's optimization implementations. The platform builds on top of Tensorflow's data management, architecture, automatic differentiation, and optimization implementations.
COVID-19 Emotion Monitoring as a Tool to Increase Preparedness for Disease Outbreaks in Developing Regions
Dec 17, 2020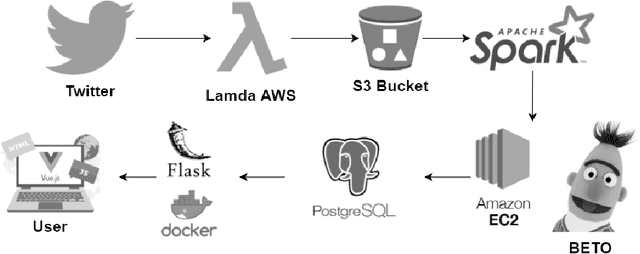
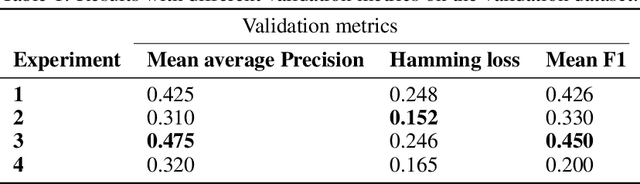
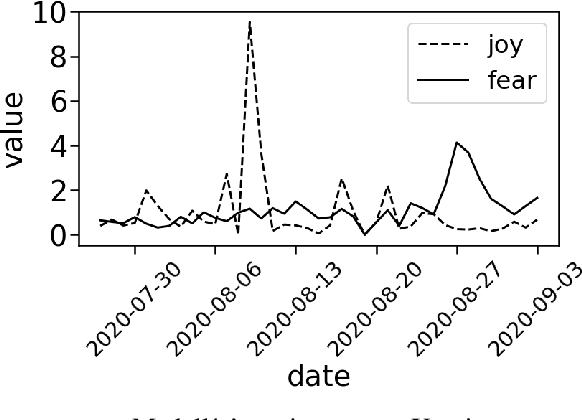
The COVID-19 pandemic brought many challenges, from hospital-occupation management to lock-down mental-health repercussions such as anxiety or depression. In this work, we present a solution for the later problem by developing a Twitter emotion-monitor system based on a state-of-the-art natural-language processing model. The system monitors six different emotions on accounts in cities, as well as politicians and health-authorities Twitter accounts. With an anonymous use of the emotion monitor, health authorities and private health-insurance companies can develop strategies to tackle problems such as suicide and clinical depression. The model chosen for such a task is a Bidirectional-Encoder Representations from Transformers (BERT) pre-trained on a Spanish corpus (BETO). The model performed well on a validation dataset. The system is deployed online as part of a web application for simulation and data analysis of COVID-19, in Colombia, available at https://epidemiologia-matematica.org.
Unsupervised learning for economic risk evaluation in the context of Covid-19 pandemic
Nov 26, 2020

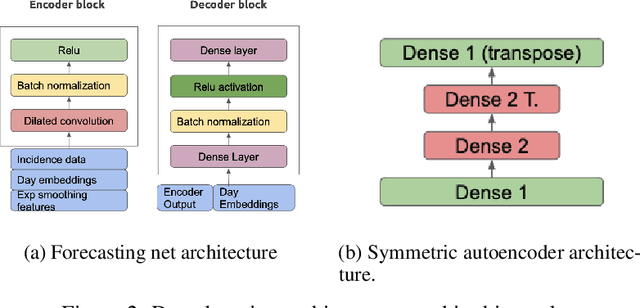
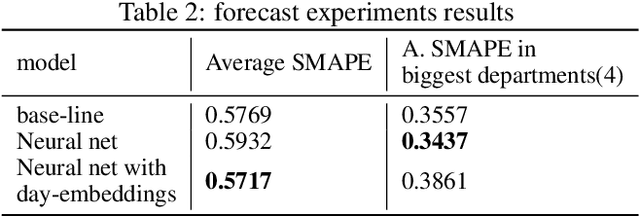
Justifying draconian measures during the Covid-19 pandemic was difficult not only because of the restriction of individual rights, but also because of its economic impact. The objective of this work is to present a machine learning approach to identify regions that should implement similar health policies. For that end, we successfully developed a system that gives a notion of economic impact given the prediction of new incidental cases through unsupervised learning and time series forecasting. This system was built taking into account computational restrictions and low maintenance requirements in order to improve the system's resilience. Finally this system was deployed as part of a web application for simulation and data analysis of COVID-19, in Colombia, available at (https://covid19.dis.eafit.edu.co).
Inertial Odometry on Handheld Smartphones
Jun 07, 2018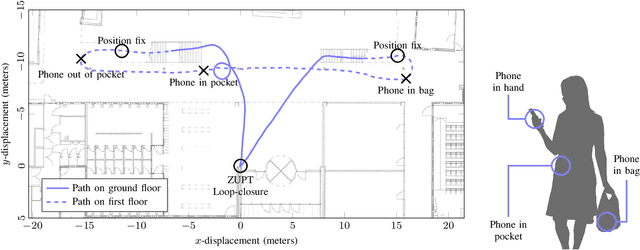


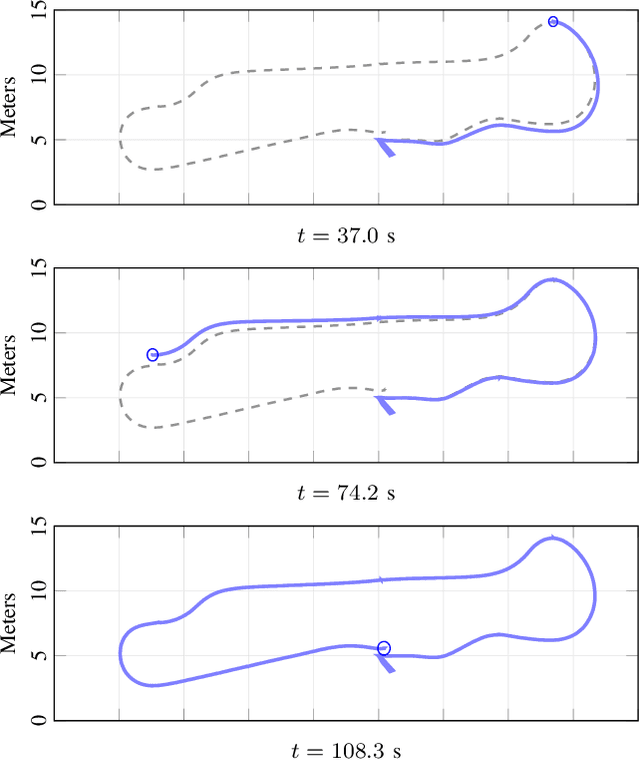
Building a complete inertial navigation system using the limited quality data provided by current smartphones has been regarded challenging, if not impossible. This paper shows that by careful crafting and accounting for the weak information in the sensor samples, smartphones are capable of pure inertial navigation. We present a probabilistic approach for orientation and use-case free inertial odometry, which is based on double-integrating rotated accelerations. The strength of the model is in learning additive and multiplicative IMU biases online. We are able to track the phone position, velocity, and pose in real-time and in a computationally lightweight fashion by solving the inference with an extended Kalman filter. The information fusion is completed with zero-velocity updates (if the phone remains stationary), altitude correction from barometric pressure readings (if available), and pseudo-updates constraining the momentary speed. We demonstrate our approach using an iPad and iPhone in several indoor dead-reckoning applications and in a measurement tool setup.
PIVO: Probabilistic Inertial-Visual Odometry for Occlusion-Robust Navigation
Jan 23, 2018



This paper presents a novel method for visual-inertial odometry. The method is based on an information fusion framework employing low-cost IMU sensors and the monocular camera in a standard smartphone. We formulate a sequential inference scheme, where the IMU drives the dynamical model and the camera frames are used in coupling trailing sequences of augmented poses. The novelty in the model is in taking into account all the cross-terms in the updates, thus propagating the inter-connected uncertainties throughout the model. Stronger coupling between the inertial and visual data sources leads to robustness against occlusion and feature-poor environments. We demonstrate results on data collected with an iPhone and provide comparisons against the Tango device and using the EuRoC data set.