 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasterful: A Training Platform for Computer Vision Models
May 21, 2022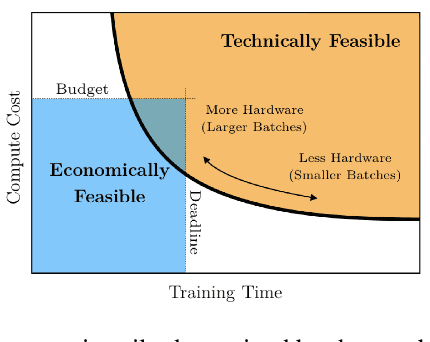
Masterful is a software platform to train deep learning computer vision models. Data and model architecture are inputs to the platform, and the output is a trained model. The platform's primary goal is to maximize a trained model's accuracy, which it achieves through its regularization and semi-supervised learning implementations. The platform's secondary goal is to minimize the amount of manual experimentation typically required to tune training hyperparameters, which it achieves via multiple metalearning algorithms which are custom built to control the platform's regularization and semi-supervised learning implementations. The platform's tertiary goal is to minimize the computing resources required to train a model, which it achieves via another set of metalearning algorithms which are purpose built to control Tensorflow's optimization implementations. The platform builds on top of Tensorflow's data management, architecture, automatic differentiation, and optimization implementations.
The Human Visual System and Adversarial AI
Jan 07, 2020


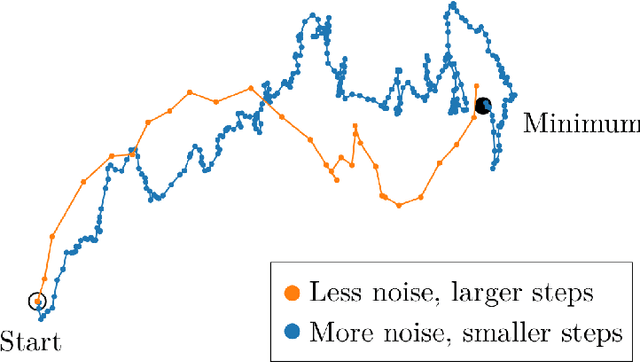
This paper applies theories about the Human Visual System to make Adversarial AI more effective. To date, Adversarial AI has modeled perceptual distances between clean and adversarial examples of images using Lp norms. These norms have the benefit of simple mathematical description and reasonable effectiveness in approximating perceptual distance. However, in prior decades, other areas of image processing have moved beyond simpler models like Mean Squared Error (MSE) towards more complex models that better approximate the Human Visual System (HVS). We demonstrate a proof of concept of incorporating HVS models into Adversarial AI.
The Real-World-Weight Cross-Entropy Loss Function: Modeling the Costs of Mislabeling
Jan 03, 2020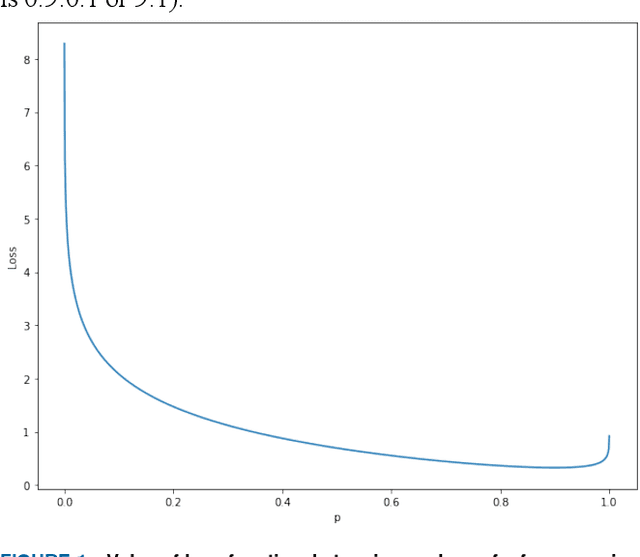
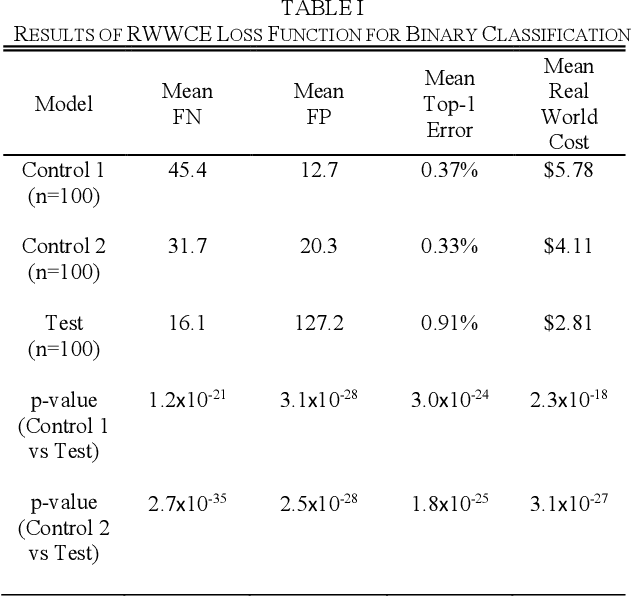
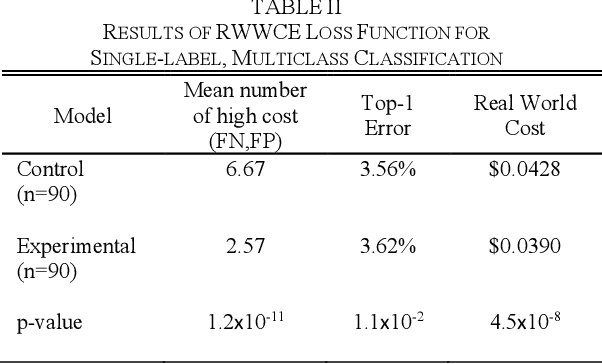
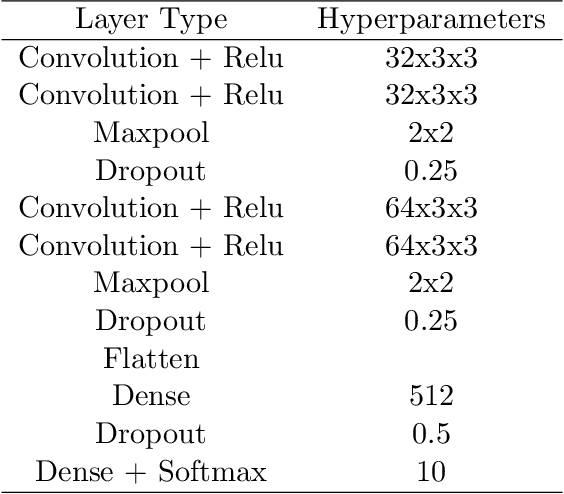
In this paper, we propose a new metric to measure goodness-of-fit for classifiers, the Real World Cost function. This metric factors in information about a real world problem, such as financial impact, that other measures like accuracy or F1 do not. This metric is also more directly interpretable for users. To optimize for this metric, we introduce the Real-World- Weight Crossentropy loss function, in both binary and single-label classification variants. Both variants allow direct input of real world costs as weights. For single-label, multicategory classification, our loss function also allows direct penalization of probabilistic false positives, weighted by label, during the training of a machine learning model. We compare the design of our loss function to the binary crossentropy and categorical crossentropy functions, as well as their weighted variants, to discuss the potential for improvement in handling a variety of known shortcomings of machine learning, ranging from imbalanced classes to medical diagnostic error to reinforcement of social bias. We create scenarios that emulate those issues using the MNIST data set and demonstrate empirical results of our new loss function. Finally, we sketch a proof of this function based on Maximum Likelihood Estimation and discuss future directions.