 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Real-World-Weight Cross-Entropy Loss Function: Modeling the Costs of Mislabeling
Paper and Code
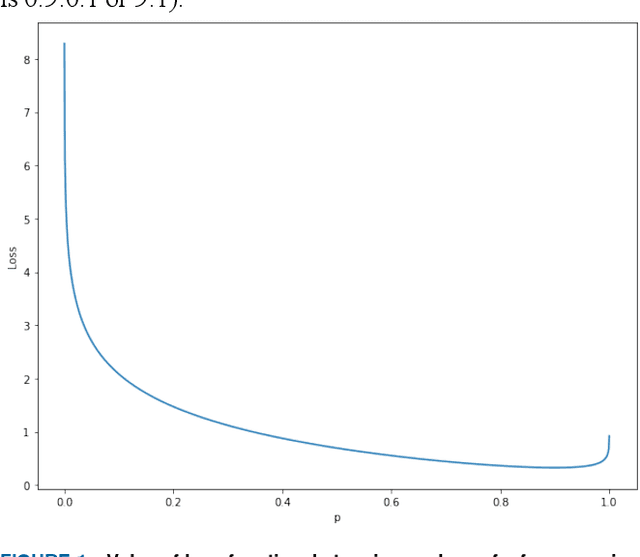
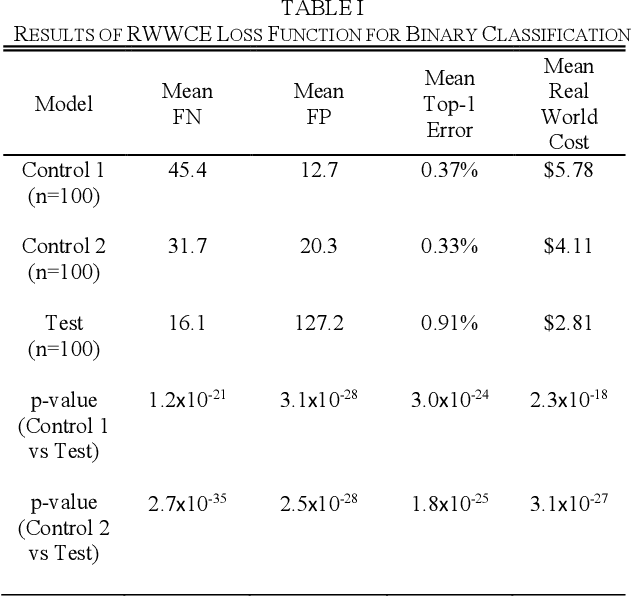
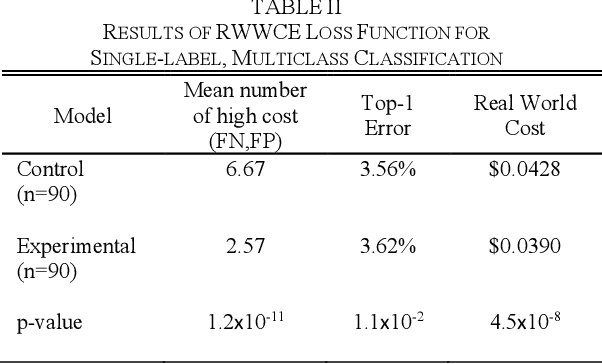
In this paper, we propose a new metric to measure goodness-of-fit for classifiers, the Real World Cost function. This metric factors in information about a real world problem, such as financial impact, that other measures like accuracy or F1 do not. This metric is also more directly interpretable for users. To optimize for this metric, we introduce the Real-World- Weight Crossentropy loss function, in both binary and single-label classification variants. Both variants allow direct input of real world costs as weights. For single-label, multicategory classification, our loss function also allows direct penalization of probabilistic false positives, weighted by label, during the training of a machine learning model. We compare the design of our loss function to the binary crossentropy and categorical crossentropy functions, as well as their weighted variants, to discuss the potential for improvement in handling a variety of known shortcomings of machine learning, ranging from imbalanced classes to medical diagnostic error to reinforcement of social bias. We create scenarios that emulate those issues using the MNIST data set and demonstrate empirical results of our new loss function. Finally, we sketch a proof of this function based on Maximum Likelihood Estimation and discuss future directions.